学习总结
学习内容
课程内容
- 第三课
- 数组
- 链表
- 跳表
- 第四课
- 栈
- 队列
知识点总结
数组
数组用一块连续的内存空间,来存储相同类型的一组数据。
支持随机访问,时间复杂度 O(1)
插入、删除操作比较低效,为了满足连续空间需要进行数据的搬移,平均情况时间复杂度为O(n)
链表
链表内存空间可以不连续
链表类型有:单链表、双向链表、循环链表、双向循环链表等
更适合插入、删除操作频繁的场景,时间复杂度 O(1)
但是访问时需要遍历链表 ,平均情况时间复杂度为O(n)
某些情况下双向链表的访问比单链表更高效,如指定访问某个节点前面的节点
为了提高访问效率,用空间换时间的设计思路出现跳表
跳表
通过空间换时间,构建多级索引来提高查询的效率,实现了基于链表的“二分查找”
是一种动态数据结构,支持快速的插入、删除、查找操作,时间复杂度为O(nlogn)
栈
栈是一种受限的数据结构,只支持入栈和出栈操作,其入栈、出栈时间复杂度为O(1)。特点是先入后出。
队列
特点是先入先出,常见 有 优先队列,双端队列
关于迭代和递归的一些总结
个人理解如果不同意见欢迎探讨,如果错误欢迎指正
迭代和递归都是要找到其重复处理单元,不同的地方是
迭代:思路是从前向后,大多数情况下使用哨兵节点能简化处理流程
递归:思路是从后向前,仅关注当前层和下一层,重复操作就不要向下考虑太多不然容易晕
递归
先找重复处理单元,再找递归终止条件,解决了这两个问题就很好处理了
就链表处理,我将递归相关题目归纳为以下几点:
- 先找重复处理单元
- 递归终止条件
- 递归前处理(递归到下一层前处理):
- 递归(递归到下一层):
- 递归后处理(下一层递归返回后处理)
具体可以参看下面的例子
迭代
同样先找重复处理单元,再找迭代终止条件
就链表处理,我将迭代相关题目归纳为以下几点:
- 先找重复处理单元
- 迭代终止条件
- 迭代前处理
- 迭代处理
- 迭代后处理
具体可以参看下面的例子
例子
例子 24. 两两交换链表中的节点
递归实现
#@author:leacoder
#@des: 递归实现 两两交换链表中的节点
'''
重复处理单元:
两两交换
链表可以分为 待处理 + 当前层正处理(两两交换的两个节点) + 下层递归已处理
下一层递归返回已处理头结点
当前层就知道: 需要交换的 a、b 两节点 以及 后续已处理头节点
递归终止条件:
head.next 为 None
可以将 head 为 None 的特殊情况一起做判断
if not head or not head.next:
return head
递归前处理(递归到下一层前处理):
这里两两交换链表中的节点 , 下一次递归从 下 两个的结点开始 题 25. K 个一组翻转链表 则另一种处理
可以记录下 当前的 next
next = head.next
递归(递归到下一层):
下两位,使用递归前处理的 next
p = swapPairs(next.next) 题 25. K 个一组翻转链表 则 会有不同
递归后处理(下层递归返回后处理):
1->2->3->4
2->1->4->3
'''
class Solution:
def swapPairs(self, head: ListNode) -> ListNode:
# 递归终止条件:
if not head or not head.next:
return head
# 递归前处理(递归到下一层前处理):
# 当前层 需交换节点 为 head (a) 、head.next (b)
next = head.next
# 递归(递归到下一层):
resultmp = self.swapPairs(next.next) # 下移两位 返回值为两两交换后 两个节点中的前一个节点
# 递归后处理(下层递归返回后处理):
head.next = resultmp # 两两交换
next.next = head # 两两交换
''' 语法糖
head.next, next.next = self.swapPairs(next.next), head
'''
return next # 返回 两两交换后 两个节点中的前一个节点
迭代实现
#@author:leacoder
#@des: 迭代实现 两两交换链表中的节点
'''
利用哨兵简化操作
1->2->3->4
2->1->4->3
重复处理单元:
两两交换
链表可以分为 已处理 + 正处理(两两交换的两个节点) + 后续迭代待处理
迭代终止条件:
两两交换,迭代处理这两个节点,那么后续节点不足两个时跳出迭代
prev.next ,prev.next.next 为 None
迭代前处理:
利用哨兵简化操作,添加哨兵节点 prev
最终结果 以 2->1->4->3 为例 其头节点为 2
由于两两交换 prev 也会跟随下移,先 用 retult = prev 记录prev下移前的值用于最终结果返回
迭代处理:
1->2->3->4 为例
将需要翻转操作的两个节点记录(要断开连接,先记录)
a = prev.next (1)
b = prev.next.next (2)
交换两节点
prev 节点下移,迭代开始新一轮处理 (由于两两交换,跳过两个节点)
迭代后处理:
无特殊处理
'''
class Solution:
def swapPairs(self, head: ListNode) -> ListNode:
# 迭代前处理:
prev = ListNode(None) # 哨兵
prev.next = head
retult = prev # 记录 第一次被操作前的prev 用于返回结果
# 迭代终止条件 prev.next ,prev.next.next 为 None
while prev.next and prev.next.next:
# 迭代处理:
# 以 1 2 反转为例,prev为哨兵
a = prev.next # 由于 要操作 prev.next (1) 和 prev.next.next (2) 先记录下来
b = prev.next.next # 记录 要交换的两节点
prev.next = b # (2)
a.next = b.next # (3)
b.next = a # (1)
prev = a # (1) # 向下移动2位
''' 使用语法糖
prev.next,a.next,b.next= b,b.next,a # 2个节点交换,注意哨兵的next改变了
prev = a # 向下移动2位
'''
# 迭代后处理 无
return retult.next
