1、数据导入
1.1 数据导入
第一种方式:向表中装载数据(Load)
语法
hive> load data [local] inpath '/opt/module/datas/student.txt' overwrite | into table student [partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
操作步骤:
首先,创建一张数据表student5
hive (default)> create table student5(id int, name string)
> row format delimited fields terminated by '\t';
OK
Time taken: 0.114 seconds
hive (default)>
(1)加载本地文件到hive
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/student.txt' into table default.student5;
Loading data to table default.student5
Table default.student4 stats: [numFiles=1, totalSize=39]
OK
Time taken: 0.378 seconds
hive (default)>
(2)加载数据覆盖表中已有的数据
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/student.txt' overwrite into table default.student5;
Loading data to table default.student5
Table default.student5 stats: [numFiles=1, numRows=0, totalSize=39, rawDataSize=0]
OK
Time taken: 0.461 seconds
hive (default)>
之后,再查询这张表,有数据
hive (default)> select * from student5;
OK
student4.id student5.name
1001 zhangshan
1002 lishi
1003 zhaoliu
Time taken: 0.102 seconds, Fetched: 3 row(s)
hive (default)>
接着,再加载一次(加载本地文件到hive)
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/student.txt' into table default.student5;
Loading data to table default.student5
Table default.student5 stats: [numFiles=2, numRows=0, totalSize=78, rawDataSize=0]
OK
Time taken: 0.426 seconds
hive (default)>
之后,再查询这张表,数据有所增加(原本3条,现在6条)
hive (default)> select * from student5;
OK
student5.id student5.name
1001 zhangshan
1002 lishi
1003 zhaoliu
1001 zhangshan
1002 lishi
1003 zhaoliu
Time taken: 0.099 seconds, Fetched: 6 row(s)
hive (default)>
若执行,加载数据覆盖表中已有的数据,(本来6条数据会被覆盖)
