文章目录
requests
作用:发送网络请求,返回相应数据 中文文档API
requests使用
乱码解决方式
文本乱码
- 方法一
使用.text方法读取内容,使用.encoding修改编码方式
r = requests.get('http://www.baidu.com/')
r.encoding = 'utf-8'
print(r.text)
- 方法二
使用.content方法读取内容,使用.decode修改编码方式
r = requests.get('http://www.baidu.com/')
print(r.content.decode('utf8'))
如果是图片、视频、音频等内容直接使用.content方法读取即可,如果使用decode方法修改编码会报错
伪装浏览器
我们先来模仿浏览器获取百度内容
- headers: 请求头,User-Agent用于模拟浏览器(小知识:每个浏览器的信息中都有Mozilla,Mozilla是网景浏览器的内核,因为一些历史原因网景已经消失在历史的长河中,但网景对浏览器发展的巨大影响尚未消失)
- get: 使用get请求获取网站内容
- encoding:定义网站使用的编码(国内常用utf-8,也可能使用gbk)
import requests
class ReptileTest:
def __init__(self):
self.request_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
def main(self):
# 使用get方法连接百度
r = requests.get('http://www.baidu.com', headers=self.request_header)
# 定义编码
r.encoding = 'utf-8'
# 输出内容
print(r.text)
if __name__ == '__main__':
reptile = ReptileTest()
reptile.main()
发送带参请求
URL知识,URL中可以传递给服务器产生,参数一般是灵活多变的,有时候我们并不会直接将参数写死,这时候我们可以将参数以字典的形式动态传入。
import requests
# http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=50
class ReptileTest:
def __init__(self):
self.request_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.3992.4 Safari/537.36'}
def main(self):
"""主函数"""
data = {
'kw': 'python',
'pn': 50
}
r = requests.get('http://tieba.baidu.com/f', headers=self.request_header, params=data)
r.encoding = 'utf-8'
print(r.text)
if __name__ == '__main__':
reptile = ReptileTest()
reptile.main()
实战测试抓取
百度贴吧
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# @Author : 寻觅
# @File : requests库入门.py
# @Time : 2020/1/9 1:12
# @Software: PyCharm
import requests
# 抓取百度贴吧的Python论坛页面
# http://tieba.baidu.com/f?kw=python&pn=50
# http://tieba.baidu.com/f?kw=python&pn=100
class ReptileTest:
def __init__(self, name, page):
self.request_url = 'http://tieba.baidu.com/f'
self.request_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
self.name = {'kw': name, 'pn': 0}
self.page = page
def parse_url(self):