例子 25. K 个一组翻转链表
递归实现
#@author:leacoder
#@des: 递归实现 k个一组翻转链表
'''
重复处理单元:
k个一组翻转
链表可以分为 : 待处理 + 当前层正处理(k个一组链表) + 下层递归已处理
下一层递归返回已处理头结点
当前层就知道: 需要翻转k个一组链表的链表头、链表尾
链表头 head 参数
链表尾 遍历 k 个节点
递归终止条件:
后续迭代待处理剩余节点不足 k 个
递归前处理(递归到下一层前处理):
k个一组翻转链表,下一次递归从 下 k 个节点开始
记录 翻转前的 链表头 链表尾
递归(递归到下一层):
下k位,使用递归前处理的 链表尾.next
递归后处理(下层递归返回后处理):
将下一层递归返回结果加入到原链表
K 个一组链表翻转,
'''
class Solution:
def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
# 用于记录 翻转前的 链表头 链表尾
end = head
count = 0
# 递归终止条件
while end and count!= k:
end = end.next
count += 1
if count == k: # 递归终止条件
# 递归前处理(递归到下一层前处理)
# 记录 翻转前的 链表头 head 链表尾 end 在前面已做
# 递归(递归到下一层):
resultmp = self.reverseKGroup(end,k) # 下层 已处理头结点
# 递归后处理(下层递归返回后处理)
while count: # K 个一组链表翻转,
tmp = head.next
head.next = resultmp # 将下一层递归返回结果加入到原链表
resultmp = head
head = tmp
count -= 1
head = resultmp # 翻转后链表头
return head
迭代实现
#@author:leacoder
#@des: 迭代实现 k个一组翻转链表
'''
利用哨兵简化操作
prev = ListNode(None) # 哨兵
prev.next = head
prev 每次迭代下移(下移位数为k)
重复处理单元:
k个一组翻转
链表可以分为 :已处理 + 正处理(k个一组链表) + 后续迭代待处理
正处理(k个一组链表)需要知道 链表头和链表尾
链表头 可以通过 prev 的 next 获取
链表尾 需要遍历k个节点获取
迭代终止条件:
后续迭代待处理剩余节点不足 k 个
迭代前处理:
result 记录 prev 下移前的值 用于 结果返回
end 参数 记录尾节点
prev、end 每次迭代指向同一节点
迭代处理:
遍历k个节点获取 链表尾
构建 k个一组链表 并进行翻转 reverse()
reverse() 翻转函数返回 翻转后新链表头
将翻转后新链接入原链表
prev 下移 end 下移
迭代后处理:
无
'''
class Solution:
def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
# 迭代前处理:
prev = ListNode(None) # 哨兵
prev.next = head
result = prev
end = prev # end 记录 k个一组链表 链表尾 prev.next 记录 k个一组链表 链表头
# 迭代终止条件:
while(end.next): # 剩余节点不足 k 个
for i in range(k): # 遍历k个节点获取 链表尾 并 判断 剩余节点 是否不足 k 个
if not end: # 不足 k 个
break
end = end.next
if not end: # 不足 k 个
break
'''
start = prev.next # k个一组链表 链表头
next = end.next # 记录 原 end.next
end.next = None # k个一组链表 链表尾
'''
# 构建 k个一组的链表
start, next, end.next = prev.next, end.next, None
# 翻转 k个一组的链表
prev.next = self.reverse(start) # 返回 翻转后新链表头 接入原链表
start.next = next # 接入原链表 start 为 翻转后新链表尾
prev = start
end = start
return result.next
def reverse(self, head: ListNode):
prev = None
curr = head
while(curr):
'''
tmp = curr.next
curr.next = prev
prev = curr
curr = tmp
'''
curr.next, prev, curr = prev, curr, curr.next
return prev
课后作业 改写Deque的代码
课程中示例代码-Deque
代码
import java.util.LinkedList;
import java.util.Deque;
public class DequeExample {
public static void main(String[] args) {
Deque<String> deque = new LinkedList<String>();
deque.push("a");
deque.push("b");
deque.push("c");
System.out.println(deque);
String str = deque.peek();
System.out.println(str);
System.out.println(deque);
while (deque.size() > 0) {
System.out.println(deque.pop());
}
System.out.println(deque);
}
}
输出:
[c, b, a]
c
[c, b, a]
c
b
a
[]
接口说明
push
public void push(E e)
Pushes an element onto the stack represented by this list. In other words, inserts the element at the front of this list.