hive (default)> load data local inpath '/usr/local/hadoop/module/datas/student.txt' overwrite into table default.student5;
Loading data to table default.student5
Table default.student5 stats: [numFiles=1, numRows=0, totalSize=39, rawDataSize=0]
OK
Time taken: 0.479 seconds
hive (default)>
hive (default)> select * from student5;
OK
student5.id student5.name
1001 zhangshan
1002 lishi
1003 zhaoliu
Time taken: 0.102 seconds, Fetched: 3 row(s)
hive (default)>
接下来,我们需要上传student.txt到HDFS到根目录,执行命令如下:
[root@hadoop101 ~]# cd /usr/local/hadoop/module/datas/
[root@hadoop101 datas]# hadoop fs -put student.txt /
[root@hadoop101 datas]#
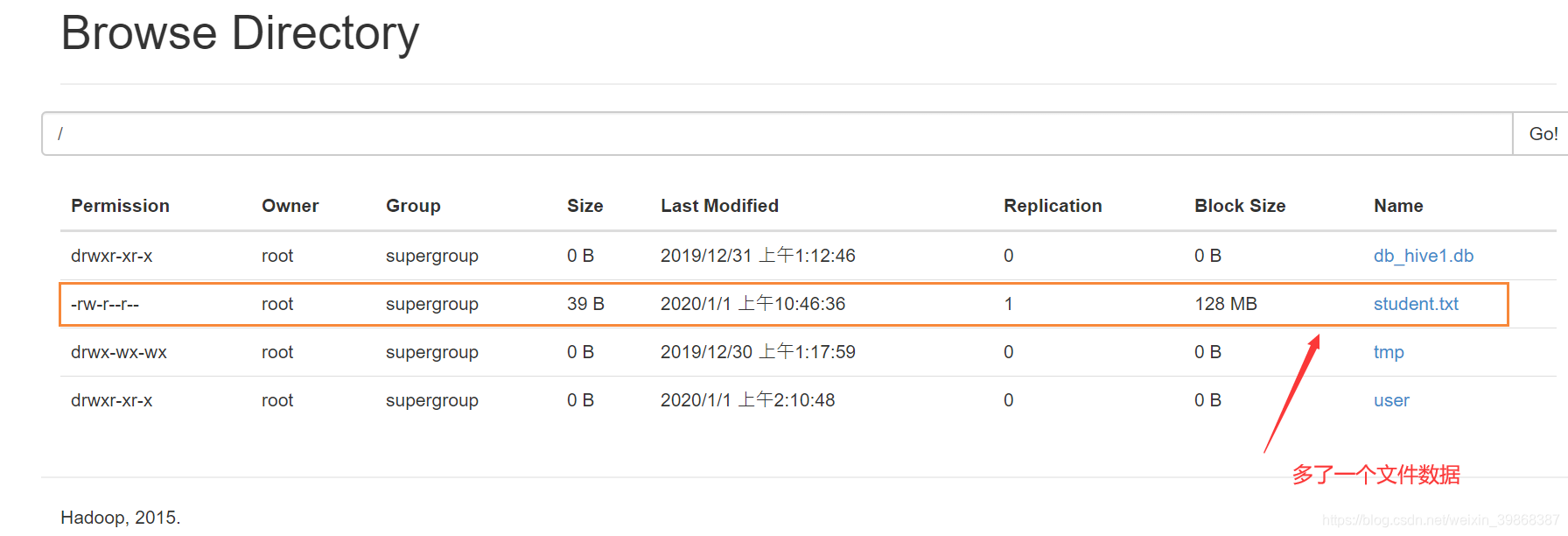
从HDFS的根目录加载本地文件到hive
hive (default)> load data inpath '/student.txt' into table default.student5;
Loading data to table default.student5
Table default.student5 stats: [numFiles=2, numRows=0, totalSize=78, rawDataSize=0]
OK
Time taken: 0.432 seconds
hive (default)>
再查询一下数据信息(从下面得知,又多了3条数据)
hive (default)> select * from student5;
OK
student5.id student5.name
1001 zhangshan
1002 lishi
1003 zhaoliu
1001 zhangshan
1002 lishi
1003 zhaoliu
Time taken: 0.091 seconds, Fetched: 6 row(s)
hive (default)>
原本三条数据,现如今有6条
同时,再HDFS文件系统查看student.txt是否还存在

第二种方式:
通过查询语句向表中插入数据(Insert)
操作步骤:
查看当前的数据表中是否有分区表
hive (default)> show tables;
OK
tab_name
db_hive1
dept
dept_partition2
emp
hive_test
sqoop_test
stu2
stu_partition
student
student1
student3
student4
student5
Time taken: 1.484 seconds, Fetched: 13 row(s)
hive (default)>
hive (default)> desc stu2;
OK
col_name data_type comment
id int
name string
month string
day string
# Partition Information
# col_name data_type comment
month string
day string
Time taken: 0.69 seconds, Fetched: 10 row(s)
hive (default)>
由上,stu2是一个分区表,若没有分区表需要创建,创建sql命令如下:
