RISC-V AI芯片Celerity史上最详细解读(上)(附开源地址)
(本文包括Celerity中二值化神经网络的介绍)

作者 陈巍,资深芯片专家,人工智能算法-硬件协同设计专家。
在Hot Chips 29大会上,基于RISC-V核心的AI芯片Celerity一亮相便引起开源社区的关注。
Celerity的设计展现了两个特点:
1) 设计了基于RISC-V核心的多级(Tier)异构AI加速结构,兼顾计算中灵活性和能耗的要求,在硬件层面直接支持AI计算,实现了更好的功能和更高的能效。
2) 采用了HLS+Chipsel+开源IP的敏捷设计方法提升芯片的设计速度,明显缩短芯片的研发周期到几个月。
该芯片由Michigan大学, Cornell 大学,和 Bespoke Silicon Group(目前属于Washington大学)共同完成。并且该项目受到了DARPA(美国国防高级研究计划局)的资助。Celerity的设计源码已经可以下载。(文末)
Celerity的多级架构
Celerity多级结构组成。(图1)它们分别为通用级(General-Purpose Tier),众核级(Manycore Tier)和专用级( Specialization Tier)。三级之间两两互连。
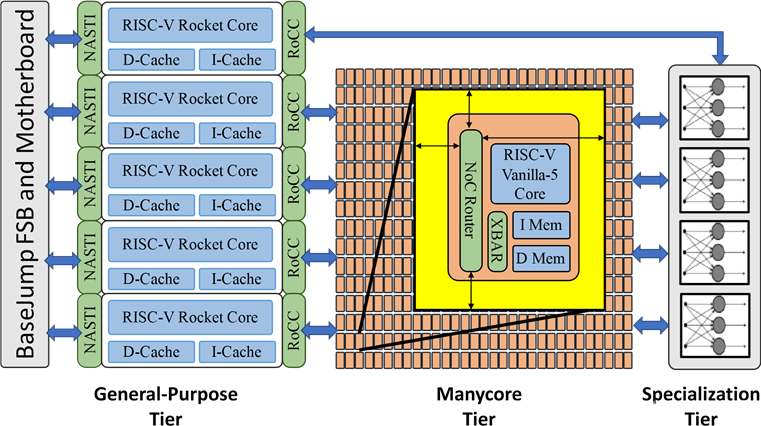
图1 Celerity的多级架构
与FSB和主板连接的是由5个高性能RISC-V Rocket核心组成的通用级。通用级具备完整的计算功能,可以执行各类计算操作以及与内存、I/O和板载芯片的通信。通用级也可用于承载操作系统。通用级的功能多样,能效较低,可运行在625MHz。
通用级后面的众核级由496个低功耗RISC -V Vanilla -5标量处理核心阵列(16x31)组成,负责粗粒度与细粒度的并行计算。这些Vanilla -5处理核心由80Gbps的全双工片上网络(NoC)连接在一起。众核级的功能与能效相对折中。
专用级则由专门用于AI计算的**二值神经网络(Binarized Neural Network,BNN)**核心组成。该BNN核心可直接支持13.4M大小的9层模型(包括一层定点卷积层,6层二值卷积层与2层全连接层)。专用级功能单一,却具有最高的能效。