This method is equivalent to addFirst(E).
将元素压入此列表表示的堆栈中。换句话说,将元素插入此列表的前面。
此方法等效于addFirst(E)
pop
public E pop()
Pops an element from the stack represented by this list. In other words, removes and returns the first element of this list.
This method is equivalent to removeFirst().
从此列表表示的堆栈中弹出一个元素。换句话说,删除并返回此列表的第一个元素。
此方法等效于equivalent to removeFirst().
peek
public E peek()
Retrieves, but does not remove, the head (first element) of this list.
检索但不删除此列表的头(第一个元素)。
addFirst 改写 Deque 代码
代码
import java.util.LinkedList;
import java.util.Deque;
public class DequeExample {
public static void main(String[] args) {
Deque<String> deque = new LinkedList<String>();
deque.addFirst("a"); // 使用 addFirst 替换 push
deque.addFirst("b");
deque.addFirst("c");
System.out.println(deque);
String str = deque.peek();
System.out.println(str);
System.out.println(deque);
while (deque.size() > 0) {
System.out.println(deque.removeFirst()); // 使用 removeFirst 替换 pop
}
System.out.println(deque);
}
}
输出:
[c, b, a]
c
[c, b, a]
c
b
a
[]
接口说明
addFirst
void addFirst(E e)
Inserts the specified element at the front of this deque if it is possible to do so immediately without violating capacity restrictions, throwing an IllegalStateException if no space is currently available. When using a capacity-restricted deque, it is generally preferable to use method offerFirst(E).
如果可以在不违反容量限制的情况下立即执行此操作,则将指定的元素插入此双端队列的前面,如果当前没有可用空间,则抛出IllegalStateException。使用容量受限的双端队列时,通常最好使用方法offerFirst(E)。
removeFirst
E removeFirst()
Retrieves and removes the first element of this deque. This method differs from pollFirst only in that it throws an exception if this deque is empty.
检索并删除此双端队列的第一个元素。此方法与pollFirst的不同之处仅在于,如果此双端队列为空,则它将引发异常。
Queue和PriorityQueu源码分析
什么是 Queue
数据结构中的队列,先进先出式的数据结构,所有新元素都插入队列的末尾,移除元素都移除队列的头部。主要注意的时,Java中的Queue是一个接口。
Queue 源码分析
public interface Queue<E> extends Collection<E> {
boolean add(E e); //往队列插入元素,如果出现异常会抛出异常
boolean offer(E e); //往队列插入元素,如果出现异常则返回false
E remove(); //移除队列元素,如果出现异常会抛出异常
E poll(); //移除队列元素,如果出现异常则返回null
E element(); //获取队列头部元素,如果出现异常会抛出异常
E peek(); //获取队列头部元素,如果出现异常则返回null
}
上面六个函数总体上分为两类:安全的会进行容量检查的(add,remove,element),如果队列没有值,则取元素会抛出IlleaglStatementException异常。不安全的不进行容量控制的(offer,poll,peek )。
AbstractQueue 是Queue 的抽象实现类, AbstractQueue 也继承自 AbstractCollection 。AbstractQueue 实现的方法不多,主要就 add、remove、element 三个方法的操作失败抛出了异常。
什么是 PriorityQueue
PriorityQueue 优先级队列, ,不同于普通的遵循FIFO(先进先出)规则的队列,每次都选出优先级最高的元素出队,优先队列里实际是维护了这样的一个堆,通过堆使得每次取出的元素总是最小的(用户可以自定义比较方法,相当于用户设定优先级)。 PriorityQueue 是一个小顶堆,是非线程安全的;PriorityQueue不是有序的,只有堆顶存储着最小的元素;从数据的存储结构看, PriorityQueue 一个数组;从逻辑结构看, PriorityQueue 是一棵平衡二叉树。
什么是 PriorityQueue