"""构造连接列表"""
if (self.page-1)*50 > self.name['pn']:
self.name['pn'] += 50
else:
self.page = False
def save_html(self):
"""保存页面"""
r = requests.get('http://tieba.baidu.com/f', headers=self.request_header, params=self.name)
r.encoding = 'utf-8'
with open(f'{self.name["kw"]}贴吧第{self.name["pn"] // 50 + 1}页.html', 'wb') as w:
w.write(r.content)
def run(self):
"""运行"""
while self.page:
self.save_html()
self.parse_url()
if __name__ == '__main__':
tieba_name = input('请输入爬取贴吧的名称')
tieba_page = int(input('需要爬取的页数'))
reptile = ReptileTest(tieba_name, tieba_page)
reptile.run()
胡萝卜周
class ReptileTest:
def __init__(self, page):
self.request_url = 'http://www.carrotchou.blog/page/{}'
self.request_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
self.page = page
self.cur = 1
def parse_url(self):
"""构造连接列表"""
if self.page > self.cur:
self.cur += 1
else:
self.page = False
def save_html(self):
"""保存页面"""
r = requests.get(self.request_url.format(self.cur), headers=self.request_header)
r.encoding = 'utf-8'
with open(f'胡萝卜周第{self.cur}页.html', 'wb') as w:
w.write(r.content)
def run(self):
"""运行"""
while self.page:
self.save_html()
self.parse_url()
if __name__ == '__main__':
carrot_page = int(input('需要爬取的页数'))
reptile = ReptileTest(carrot_page)
reptile.run()
带参post请求
POST因为其隐式传输(传输内容不会再URL中显示),传输内容大小无限制等特性,常用于登陆注册或者大文件传输时使用
有道翻译
大多数网站的PC端反扒已经较为完善,这时候我们可以尝试对网站的手机端进行数据爬取,有道的PC端存在反扒措施,但是手机端可以直接爬取,下面我们就来尝试使用有道翻译进行post请求测试,有道翻译手机版在2020年1月还未有反扒措施。
这里首先我们使用.post方法请求,而不是.get方法请求,之后我们需要在请求中添加请求数据(data),这里的数据也就是我们需要翻译的内容。我们可以在浏览器控制台中查看
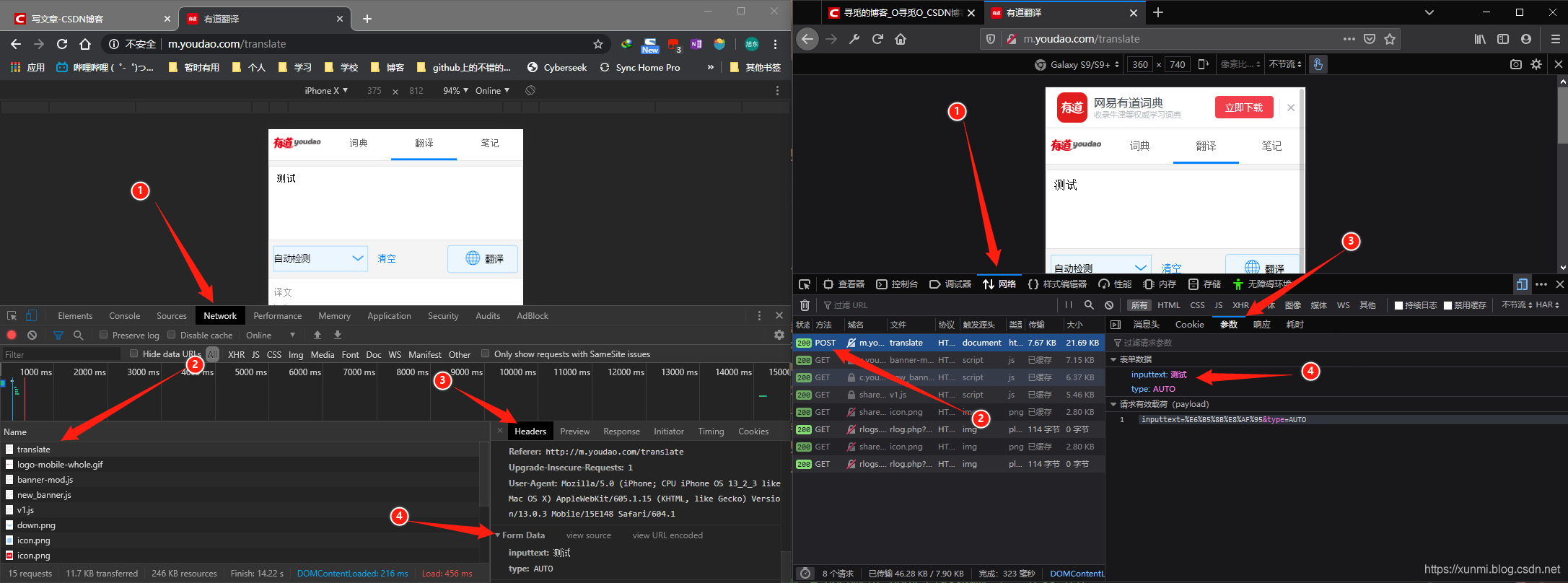
将此时数据填入data中即可。进行带参数的post访问
import requests
# 使用post请求
class ReptileTest:
def __init__(self):
self.request_url = 'http://m.youdao.com/translate'
self.request_header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 7.0; SM-G892A Build/NRD90M; wv) '
'AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/67.0.3396.87 '
'Mobile Safari/537.36'}