hive (default)> create table student(id int, name string) partitioned by (month string)
row format delimited fields terminated by '\t';
自己本身有分区表就忽略过了。
接着,需要向分区表(stu2)基本插入数据
hive (default)> insert into table stu2 partition(month='202006',day='26') values(1,'wangwu');
Query ID = root_20200102135829_bda9ac50-448a-4038-b617-33a3d1f448b4
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1577971593473_0001, Tracking URL = http://hadoop101:8088/proxy/application_1577971593473_0001/
Kill Command = /usr/local/hadoop/module/hadoop-2.7.2/bin/hadoop job -kill job_1577971593473_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2020-01-02 13:58:52,919 Stage-1 map = 0%, reduce = 0%
2020-01-02 13:59:05,561 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.8 sec
MapReduce Total cumulative CPU time: 2 seconds 800 msec
Ended Job = job_1577971593473_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hadoop101:9000/user/hive/warehouse/stu2/month=202006/day=26/.hive-staging_hive_2020-01-02_13-58-29_834_7263697218847751236-1/-ext-10000
Loading data to table default.stu2 partition (month=202006, day=26)
Partition default.stu2{month=202006, day=26} stats: [numFiles=1, numRows=1, totalSize=9, rawDataSize=8]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 2.8 sec HDFS Read: 3660 HDFS Write: 97 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 800 msec
OK
_col0 _col1
Time taken: 38.147 seconds
再次查询stu2表
hive (default)> select * from stu2;
OK
stu2.id stu2.name stu2.month stu2.day
1001 zhangshan 202006 23
1002 lishi 202006 23
1003 zhaoliu 202006 23
1 wangwu 202006 26
Time taken: 0.336 seconds, Fetched: 4 row(s)
hive (default)>
允许插入重复的数据
hive (default)> insert into table stu2 partition(month='202006',day='26') values(1,'wangwu');