PriorityQueue 优先级队列, ,不同于普通的遵循FIFO(先进先出)规则的队列,每次都选出优先级最高的元素出队,优先队列里实际是维护了这样的一个堆,通过堆使得每次取出的元素总是最小的(用户可以自定义比较方法,相当于用户设定优先级)。 PriorityQueue 是一个小顶堆,是非线程安全的;PriorityQueue不是有序的,只有堆顶存储着最小的元素;从数据的存储结构看, PriorityQueue 一个数组;从逻辑结构看, PriorityQueue 是一棵平衡二叉树。
PriorityQueue 源码分析
继承关系
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable{
// 略
}
PriorityQueue 继承了AbstractQueue 类,而AbstractQueue 类实现了Queue接口。
主要属性
// 默认容量
private static final int DEFAULT_INITIAL_CAPACITY = 11;
// 存储元素的数组,Object类型的
transient Object[] queue;
// 元素个数
int size;
// 比较器
private final Comparator<? super E> comparator;
// 修改次数
transient int modCount;
transient Object[] queue
源码注释
Priority queue represented as a balanced binary heap: the two children of queue[n] are queue[2*n+1] and queue[2*(n+1)]. The priority queue is ordered by comparator, or by the elements' natural ordering, if comparator is null: For each node n in the heap and each descendant d of n, n <= d. The element with the lowest value is in queue[0], assuming the queue is nonempty.
优先级队列是一个平衡的二叉树堆,queue[n]的两个子节点queue[2n+1] and queue[2(n+1)]。 优先级队列 按照 comparator 进行排序或者 按自然顺序排序。 如果 comparator 为null ,堆中每一个节点 n 以及 n的后代d, n<=d。假设队列为非空,则具有最小值的元素位于queue [0]中。
常用构造函数
- 1、创建一个优先队列对象,默认大小,队列中的元素按照自然顺序排序。
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
- 2、创建一个指定大小的优先队列对象,队列中的元素按照自然顺序排序。
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}
- 3、创建一个默认大小(11)的优先队列对象,队列中的元素按照指定比较器进行排序。
public PriorityQueue(Comparator<? super E> comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
- 4、根据指定的大小和比较器来创建一个优先队列对象。
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
add(e)/offer(e)方法介绍
add方法
插入一个元素到优先队列中
add方法的源代码如下:
public boolean add(E e) {
return offer(e);
}
从源码中可以看出add方法直接调用了offer方法。
offer(e)方法
public boolean offer(E e) {
if (e == null) //检查是否为null, 如果为null 则抛空指针异常
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length) // 检查容量是否足够, 不足进行扩容
grow(i + 1); // 扩容函数
siftUp(i, e); // 在数组的末尾插入新的元素,向上调整,使之保持为二叉堆的特性。
size = i + 1;
return true;
}
1)首先检查要添加的元素e是否为null,如果为null,则抛空指针异常,如果不为null,则进行2
2)判断数组是否已满,如果已满,则进行扩容,否则将元素加入到数组末尾即可。
由于这个数组表示的是一个“二叉堆”,因此还需要进行相应的调整操作,使得这个数组在添加元素之后依然保持的是二叉堆的特性。
grow(int minCapacity)方法
//增加数组的容量
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
//如果比较小,则扩容为原来的2倍,否则只扩容为原来的1.5倍
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
hugeCapacity(int minCapacity) 方法
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
注:
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
public static final int MAX_VALUE = 0x7fffffff;
当 大于 MAX_ARRAY_SIZE 时扩容记性了特殊处理
siftUp(int k, E x)方法
将元素x插入到queue[k]位置上,并进行调整使之具有二叉堆特性
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x); // 使用比较器 comparator
else
siftUpComparable(k, x);
}
siftUpUsingComparator和siftUpComparable源码如下
从 位置 k 向数组起始位置 调整使之具有二叉堆特性,自下而上的堆化,
也就是 二叉堆插入元素思想操作:
可参见 拜托,面试别再问我堆(排序)了!
