Hadoop系列文章 Hadoop部署

Hadoop分为三种部署方式
- Standalone Operation(单节点集群):默认情况下,Hadoop被配置为作为单个Java进程以非分布式模式运行。这对于调试非常有用。
- Pseudo-Distributed Operation(伪分布式):在单节点上以伪分布式模式运行,其中每个Hadoop守护进程运行在单独的Java进程中。
- 分布式部署Fully-Distributed Operation:真集群部署
| 构件 | 版本 |
|---|---|
| Hadoop | 3.2.1 |
| CentOS | 7 |
| Java | 1.8 |
| IDEA | 2018.3 |
| Gradle | 4.8 |
| Springboot | 2.1.2 RELEASE |
Apache Hadoop 3.2.1 单节点部署
Java安装
因为Hadoop是基于Java的,所以一个Java环境是不能少的。
CentOS7 安装JDK1.8
下载安装包
Apache Hadoop 3.2.1 binary 下载地址
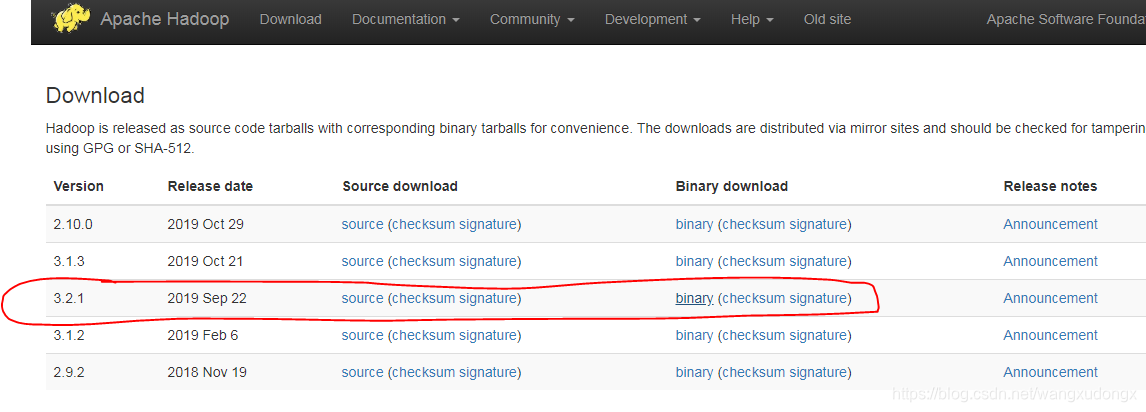
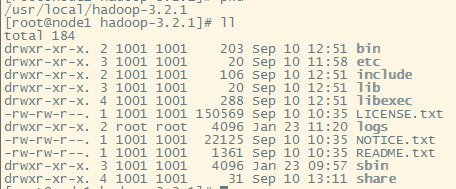
在服务器中解压到指定目录
一般我们将Hadoop放到/usr/local/目录下
# tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local/hadoop-3.2.1
配置环境变量
配置文件/etc/profile
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/usr/local/hadoop-3.2.1/
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