self.data = {"inputtext": "测试", "type": "AUTO"}
def main(self):
"""主函数"""
r = requests.post(self.request_url, data=self.data, headers=self.request_header)
with open('翻译.html', 'wb') as w:
w.write(r.content)
if __name__ == '__main__':
reptile = ReptileTest()
reptile.main()
使用代理IP
代理的作用在这里就不做赘述了,以防被和谐
用法:.get方法或.post方法中添加proxies属性
proxies(代理):字典映射协议到代理的URL。
class ReptileTest:
def __init__(self):
self.request_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.3992.4 Safari/537.36'}
def main(self):
"""主函数"""
# 我这里使用的免费ip可能只有几分钟的存活时间
proxies = {
'http': 'http://220.135.165.38:8080'
}
r = requests.get('http://www.baidu.com/', headers=self.request_header, proxies=proxies)
r.encoding = 'utf-8'
print(r.text)
if __name__ == '__main__':
reptile = ReptileTest()
reptile.main()
cookie 与 session
cookie与session都是用于保存数据的,他们最大的区别是cookie是在本地,也就是用户的客户端中保存数据,而session则是在服务器中保存数据他们相比起来各有优劣。
- cookie将数据保存在本地,可以将用户信息保存在本地,可以简化用户再次操作的流程,而且可以记录一些用户习惯,可以更好的服务于用户,但是这样的做法导致数据安全性较低,cookie中保存的密码私钥等重要信息容易遭到泄露,同时本地的cookie可以被有心之人利用,进行cookie欺诈等行为,且保存数据只能小于4k,大多数浏览器也规定一个站点最多只能保存20个cookie。
- session将数据保存在服务器,虽然解决了安全性问题,但是如果有大量用户,session会占用服务器大量资源,使服务器性能下降。
爬虫利用cookie与session
带上cookie,我们可以模拟登陆后的用户,但是带上cookie后我们如果过于频繁的去访问服务器,也容易暴露出我们是爬虫,在Python中,下面的我们都将使用人人网做测试。
模拟登陆方法一
思路:我们可以利用resquests库中的.session()方法来保持用户的登陆状态。
- 特点:
- 适用于cookie保存时效短,易失效的网站,可以及时获取最新的cookie,
- 每次都要程序运行都要重新获取新的cookie操作较为麻烦。
- 思路
-
首先我们打开人人网,找到表单提交的地址,在控制台中,我们很容易就找到人人网登陆表单的提交地址为:http://www.renren.com/PLogin.do

-
调用requests库中的
.session()方法 -
用使用过
.session()方法的对象对登陆表单提交地址进行post请求提交登陆数据,进行登陆操作,在使用post请求登陆后,会自动将cookie保存 -
使用带cookie的对象用get请求,这时候就可以正常访问个人用户界面了
-
class ReptileCookie:
def __init__(self):
# 调用session方法
self.session = requests.session()
# 人人网登陆地址
self.request_url = 'http://www.renren.com/PLogin.do'
# 人人网个人信息页面(每个人的个人信息页面都不同,这里需要改成你自己的页面才能看到效果)
self.request_login = 'http://www.renren.com/973399342/profile'
self.request_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4029.0 Safari/537.36'}
