本文参考主要参考这个网站的内容http://c.biancheng.net/view/3476.html
汇编器识别一组基本的内部数据类型(intrinsic data type),按照数据大小(字节、字、双字等等)、是否有符号、是整数还是实数来描述其类型。
下表给出了全部内部数据类型的列表
数据类型的定义
数据定义语句(data definition statement)在内存中为变量留岀存储空间,并赋予一个可选的名字。数据定义语句根据内部数据类型(上表)定义变量。
[name] directive initializer [,initializer]...
下面是数据定义语句的一个例子:
count DWORD 2400
其中:
名字:分配给变量的可选名字必须遵守标识符规范。
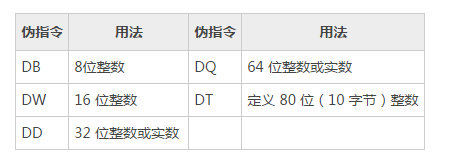
伪指令:数据定义语句中的伪指令可以是 BYTE、WORD、DWORD、SBTYE、SWORD 或其他在上表中列出的类型。此外,它还可以是传统数据定义伪指令,如下表所示
数据定义中至少要有一个初始值,即使该值为 0。其他初始值,如果有的话,用逗号分隔。对整数数据类型而言,初始值(initializer)是整数常量或是与变量类型,如 BYTE 或 WORD 相匹配的整数表达式。
如果程序员希望不对变量进行初始化(随机分配数值),可以用符号 ?作为初始值。所有初始值,不论其格式,都由汇编器转换为二进制数据。 初始值 0011 0010b、32h 和 50d 都具有相同的二进制数值。
下面给出具体例子INSTANCE.asm:
;INSTANCE.asm
.386
.model flat,stdcall
.stack 4096
ExitProcess PROTO, dwExitCode:DWORD
.data
sum DWORD 0
.code
main PROC
mov eax,3
add eax,4
mov sum,eax
INVOKE ExitProcess,0
main ENDP
END main
第一行在;后面表示注释
第 2行是 .386 伪指令,它表示这是一个 32 位程序,能访问 32 位寄存器和地址。
第 3 行选择了程序的内存模式(flat),并确定了子程序的调用规范(称为 stdcall)。其原因是 32 位 Windows 服务要求使用 stdcall 规范。
第 4行为运行时堆栈保留了 4096 字节的存储空间,每个程序都必须有。
第 5 行声明了 ExitProcess 函数的原型,它是一个标准的 Windows 服务。原型包含了函数名、PROTO 关键字、一个逗号,以及一个输入参数列表。ExitProcess 的输入参数名称为 dwExitCode。
可以将其看作为给 Windows 操作系统的返回值,**返回值为零,则表示程序执行成功;**而任何其他的整数值都表示了一个错误代码。因此,程序员可以将自己的汇编程序看作是被操作系统调用的子程序或过程。当程序准备结束时,它就调用 ExitProcess,并向操作系统返回一个整数以表示该程序运行良好。
第6行表示数据区
第7行表示数据变量sum,并初始化为0
第8行.code 伪指令标记一个程序代码区的起点,代码区包含了可执行指令。通常,.CODE 的下一行声明程序的入口,按照惯例,一般会是一个名为 main 的过程。程序的入口是指程序要执行的第一条指令的位置。
后面则是主程序的运算。
定义定义 BYTE 和 SBYTE 数据
BYTE(定义字节)和 SBYTE(定义有符号字节)为一个或多个无符号或有符号数值分配存储空间。每个初始值在存储时,都必须是 8 位的。
问号(?)初始值使得变量未初始化,这意味着在运行时分配数值到该变量:
val BYTE ? ;表示定义了val,但是没有初始化值
初始化多个值
如果同一个数据定义中使用了多个初始值,那么它的标号只指出第一个初始值的偏移量。在下面的例子中,假设 list 的偏移量为 0000。那么,数值 1 的偏移量就为 0000, 2 的偏移量为 0001,3 的偏移量为 0002,4 的偏移量为 0003:
list BYTE 1,2,3,4
并不是所有的数据定义都要用标号。比如,在 list 后面继续添加字节数组,可以按照如下定义:
list BYTE 1,2,3,4
BYTE 5,6,7,8
定义字符串
定义一个字符串,要用单引号或双引号将其括起来。最常见的字符串类型是用一个空字节(值为0)作为结束标记,称为以空字节结束的字符串。如下例子:
string1 BYTE "hello",0
string2 BYTE 'world',0
一个字符串可以分为多行,如下所示:
string1 BYTE "Welcome to the new world of ASM "
BYTE "it sucks",0dh, 0ah
BYTE "but you will love it",0dh,0ah,0
十六进制代码 0Dh 和 0Ah 也被称为 CR/LF (回车换行符)或行结束字符。
定义WORD和SWORD 数据
WORD(定义字)和 SWORD(定义有符号字)伪指令为一个或多个 16 位整数分配存储空间:
world1 WORD 65535 ;最大无符号数
world2 SWORD -32768 ;最小有符号数
word WORD ? ;未初始化,无符号
16 位字数组通过列举元素或使用 DUP 操作符来创建字数组。下面的数组包含了一组数值:
myList WORD 10,20,30,40,50
假设 myList 起始位置偏移量为0000。由于每个数值占两个字节,因此其地址递增量为 2。
定义浮点型数据
REAL4 定义 4 字节单精度浮点变量。REAL8 定义 8 字节双精度数值,REAL10 定义 10 字节扩展精度数值。每个伪指令都需要一个或多个实常数初始值:
rVal1 REAL4 -1.2
rVal2 REAL8 3.2E-260
rVal3 REAL10 4.6E+4096
ShortArray REAL4 20 DUP(0.0)
小端顺序
x86 处理器在内存中按小端(little-endian)顺序(低到高)存放和检索数据。最低有效字节存放在分配给该数据的第一个内存地址中,剩余字节存放在随后的连续内存位置中。考虑一个双字 12345678h。如果将其存放在偏移量为 0000 的位置,则 78h 存放在第一个字节,56h 存放在第二个字节,余下的字节存放地址偏移量为 0002 和 0003。如下图所示:

