众所周知,HDFS中数据都是保存在DataNode中,通过复制相同的数据到多个DN中,HDFS可以容忍DN的失败。但如果某些DN的磁盘出现故障,会怎么样呢?本文解释了DN上的一些后台任务是如何工作的,以帮助HDFS跨多个DN管理其数据以实现容错。特别地,将重点介绍Block Scanners & Volume Scanners, Directory Scanners 以及 Disk Checker:它们做什么,如何工作及一些相关的配置。
HDFS中的Block
在详细介绍DataNode 扫描器(或检查器)之前,我们先简要说明一下HDFS中的block的组织结构,重点说明DataNode中的block组织结构。我们知道,HDFS中的整体架构中,NameNode(NN)存储的是元数据(metadata),而DataNode(DN)存储的是实际的数据。通常,每个DN都是有多块数据盘(HDFS的术语称之为volume)的。HDFS中的一个文件是由一个或多个block组成,每个block有一个或多个拷贝(称为Replica,副本),同一个block的不同副本存储在不同的DN上。每个block的详细状态都通过block report从DN发送给NN。一个block会有多种状态,一个处于finalized状态的block最终会以block文件和meta文件存储在DN磁盘上的本地文件系统中。其中block文件存储文件数据,而meta文件存储的是文件数据的校验和,用以验证block文件的完整性。meta文件以block文件命名,同时包含一个生成戳。下图是一个DN磁盘的block文件和他们的meta文件的示例:

HDFS的核心假设之一是,硬件故障是一种常态,而不是例外。当磁盘出现故障时,block文件和meta文件都可能会损坏。HDFS有识别和处理这些问题的机制。这些机制是什么?特别地:
- DN是在什么时候以及如何验证一个block?
- DN如何验证其内存中关于block的元数据是否与磁盘上的实际数据一致?
- 如果在block读取期间发生故障,是由于磁盘错误?或者只是一些间歇性错误(如网络超时)?
这些问题的答案存在于DN后台的各种任务中,这就是接下来要介绍的。下面将会介绍DN上的三种任务,每种任务都试图相应地解决上面的一个问题:Block Scanners & Volume Scanners, Directory Scanners 以及 Disk Checker。
Block Scanner & Volume Scanner
Block Scanner的功能是扫描block数据以检测可能的损坏。由于在任何时间任何DN上的任何block都可能发生数据损坏,因此及时发现这些错误是很重要的。这样NN可以删除这些损坏的block并重新复制它们,以确保数据的完整性以及减少客户端的错误。这样磁盘I/O仍然可以满足实际的请求。
因此,Block Scanner需要以相对比较低的频率并相对快速的确保那些可疑的block被扫描,并且每隔一段时间扫描一次其他的block,同时不消耗大量的I/O资源。
每个DN都有一个Block Scanner与其关联,同时Block Scanner会包含一组Volume Scanner的集合。每个Volume Scanner会运行自己的线程并负责扫描DN上的单个volume。Volume Scanner会慢慢的逐个读取所有的block,并验证每个block。我们称之为常规扫描(regular scan)。注意,这些扫描会非常慢,因为执行检查需要读取整个block,这会消耗大量的I/O。
Volume Scanner还维护了一个可疑block的列表。从磁盘读取这些block时会导致一些特定类型的异常抛出。扫描过程中,可疑block的扫描会优先于常规block。此外,每个Volume Scanner都会跟踪它过去十分钟扫描过的可疑block,避免重复扫描。
注意,Block Scanner和Volume Scanner是实现细节,他们一起处理block扫描的工作。因此简单起见,我们将在后面的部分统一将Block Scanner和Volume Scanner称为 ‘Block Scanner’ 。
Block Scanner是通过如下的机制来决定要扫描的block:
- 当一个DN为来自客户端或者另一个DN的I/O请求提供服务时,如果发生了IOException,并且不是由于网络原因(如socker超时、管道断开或连接重置)造成的,那么该block就会被标记为可疑的(suspicious)并将其添加到Block Scanner的可疑block列表中
- Block Scanner会在所有block上循环,每次迭代会扫描一个block
- 如果可疑block列表不为空,就会弹出一个可疑block进行扫描;
- 否则,会扫描一个正常的block