Manycore Tier与NoC
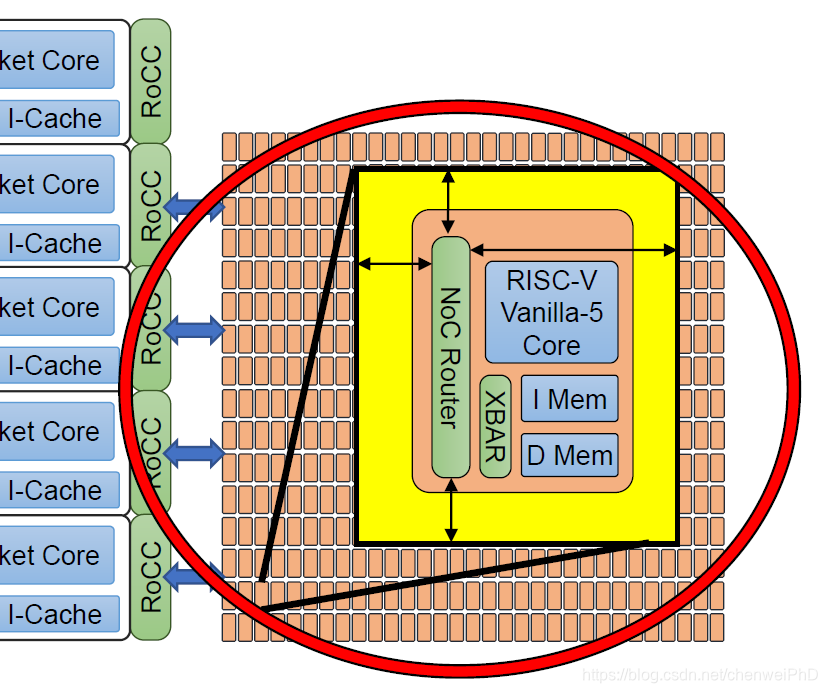
图2 众核级的Vanilla -5标量处理核心阵列
如图2所示,众核级采用了496(16x31)个Vanilla-5版本的RISC-V核心。Vanilla结构简洁易用,可以很高效的执行C语言代码而不用对编译器进行修改。它采用了RV32IM指令集,5级流水线,有序发射。
众核级内部核心通过网格网络(Mesh Network,图7)互联。网格网络的每个节点都是缓冲路由(Buffered Router),按照所在位置确定X/Y坐标编号,并通过前向包与反向包进行全双工连接。缓冲路由间通过特定的连接协议进行通信与数据传输。其中前向连接为80bit位宽,反向连接为10bit位宽。
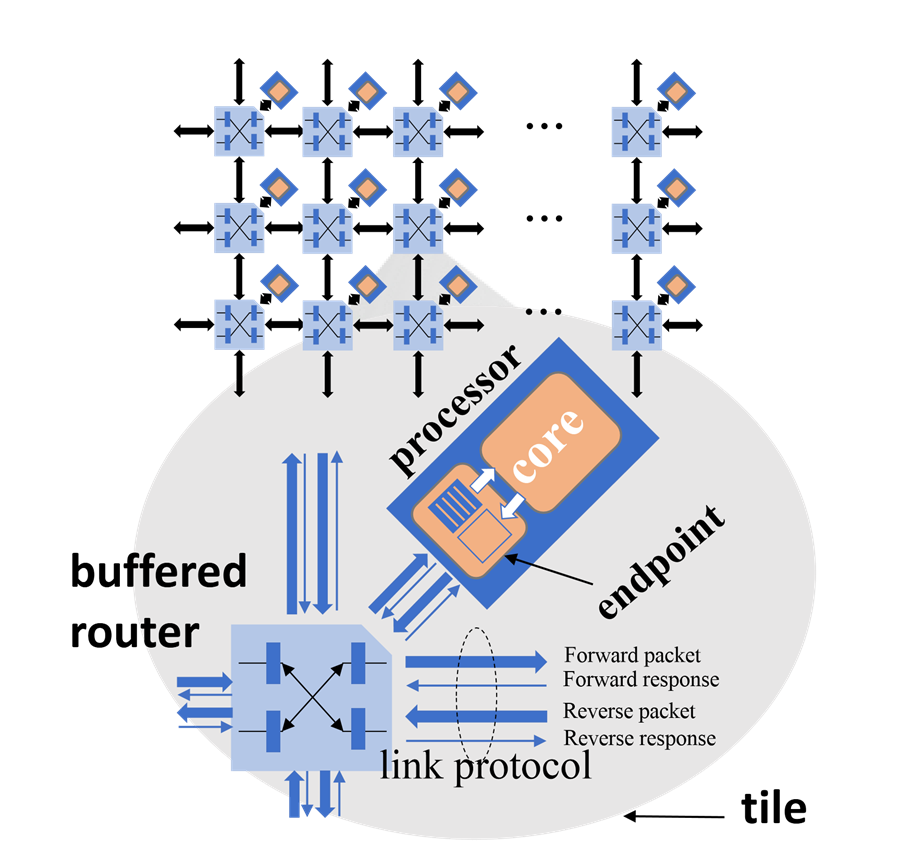
图3 Vanilla-5核心间的网格网络
二值化神经网络(BNN)
Celerity专用级(图1最右侧)集成了二值化神经网络(BNN)加速器。
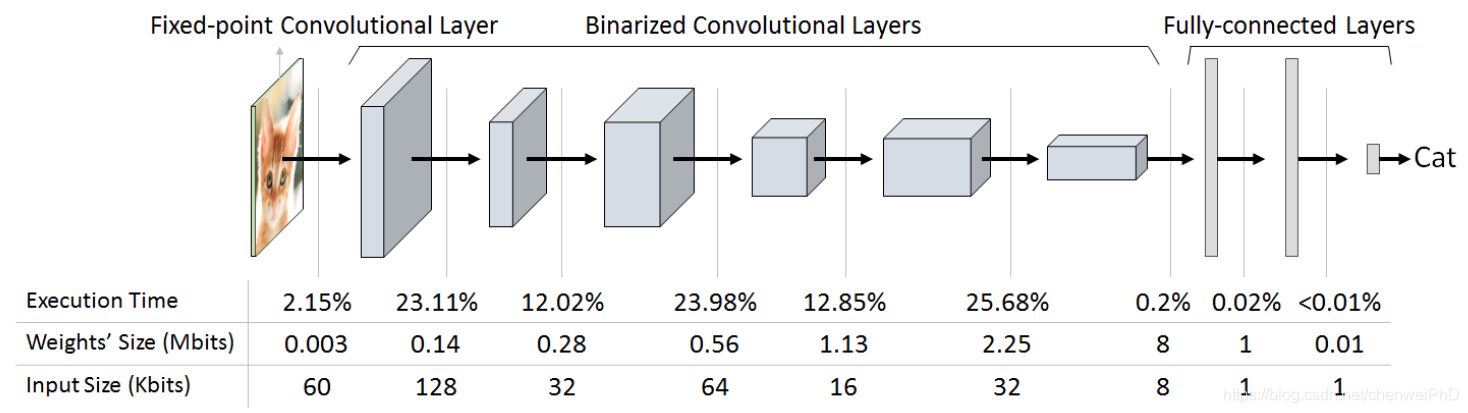
图4 二值化神经网络计算流示意
这一神经网络由1层定点卷积层、6层二值化卷积层和2层全连接层组成。根据文献,这一结构的神经网络在CIFAR-10数据集上可以达到89.8%的精度。可支持13.4M个权值。
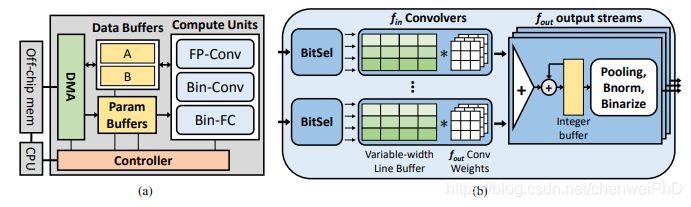
(a)BNN核心的架构 (b) 二值化卷积模块
图5 BNN架构与二值化卷积模块
在二值化卷积的计算过程中,每两个特征图(feature map)分别与3卷积核进行卷积计算,生成累加后的3组下一级特征图。
BNN结构,既可以看作是Celerity芯片的亮点,也可以看作是Celerity不足之处。
Celerity的BNN为什么难以用于实际应用?
Celerity的多级结构瓶颈在哪里?
众核级的问题与应用难点在什么地方?