hive (default)> select * from stu2;
OK
stu2.id stu2.name stu2.month stu2.day
1001 zhangshan 202006 23
1002 lishi 202006 23
1003 zhaoliu 202006 23
1 wangwu 202006 26
1 wangwu 202006 26
Time taken: 0.112 seconds, Fetched: 5 row(s)
hive (default)>
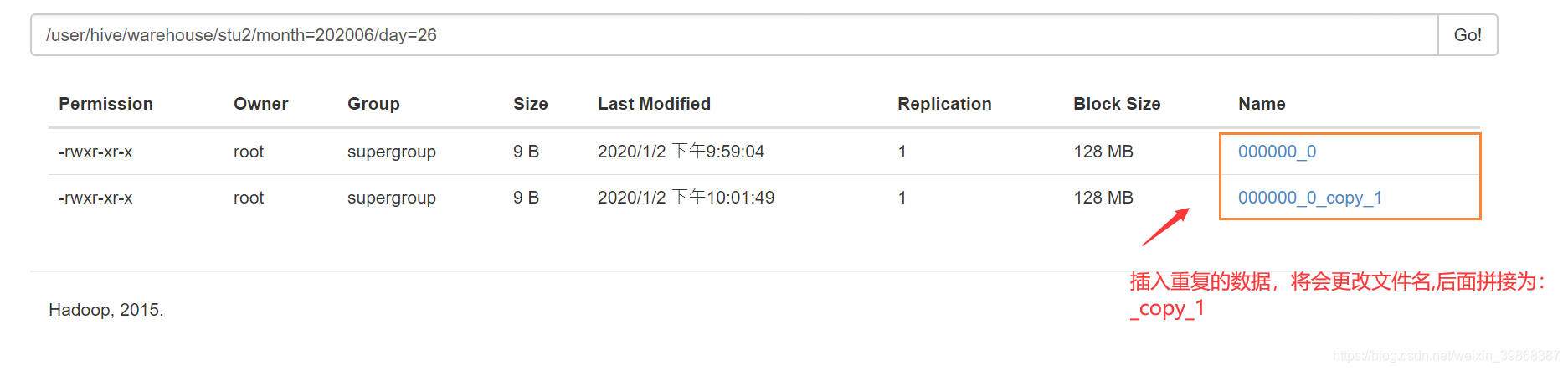
基本模式插入(根据单张表查询结果)
hive (default)> insert into table stu2 partition(month=202006,day=29)
> select * from student;

第三种方式:
查询语句中创建表并加载数据(As Select)
根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student3
as select id, name from student;
第四种方式:
创建表时通过Location指定加载数据路径
(1)创建一张表
hive (default)> create table student2 like student;
OK
Time taken: 0.247 seconds
hive (default)>
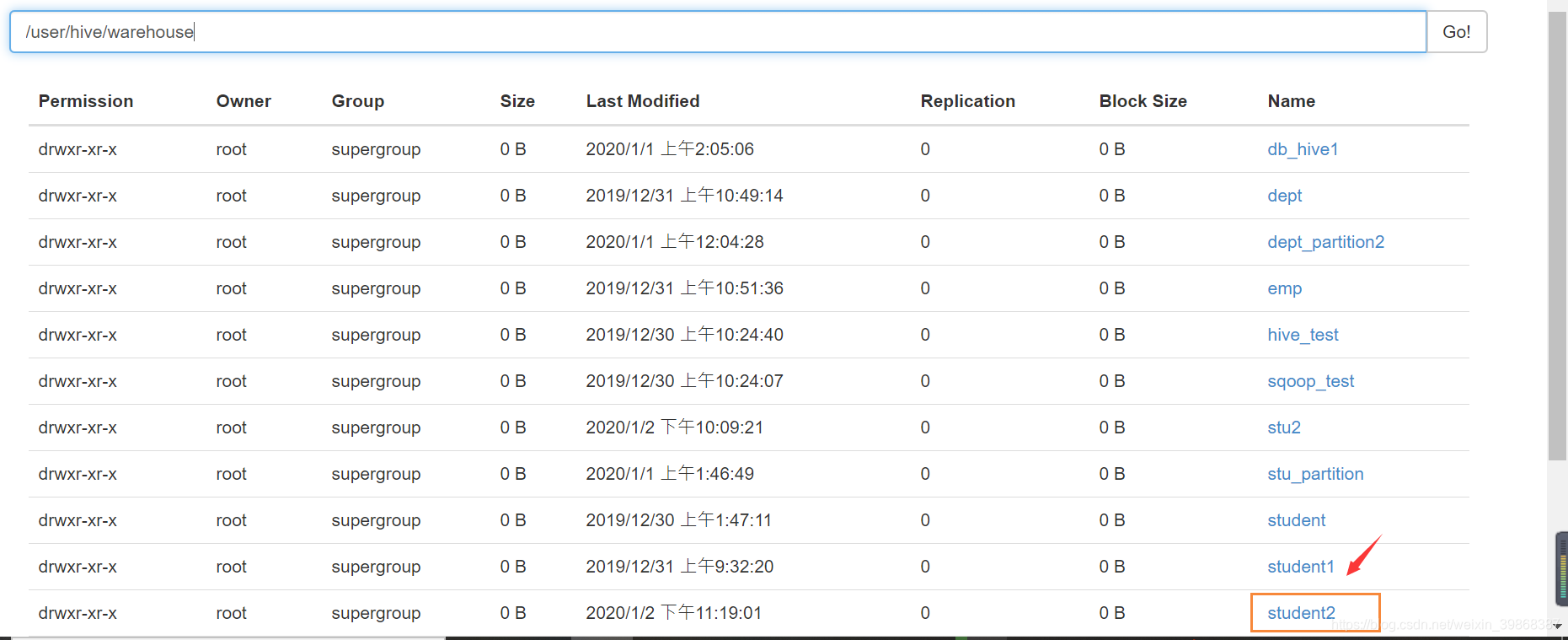
接着,在本地的/usr/local/hadoop/module/datas/student.txt上传到HDFS文件系统到/user/hive/warehouse/student2下
hive (default)> dfs -put /usr/local/hadoop/module/datas/student.txt /user/hive/warehouse/student2 ;

student2这张表是可以查询到数据的
hive (default)> select * from student2;
OK
student2.id student2.name student2.age
1001 zhangshan NULL
1002 lishi NULL
1003 zhaoliu NULL
Time taken: 0.081 seconds, Fetched: 3 row(s)
hive (default)>
接着,在HDFS文件系统的/user目录下创建一个MrZhou文件夹
hive (default)> dfs -mkdir -p /user/MrZhou;
hive (default)>
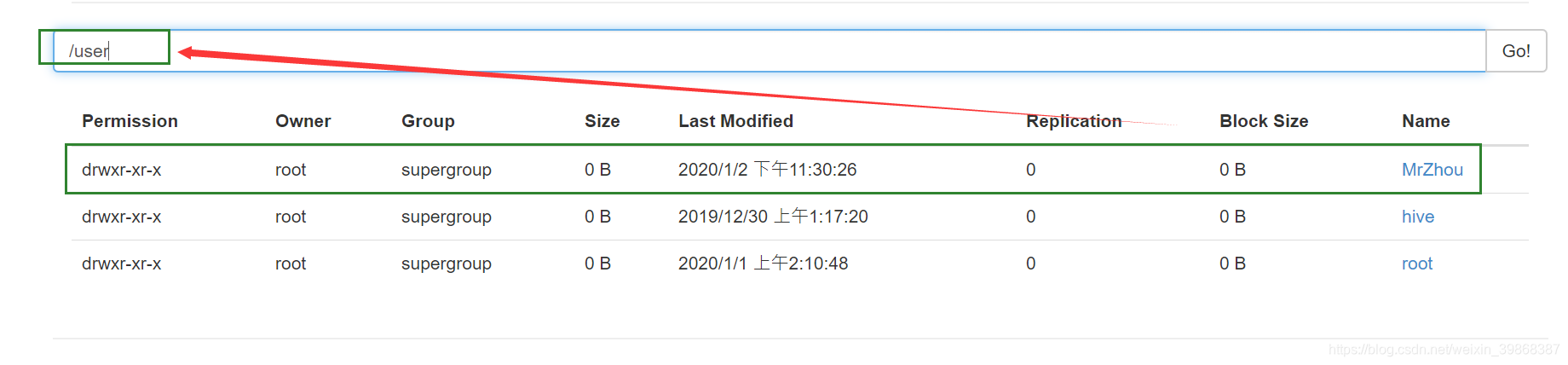
接着,把本地的文件(usr/local/hadoop/module/datas/student.txt)上传到HDFS文件系统(user/MrZhou)文件目录下
hive (default)> dfs -put /usr/local/hadoop/module/datas/student.txt /user/MrZhou;
hive (default)>
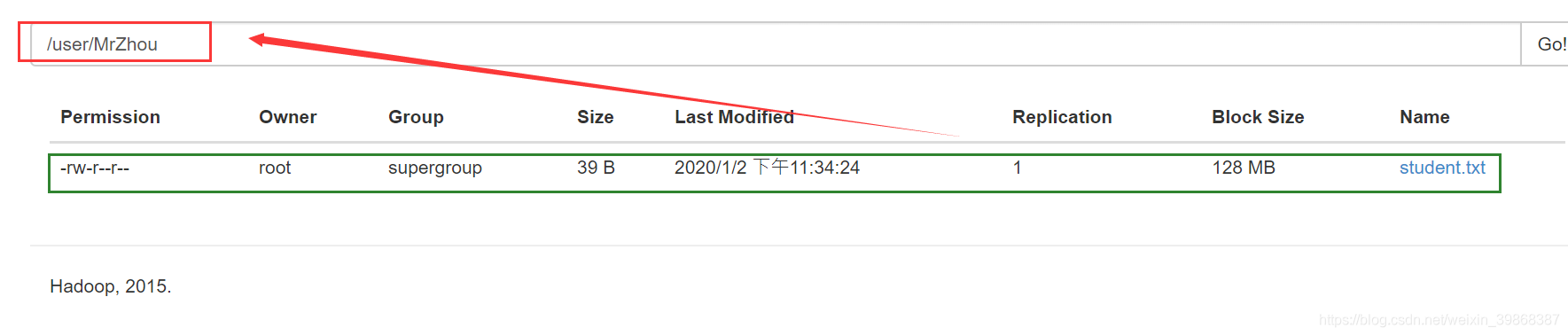
接着,当我们创建一个新数据表,需要指定创建的这个文件路径,后面查询还是可以拿到数据的
hive (default)> create table student6 like student
> location '/user/MrZhou';
OK
Time taken: 0.181 seconds
hive (default)>
hive (default)> select * from student6;