siftUpComparable(int k, E x)方法
@SuppressWarnings("unchecked")
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1; // 找 parent 父节点
Object e = queue[parent];
if (key.compareTo((E) e) >= 0) // 比较 按 自然顺序 排列
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
siftUpUsingComparator(int k, E x)方法
@SuppressWarnings("unchecked")
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0) // 使用比较器 comparator
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
poll()方法介绍
取出优先队列中的第一个元素
public E poll() {
if (size == 0) // 优先队列大小判断
return null;
int s = --size;
modCount++;
E result = (E) queue[0]; // 取出第一个元素
E x = (E) queue[s]; // 取出最后一个元素
queue[s] = null;
if (s != 0)
siftDown(0, x);
return result;
}
poll方法:取出queue[0]元素,然后将queue[size-1]插入到queue[0],然后自上而下堆化来保持二叉堆的特性。
siftDown(int k, E x)方法
//将元素x存储在queue[k],并进行相应的调整
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
siftDownComparable(int k, E x)方法
private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0) //两个儿子节点较小的那一个
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}
siftDownUsingComparator(int k, E x)方法
private void siftDownUsingComparator(int k, E x) {
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = x;
}
remove(Object o) 方法介绍
移除指定元素
public boolean remove(Object o) {
int i = indexOf(o); // 判断位置
if (i == -1) //没有在数组中找到
return false;
else {
removeAt(i); //进行删除并调整
return true;
}
}
indexOf(Object o)方法
private int indexOf(Object o) {
if (o != null) {
for (int i = 0; i < size; i++) // 数组遍历过程
if (o.equals(queue[i]))
return i;
}
return -1;
}
找到对象o在数组中出现的第一个索引
emoveAt(int i)方法
E removeAt(int i) {
// assert i >= 0 && i < size;
modCount++;
int s = --size;
if (s == i) // removed last element
queue[i] = null;
else {
E moved = (E) queue[s]; // 取出最后一个元素
queue[s] = null;
siftDown(i, moved); //从i向下调整堆
if (queue[i] == moved) { // 如果发现调整后 moved 还在 i 位置没有下沉,向上调整看是否上浮
siftUp(i, moved);
if (queue[i] != moved)
return moved;
}
}
return null;
}
堆插入元素与删除堆顶元素操作
以下面这个对为例
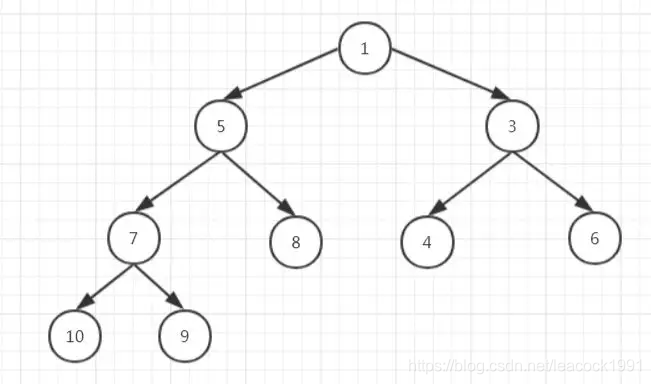
用数组来存储为:

插入元素
往堆中插入一个元素后,需要继续满足堆的两个特性,即:
(1)堆是一颗完全二叉树;
(2)堆中某个节点的值总是不大于(或不小于)其父节点的值。
把元素插入到最后一层最后一个节点往后一位的位置,也就是在数组的末尾插入新的元素
,插入之后可能不再满足条件(2),这时候我们需要调整,自下而上的堆化。
上面那个堆插入元素2,我们把它放在9后面,这时不满足条件(2)了,我们就需要堆化。(这是一个小顶堆)

从插入元素的过程,我们知道每次与
的位置进行比较,所以,插入元素的时间复杂度为
。
删除堆顶元素
删除了堆顶元素后,要使得还满足堆的两个特性。把最后一个元素移到根节点的位置,这时候就满足条件(1),之后就需要堆化了使它满足条件(2)

从删除元素的过程,我们知道把最后一个元素拿到根节点后,每次与
和
位置的元素比较,取其小者,所以,删除元素的时间复杂度也为
。
回到 remove(Object o) 方法 ,不是删除堆顶元而是删除指定元素,源码中会先找Object o在数组中位置 i,再取出最后一个元素从i自上而下堆化,如果最后一个元素没有下沉,会从i自下而上堆化
参考:
拜托,面试别再问我堆(排序)了!
https://mp.weixin.qq.com/s/AF2tMHfofG8b51yIyaIReg