HDFS Shell命令一览

hadoop fs … 与 hdfs dfs …命令作用一样的,因为它们在shell里被翻译成同一个命令。
测试Hadoop安装成果
$ mkdir input
$ cp etc/hadoop/*.xml input
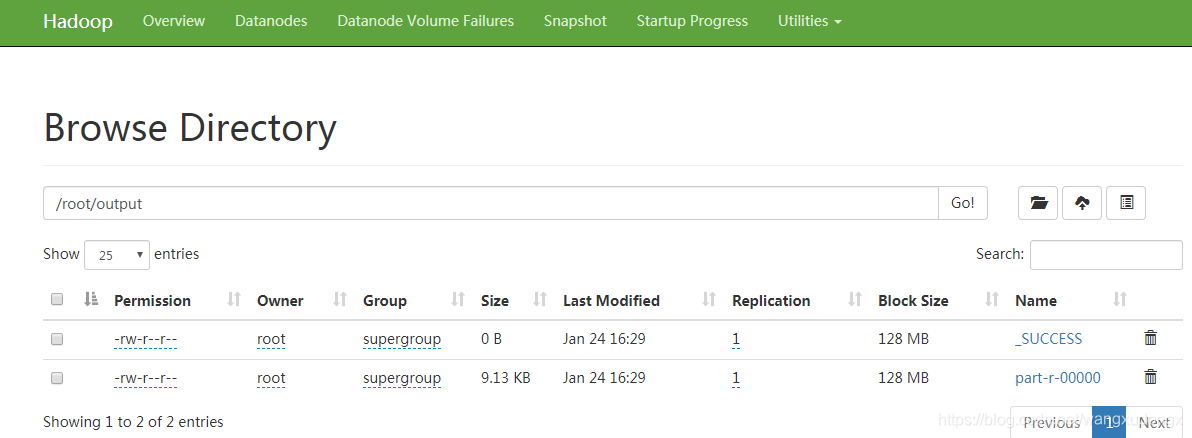
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
$ cat output/*
Apache Hadoop 3.2.1 伪分布式部署
hadoop环境配置文件
修改配置文件hadoop-env.sh
大概54行的位置
export JAVA_HOME=/usr/java/default
配置文件设置
配置文件etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<!-- 将localhost换为自己主机的IP,不然此Hadoop将不能被另外的计算机访问
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.84.132:9000</value>
</property>
-->
</property>
</configuration>
配置文件etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
设置SSH
Setup passphraseless ssh
Now check that you can ssh to the localhost without a passphrase:
$ ssh localhost
If you cannot ssh to localhost without a passphrase, execute the following commands:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
格式化HDFS
Execution
The following instructions are to run a MapReduce job locally. If you want to execute a job on YARN, see YARN on Single Node.
Format the filesystem:
$ bin/hdfs namenode -format
Start NameNode daemon and DataNode daemon:
$ sbin/start-dfs.sh
The hadoop daemon log output is written to the $HADOOP_LOG_DIR directory (defaults to $HADOOP_HOME/logs).
dfs的启动时间比较长,大家要耐心。
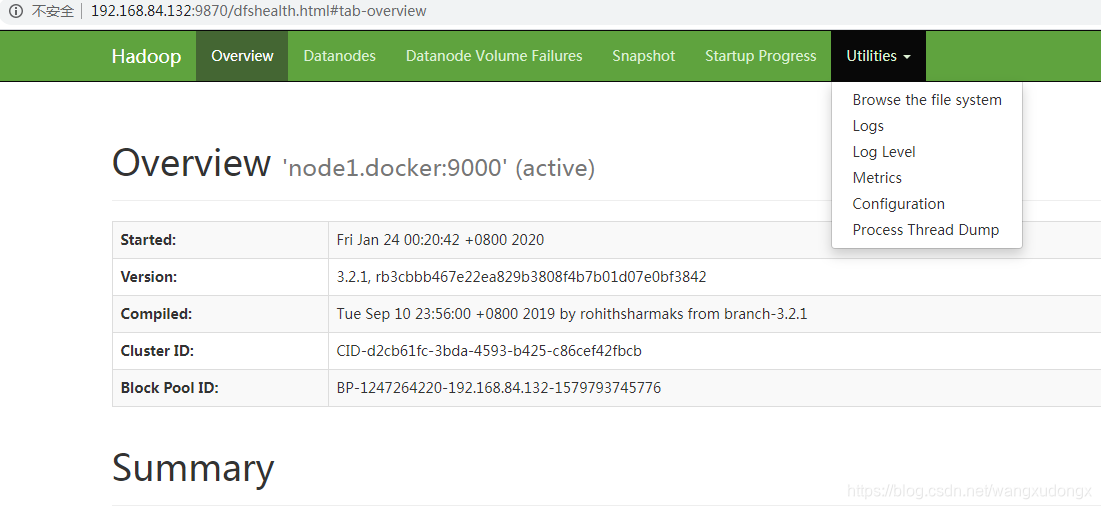
启动完毕之后,可以先访问Hadoop的web控制台http://192.168.84.132:9870/dfshealth.html#tab-overview