OK
student6.id student6.name student6.age
1001 zhangshan NULL
1002 lishi NULL
1003 zhaoliu NULL
Time taken: 0.118 seconds, Fetched: 3 row(s)
hive (default)>
第5种方式:
Import数据到指定Hive表中
hive (default)> import table student from '/user/MrZhou';
FAILED: SemanticException [Error 10027]: Invalid path
hive (default)>
上述错误说,导入路径不可用
数据导出
(1) Insert导出
将查询的结果导出到本地
hive (default)> insert overwrite local directory '/usr/local/hadoop/module/datas/stu1'
> select * from student;
Query ID = root_20200102224956_684283c4-a161-44d6-883e-b888b0b1e5d7
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1577971593473_0006, Tracking URL = http://hadoop101:8088/proxy/application_1577971593473_0006/
Kill Command = /usr/local/hadoop/module/hadoop-2.7.2/bin/hadoop job -kill job_1577971593473_0006
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2020-01-02 22:50:09,422 Stage-1 map = 0%, reduce = 0%
2020-01-02 22:50:19,536 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.41 sec
MapReduce Total cumulative CPU time: 1 seconds 410 msec
Ended Job = job_1577971593473_0006
Copying data to local directory /usr/local/hadoop/module/datas/stu1
Copying data to local directory /usr/local/hadoop/module/datas/stu1
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.41 sec HDFS Read: 3019 HDFS Write: 48 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 410 msec
OK
student.id student.name student.age
Time taken: 25.608 seconds
hive (default)>
我们在/usr/local/hadoop/module/datas目录查看,多了一个stu1文件夹
[root@hadoop101 datas]# ll
total 24
-rw-r--r-- 1 root root 69 Dec 31 01:59 dept.txt
-rw-r--r-- 1 root root 657 Dec 31 02:07 emp.txt
-rw-r--r-- 1 root root 23 Dec 30 02:42 hivef.sql
-rw-r--r-- 1 root root 54 Dec 30 02:49 hive_result.txt