self.login_data = {
'email': '登陆邮箱',
'password': '登陆密码'
}
def main(self):
# 使用session方法后,用户将处于持续登陆状态
self.session.post(self.request_url, data=self.login_data, headers=self.request_header)
# 这时候的session对象中已经保存了登陆的cookie信息,可以访问登陆后才能访问的页面
data = self.session.get(self.request_login, headers=self.request_header)
return data
if __name__ == '__main__':
reptile = ReptileCookie()
items = reptile.main()
items.encoding = 'utf-8'
with open('人人.html', 'wb') as w:
w.write(items.content)
模拟登陆方法二
使用cookie直接登陆
- 特点:
- 适用于cookie保存时效长或有专门获取cookie工具的情况下使用。
- 需要在cookie过期前拿到所以数据。
- 思路
- 这时候我们需要进入已经登陆后的人人网,然后在开发者工具中找到cookie,并放在请求头中。
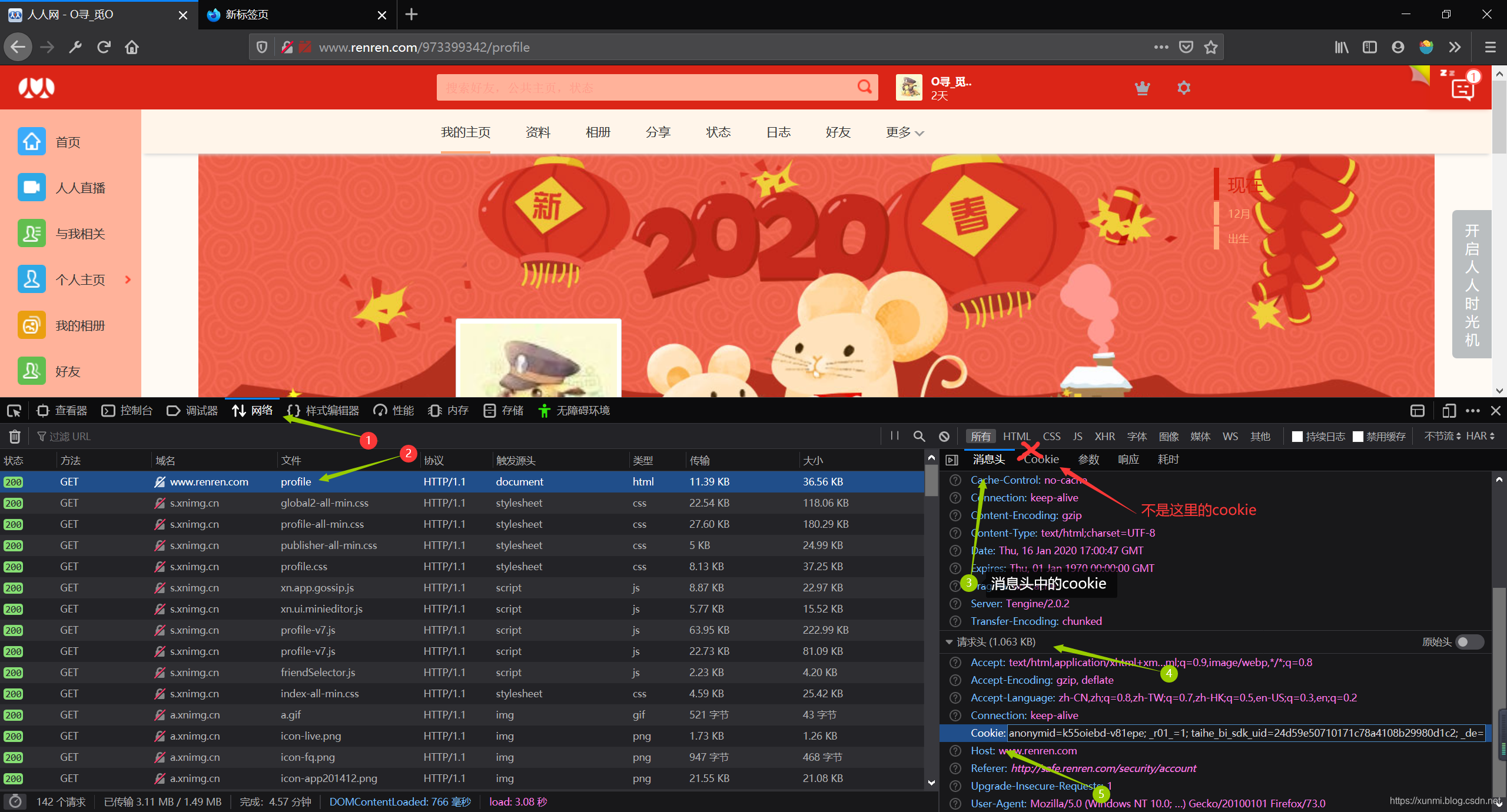
- 使用get请求直接请求对应的页面
- 这时候我们需要进入已经登陆后的人人网,然后在开发者工具中找到cookie,并放在请求头中。
class ReptileCookie:
def __init__(self):
self.requests_header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4029.0 Safari/537.36',
'Cookie': '填写你的cookie'
}
self.requests_url = 'http://www.renren.com/973399342/profile'
def main(self):
return requests.get(self.requests_url, headers=self.requests_header)
if __name__ == '__main__':
data = ReptileCookie()
html_data = data.main()
html_data.encoding = 'utf-8'
with open('人人网.html', 'wb') as w:
w.write(html_data.content)
模拟登陆方法三
第三方法和第二种类似,只是我们将请求头中的cookie取出,利用get或post中的cookie属性将cookie单独传入,但需要注意的是,这里的cookie属性只支持字典.
data = {i.split('=')[0]: i.split('=')[1] for i in cookie.split(';')}使用此字典推导式可以将方法二中的cookie转换为字典
class ReptileCookie:
def __init__(self):
self.requests_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4029.0 Safari/537.36'}
self.requests_cookie = {dict格式的cookie}
self.requests_url = 'http://www.renren.com/973399342/profile'
def main(self):
return requests.get(self.requests_url, cookies=self.requests_cookie, headers=self.requests_header)
if __name__ == '__main__':
items = ReptileCookie()
data = items.main()
data.encoding = 'utf-8'
with open('人人网.html', 'wb') as w:
w.write(data.content)
