引言
承接上一篇《MySQL 基础 ————高频函数总结》,本篇单独针对分组查询进行简单的总结和归纳,并为后续更为复杂的DQL 语句做好铺垫。
查询语句:
SELECT AVG(salary) FROM teacher;实际上是以全表的 salary 字段来求平均值。但是在实际应用中往往有一些特殊的需求,比如,求每个部门的平均工资。这个时候就需要将表进行分组,然后再进行查询。

上图左边的是 teacher 的整张表,我们通过 lesson (任课科目) 来进行分组,然后再求出每种科目老师的平均工资。
一、GROUP BY 子句
使用 GROUP BY 子句进行数据的分组,能够分为一组的字段,值必须相同。
GROUP BY 子句的位置在 WHERE 查询条件之后,而且一般情况下,GROUP BY 都是处在查询语句偏后的位置。

注意,查询列表,必须出现在 分组函数 或 GROUP BY 子句中。比如,引言中的按照学科分组,查询平均工资:
SELECT AVG(salary) FROM teacher GROUP BY lesson;其中,查询列表就是 salary,因为每组中必有 >= 1 条记录,因此,只有进行聚合计算,才能使结果具有实际意义,因此,要么查询的字段可以放在分组函数中求出特定的值,要么就是该分组字段。
二、案例分析
从案例中,可以总结出一定的规律,即当需求中有出现类似“每个”的字样,且这个字段与该表中记录的关系是一对多的话,就可能用到分组查询。
同时,根据上一节的结论,查询列表必须放在分组函数中,否则不具有意义。因此,我们可以得出,只要查询用到了 GROUP BY 子句,就一定会用到 分组函数。
案例:有如下一张学生分数表,查询出语数外总分最高的分数:


SELECT MAX(chinese_score + math_score + english_score) 最高分 FROM score;![]()
通过另一个SQL进行一下检查,可以看到结果完全正确:
SELECT
chinese_score + math_score + english_score AS 总分,
chinese_score 语文,
math_score 数学,
english_score 英语,
stu_id
FROM
score
ORDER BY 总分 DESC ;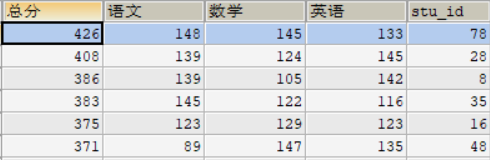
三、HAVING 子句
3.1 HAVING 子句介绍
在分组查询中,往往会涉及到需要先分组,后筛选的情况,与前面简单的先筛选后分组相区分。
比如有这样的需求,“查询 部门中人数 > 2 的部门”。很明显需要分两步来查询,第一步是先通过分组查询出所有部门的人数,如:
SELECT COUNT(*), dept_id
FROM emp
GROUP BY dept_id;然后再在这个结果集中进行筛选,我们可以使用HAVING子句,在GROUP BY 子句后面再加一层筛选条件:
SELECT COUNT(*), dept_id
FROM emp
GROUP BY dept_id
HAVING COUNT(*) > 2;另外,我们也可以通过另一种比较笨重的查询,子查询,结果是一样的:
SELECT
m.人数,
m.dept_id
FROM
(SELECT
COUNT(*) 人数,
dept_id
FROM
emp
GROUP BY dept_id) m
WHERE m.人数 > 3 ;3.2 HAVING子句的使用时机
什么时候使用HAVING子句呢?
当然是在需要进行多步查询的时候,这时会出现一个明确的标志。我们知道,分组查询一定会用到分组函数,那么HAVING 子句的使用一定是由于分组函数上有筛选条件。
比如有这样的需求:查询部门最高工资 > 12000 的部门编号和最高工资。
思路是,首先最高工资是通过聚合函数算出,而在这个聚合函数的结果上又加了一个“ >12000 ” 的筛选条件,因此就会用到HAVING 子句。
思考:如何查询部门最高工资>12000的平均工资?且性能较好。
四、GROUP BY 子句扩展
4.1 按表达式结果分组
group by子句除了支持单个字段进行分组,还支持表达式分组。比如,按照学生名称的长度分组,查询每组学生的个数。
SELECT
COUNT(*),
CHAR_LENGTH(stu_name) 长度
FROM
student
GROUP BY CHAR_LENGTH(stu_name) ;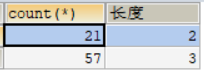
另外,group by 后面支持别名,比如,上面的语句可以改成:
SELECT
COUNT(*),
CHAR_LENGTH(stu_name) 长度
FROM
student
GROUP BY 长度 ;4.2 多字段分组
GROUP BY 同样支持多字段分组,它的含义是在分组的基础上再进行分组。比如需求:先按照工种分组,再按照部门分组:
SELECT
AVG(salary),
department_id,
job_id
FROM
emp
GROUP BY job_id,
department_id ;多字段分组,只需要将各个字段用逗号隔开即可。不过,虽然说分组之上再分组,看似有前后顺序之分,但实际上,分组字段的前后字段不会影响最后结果,可以随意调换。
总结
基本非常重要的结论。
1、GROUP BY 子句一定在 WHERE 条件之后。
2、查询列表,必须出现在 分组函数 或 GROUP BY 子句中。
3、当需求中“每个、每种” 后面的字段可能包含有多条记录的时候,就会用到分组查询,如,每个部门,每个年级,每种食品。
4、只要查询用到了 GROUP BY 子句,就一定会用到 分组函数。
5、若逻辑上的筛选条件在分组之后,可以使用 HAVING 子句,对分组之后的数据进行过滤。
6、GROUP BY 子句支持表达式,支持别名,支持多字段分组,多字段分组用逗号隔开,字段顺序没有影响。
7、常见的分组函数有:COUNT()、AVG()、MAX() 、MIN() 等。
综上,就是关于 分组相关的知识总结。欢迎文末留言和关注。