drwxr-xr-x 3 root root 115 Jan 2 22:50 stu1
-rw-r--r-- 1 root root 39 Dec 29 17:36 student.txt
-rw-r--r-- 1 root root 144 Dec 30 16:21 test.txt
[root@hadoop101 datas]# ls stu1;
000000_0
[root@hadoop101 datas]#
查看000000_0文件
[root@hadoop101 datas]# cat stu1/000000_0
1001zhangshan\N
1002lishi\N
1003zhaoliu\N
[root@hadoop101 datas]#
从上面得知,数据没有格式
将查询的结果格式化导出到本地
hive (default)> insert overwrite local directory '/usr/local/hadoop/module/datas/stu1'
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
> select * from student;
Query ID = root_20200102230048_66acb502-cc9a-4ff3-8a97-c325930eba6b
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1577971593473_0007, Tracking URL = http://hadoop101:8088/proxy/application_1577971593473_0007/
Kill Command = /usr/local/hadoop/module/hadoop-2.7.2/bin/hadoop job -kill job_1577971593473_0007
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2020-01-02 23:01:00,277 Stage-1 map = 0%, reduce = 0%
2020-01-02 23:01:09,973 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.43 sec
MapReduce Total cumulative CPU time: 1 seconds 430 msec
Ended Job = job_1577971593473_0007
Copying data to local directory /usr/local/hadoop/module/datas/stu1
Copying data to local directory /usr/local/hadoop/module/datas/stu1
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.43 sec HDFS Read: 3102 HDFS Write: 48 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 430 msec
OK
student.id student.name student.age
Time taken: 22.805 seconds
hive (default)>
我们还是在/usr/local/hadoop/module/datas目录查看,还是个stu1文件夹,stu1文件夹下的文件名还是000000_0
[root@hadoop101 datas]# ls stu1;
000000_0
[root@hadoop101 datas]# cat stu1/000000_0
1001 zhangshan \N
1002 lishi \N