只有本地(非网络)IOException会导致block被标记为可疑的,因为我们希望保持可疑block列表的简短并减少误报。这样,一个损坏问题就会优先得到处理并及时报告。
为了跟踪block之间的扫描位置,会为每个volume维护一个block cursor。cursor会周期性的保存到磁盘中。这样,即使DN进程重启或服务器重启,扫描也不必从头重新启动。
下图是一个 block cursor文件的示例:
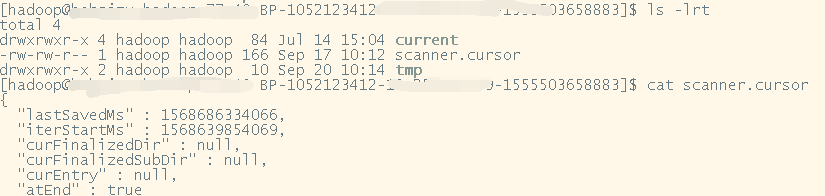
如本节开头提到的,scanner的另一问题是I/O的消耗。无论被扫描的block是可疑block还是正常block,我们都不能持续的循环扫描它们,因为这可能造成繁忙的I/O并损害正常的I/O性能。为了解决此问题,scanner以可配置的速率运行,两次扫描周期之间会有适当的睡眠时间。扫描周期是执行整个扫描的间隔时长。当一个block被标记为可疑时,如果volume scanner正在等待下一个扫描周期,则会被唤醒。如果在扫描期间内未完成一次完整扫描,则扫描将继续而不会休眠。
Block Scanner相关的配置如下:
- dfs.datanode.scan.period.hours 如果为正值,则数据节点在指定的扫描周期内不会扫描任何单个块多次。如果为负,则禁用Block Scanner。如果设置为零,则使用默认值504小时或3周,默认是504。以前版本的HDFS描述的将此值设置为0将禁用Block Scanner的说法是错误的。
- dfs.block.scanner.volume.bytes.per.second 如果为0,则将禁用DataNode的块扫描程序。如果为正值,则这是DataNode的Block Scanner尝试每秒从每个volume中扫描的字节数,默认是1048576,也就是1MB。
Directory Scanners
虽然Block Scanner可以确保存储在磁盘上的block文件处于良好状态,但DN将block信息缓存在内存中。因此,确保缓存信息的准确性至关重要。Directory Scanner将会检查并修复缓存和磁盘中实际数据之间的不一致。Directory Scanner会定期扫描数据目录中的block和metadata文件,并使磁盘和内存中维护的block信息之间的差异保持一致。
如果一个block被标记为corrupted,它将通过下一个block report报告给NN。然后,NN将安排block从完整的副本进行复制。
与Block Scanner类似,Directory Scanner也需要限制。限制是通过为每个Directory Scanner线程指定每秒只能运行的毫秒数来实现的。
Directory Scanner相关的配置如下:
- dfs.datanode.directoryscan.interval DataNode扫描数据目录并协调内存块和磁盘块之间的差异的间隔时间(秒)。支持多种时间单位,默认21600s(6小时)。
- dfs.datanode.directoryscan.threads Directory Scanner并行执行时的线程数,默认是1。
- dfs.datanode.directoryscan.throttle.limit.ms.per.sec 指定每秒中Directory Scanner线程运行的毫秒数。限制是针对每个线程的,不是聚合的。如为4个compiler 线程设置100ms的限制,表示每个线程都限制为100ms,而不是每个线程限制为25ms。注意,限制不会中断 report compiler thread,因此线程每秒的实际运行时间通常会比限制稍高一些,通常不会超过20%。值只有介于1和1000之间才有效,设置无效的值将导致禁用限制并记录错误消息。默认是1000毫秒,也就是禁用compiler线程限制。
Disk Checker
除了上面提到的scanner以外,DN还会在后台线程中运行一个Disk Checker,以确定volume是否不健康以及是否要将其删除。使用Disk Checker的原因是,如果在volume级别出现问题,HDFS应该检测到并停止尝试向该volume写入数据。另一方面,删除一个volume并不是一件小事(non-trivial),这会产生很大的影响,因为它将使该volume上的所有block都不可访问,并且HDFS必须处理由于删除而导致的所有under-replicated的block。因此,Disk Checker执行最基本的检查,使用非常保守的逻辑来确认故障。
检查的逻辑非常的简单,它按顺序检查DN上的以下目录:
- 目录 ‘finalized’
- 目录 ‘tmp’
- 目录 ‘rbw’
检查三个目录时,Disk Checker将验证:
- 目录及其所有的父目录都存在,或者可以创建其他目录。
- 路径确实是目录类型。
- 进程对目录具有读、写和执行权限。