答案都在本文的下篇之中。
如果你对本文的下篇内容感兴趣,想学习AI芯片的实战知识,并了解Celerity不足在哪里,欢迎加入TensorChip的AI芯片学习阵营。
附录:
Celerity开源地址:http://opencelerity.org/
众核级开源地址: https://bitbucket.org/taylor-bsg/bsg_manycore/src/master/
BNN开源地址: https://github.com/cornell-zhang/bnn-fpga
TensorChip(千芯科技)将联合芯势力科技推出人工智能FPGA开发系列课程,采用线下实训及线上课程方式,为有志于从事人工智能及FPGA开发领域就业及提升的人员提供了学习先进技术的机会,大家可以在这里学习和实践业界最新最先进,同时也是人工智能和芯片开发领域最急需的技术,为自己工作能力打下坚实基础,同时芯势力科技承诺推荐就业。
课程包括:
机器学习及深度学习课程和项目实训
芯算一体的人工智能算法优化技术及实训
异构人工智能芯片和加速芯片设计课程及实训
用Chisel设计RISC-V芯片课程及实训
Verilog设计及FPGA开发课程及实训
欢迎有兴趣的相关专业学生、相关领域开发人员、有定制课程需要的公司或单位,联系芯势力科技,了解课程及详细安排。

关注TensorChip AI芯片与加速技术信息
关于TensorChip
TensorChip(千芯科技)的研发核心团队由来自北美AI巨头、瑞萨与国内的芯片及人工智能领域资深专家组成,致力于国际领先的AI算法-芯片协同设计(算芯协同),聚焦AI算法及芯片系统在应用领域的落地。合作方包括兆易创新、深圳清华大学研究院、新松机器人、四维图新等国内顶尖的技术领跑者。
TensorChip目前正通过定制化合作,协助客户将自有算法在FPGA平台、RISC-V架构、及x86架构产品落地。合作伙伴包括AI芯片企业与AI算法企业。未来,TensorChip会与合作伙伴一起,推出可重构的存算一体芯片方案和对应的算法编译平台,在人工智能批量投产时代提供最具市场竞争力的芯片平台方案。
www.tensorchip.com