1003 zhaoliu \N
[root@hadoop101 datas]#
主要是格式发生改变
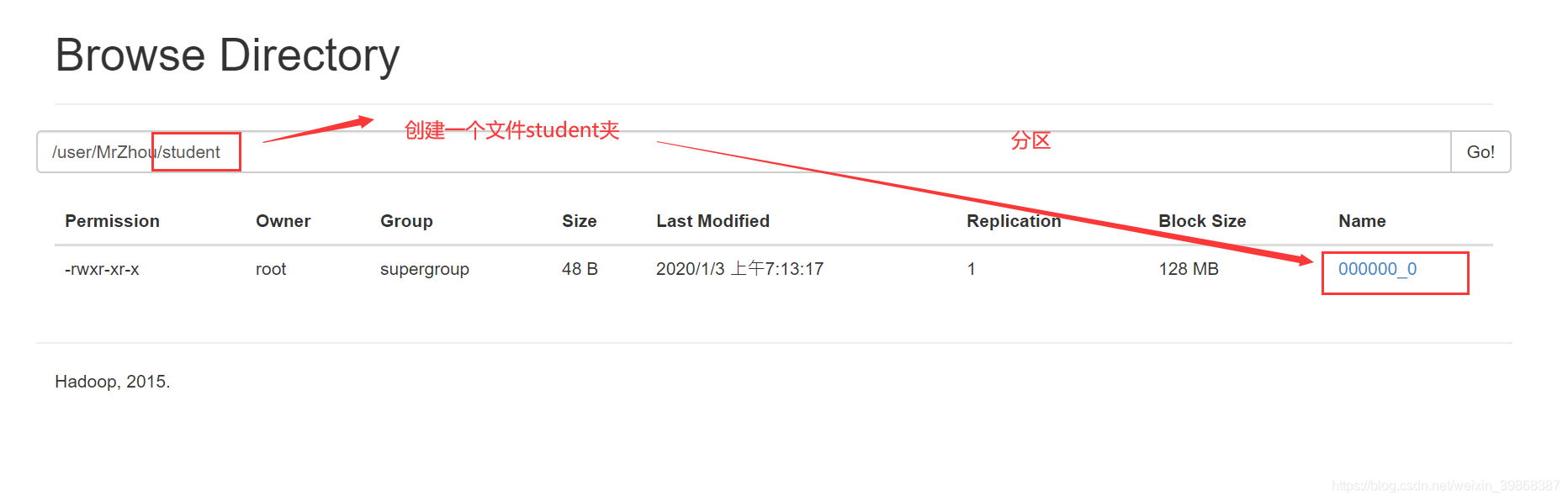
将查询的结果导出到HDFS上(没有local)
hive (default)> insert overwrite directory '/user/MrZhou/student'
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
> select * from student;
Query ID = root_20200102231254_d1e857f4-01c6-491e-bf65-32abba3a7092
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1577971593473_0008, Tracking URL = http://hadoop101:8088/proxy/application_1577971593473_0008/
Kill Command = /usr/local/hadoop/module/hadoop-2.7.2/bin/hadoop job -kill job_1577971593473_0008
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2020-01-02 23:13:06,802 Stage-1 map = 0%, reduce = 0%
2020-01-02 23:13:16,473 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.8 sec
MapReduce Total cumulative CPU time: 1 seconds 800 msec
Ended Job = job_1577971593473_0008
Stage-3 is selected by condition resolver.
Stage-2 is filtered out by condition resolver.
Stage-4 is filtered out by condition resolver.
Moving data to: hdfs://hadoop101:9000/user/MrZhou/student/.hive-staging_hive_2020-01-02_23-12-54_968_2823409006805237170-1/-ext-10000
Moving data to: /user/MrZhou/student
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.8 sec HDFS Read: 3070 HDFS Write: 48 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 800 msec
OK
student.id student.name student.age
Time taken: 22.704 seconds
hive (default)>
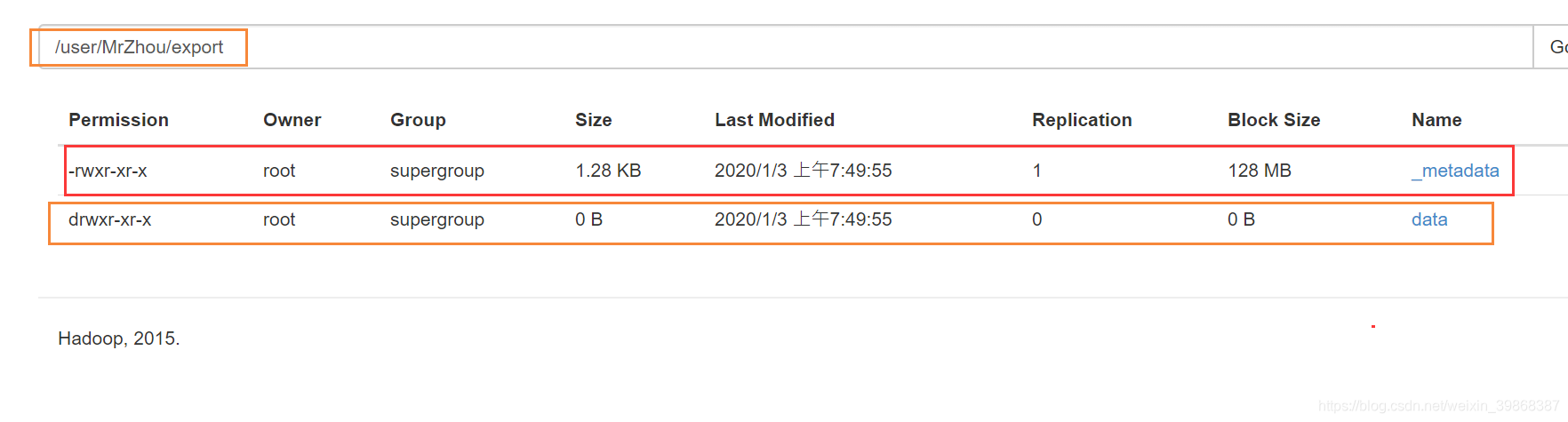
Export导出到HDFS上
hive (default)> export table student
> to '/user/MrZhou/export';
Copying data from file:/tmp/root/12bc47b9-ed69-4c2e-95ea-2b1f311ac691/hive_2020-01-02_23-49-54_403_711547950453122729-1/-local-10000/_metadata