严格地说,我们应该递归地对这3个目录下的所有子目录执行相同的检查。但这会产生过多的I/O,同时几乎没有什么好处——这些错误的block无论如何都会被添加到 Block Scanner中的可疑block中,因此它们很快就会被扫描到并报告。另一方面,类似于HBASE这类应用程序对性能非常敏感,并会努力的确保SLA,而这里过多的I/O可能会产生无法容忍的峰值。因此,仅执行上述3项检查。
Block Scanner 和 Directory Scanner在DN启动时激活并定期扫描,但Disk Checker只按需运行,Disk Checker线程是惰性创建的。具体来说,Disk Checker仅在DN在常规I/O操作(例如关闭块或元数据文件、Directory Scanner报告错误等)期间捕获到IOException时运行。另外,Disk Checker在5~6秒内最多只能运行一次。创建Disk Checker线程时会随机生成此特定周期。
此外,如果启动时出现故障的volume数大于配置的阈值,则DN将自动关闭。DN通过比较所有已配置的storage location与实际使用的storage location之间的差异来执行此初始检查。该阈值可通过dfs.datanode.failed.volumes.allowed 配置,默认值为0。
Disk Checker相关的配置如下:
- dfs.datanode.disk.check.min.gap 对DN上同一个volume的两次连续检查之间的最小间隔时间。支持多种时间单位后缀,如果未指定后缀,则假定为毫秒,默认是15m。
- dfs.datanode.disk.check.timeout 在DN启动期间完成一个磁盘检查所允许的最长时间。如果此时间间隔内检查未完成,则磁盘被声明为Failed。支持多种时间单位后缀,如果未指定后缀,则假定为毫秒,默认是10m。
配置整理
上面介绍了Block Scanner, Directory Scanner, 和 Disk Checker,最后统一对这些任务相关的配置进行整理(基于Apache hadoop3.1.1版本),如下:
Block Scanner相关
- dfs.datanode.scan.period.hours 如果为正值,则数据节点在指定的扫描周期内不会扫描任何单个块多次。如果为负,则禁用Block Scanner。如果设置为零,则使用默认值504小时或3周,默认是504。以前版本的HDFS描述的将此值设置为0将禁用Block Scanner的说法是错误的。
- dfs.block.scanner.volume.bytes.per.second 如果为0,则将禁用DataNode的块扫描程序。如果为正值,则这是DataNode的Block Scanner尝试每秒从每个volume中扫描的字节数,默认是1048576,也就是1MB。
Directory Scanner相关
- dfs.datanode.directoryscan.interval DataNode扫描数据目录并协调内存块和磁盘块之间的差异的间隔时间(秒)。支持多种时间单位,默认21600s(6小时)。
- dfs.datanode.directoryscan.threads Directory Scanner并行执行时的线程数,默认是1。
- dfs.datanode.directoryscan.throttle.limit.ms.per.sec 指定每秒中Directory Scanner线程运行的毫秒数。限制是针对每个线程的,不是聚合的。如为4个compiler 线程设置100ms的限制,表示每个线程都限制为100ms,而不是每个线程限制为25ms。注意,限制不会中断 report compiler thread,因此线程每秒的实际运行时间通常会比限制稍高一些,通常不会超过20%。值只有介于1和1000之间才有效,设置无效的值将导致禁用限制并记录错误消息。默认是1000毫秒,也就是禁用compiler线程限制。
Disk Checker相关
- dfs.datanode.disk.check.min.gap 对DN上同一个volume的两次连续检查之间的最小间隔时间。支持多种时间单位后缀,如果未指定后缀,则假定为毫秒,默认是15m。
- dfs.datanode.disk.check.timeout 在DN启动期间完成一个磁盘检查所允许的最长时间。如果此时间间隔内检查未完成,则磁盘被声明为Failed。支持多种时间单位后缀,如果未指定后缀,则假定为毫秒,默认是10m。
参考:
https://blog.cloudera.com/hdfs-datanode-scanners-and-disk-checker-explained/
https://hadoop.apache.org/docs/r3.1.1/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