Copying file: file:/tmp/root/12bc47b9-ed69-4c2e-95ea-2b1f311ac691/hive_2020-01-02_23-49-54_403_711547950453122729-1/-local-10000/_metadata
Copying data from hdfs://hadoop101:9000/user/hive/warehouse/student
Copying file: hdfs://hadoop101:9000/user/hive/warehouse/student/student.txt
OK
Time taken: 0.933 seconds
hive (default)>

Import数据到指定Hive表中
hive (default)> import table student7 from
> '/user/MrZhou/export';
Copying data from hdfs://hadoop101:9000/user/MrZhou/export/data
Copying file: hdfs://hadoop101:9000/user/MrZhou/export/data/student.txt
Loading data to table default.student7
OK
Time taken: 0.655 seconds
hive (default)>
注意:student7 是一个自定义的新表,没有被创建过的

清除表中数据(Truncate)
注意:Truncate只能删除管理表,不能删除外部表中数据
操作步骤:
首先查看student5表是否有数据
hive (default)> select * from student5;
OK
student5.id student5.name
1001 zhangshan
1002 lishi
1003 zhaoliu
1001 zhangshan
1002 lishi
1003 zhaoliu
Time taken: 0.114 seconds, Fetched: 6 row(s)
hive (default)>
显示是有数据,接下来做清空表操作,执行命令:
hive (default)> truncate table student5;
OK
Time taken: 0.147 seconds
hive (default)>
再次查看student5表是否有数据
hive (default)> select * from student5;
OK
student5.id student5.name
Time taken: 0.107 seconds
hive (default)>
显然,已经没有数据了
接着,查看当前的数据表
hive (default)> show tables;
OK
tab_name
db_hive1
dept
dept_partition2
emp
hive_test
sqoop_test
stu2
stu_partition
student
student1
student2
student3
student4
student5
student6
student7
values__tmp__table__1
values__tmp__table__2
Time taken: 0.049 seconds, Fetched: 18 row(s)
hive (default)>
若,我们清空dept表,会提示错误,由于**dept是外部表**
hive (default)> truncate table dept;
FAILED: SemanticException [Error 10146]: Cannot truncate non-managed table dept.
外部表( EXTERNAL_TABLE )不能清空
查看一个表是否是内部表还是外部表
hive (default)> desc formatted dept;
Table Type: EXTERNAL_TABLE
