用途
本文介绍如何使用kettle,遍历web页面中的url链接,并输出到文本文档。
技术
kettle
javascript
jsoup-1.11.3.jar
转换文件步骤
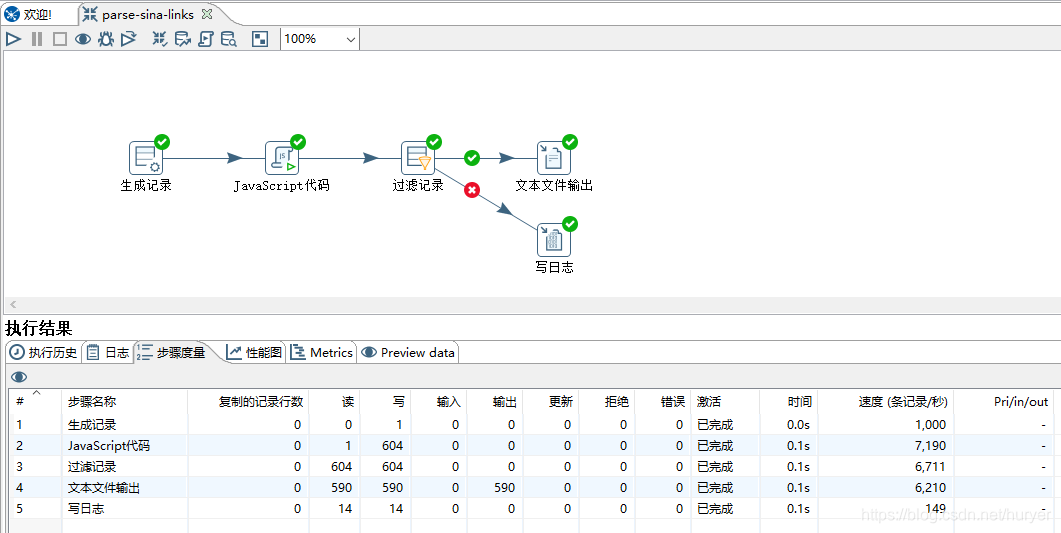
生成记录
此步骤用于设置需要访问的web地址,以sina为例:
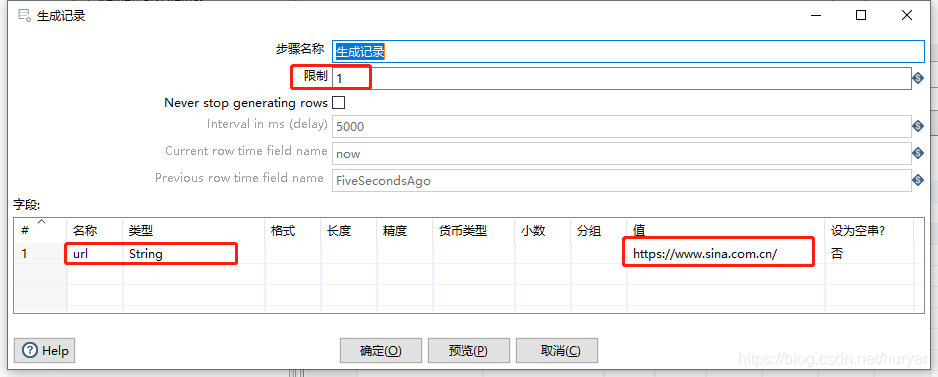
JavaScript代码
源码如下:
var Jsoup = org.jsoup.Jsoup;
var Document = org.jsoup.nodes.Document;
var Element = org.jsoup.nodes.Element;
var Elements = org.jsoup.select.Elements;
function parseLinks(){
writeToLog("开始解析");
var doc = Jsoup.connect(url).get();
var els = doc.select("div ul li");
writeToLog("行数:"+els.size());
for (var i=0;i<els.size();i++) {
var r = els.get(i);
//输出行处理
var newRow = createRowCopy(getOutputRowMeta().size());
var rowIndex = getInputRowMeta().size();
// 获取文件链接地址
var link=r.select("a").attr("href");
var title=r.select("a").text();
newRow[rowIndex++]=i + "\t"+title + "\t" + link;
//输出行
putRow(newRow);
}
}
writeToLog("解析完成");
parseLinks();
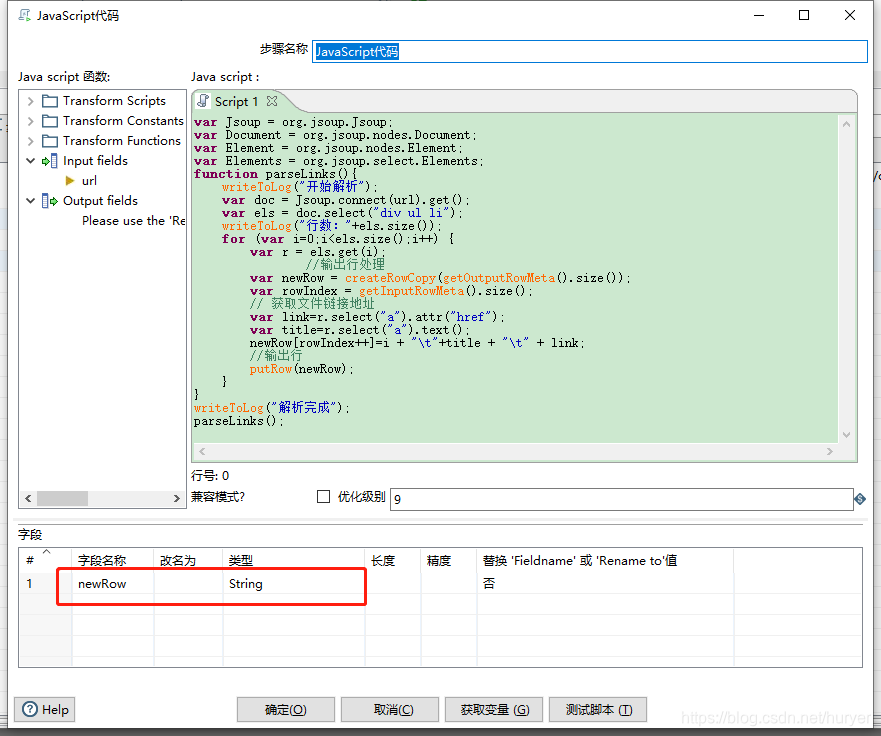
过滤记录
过滤输出的内容,需要包含http协议:
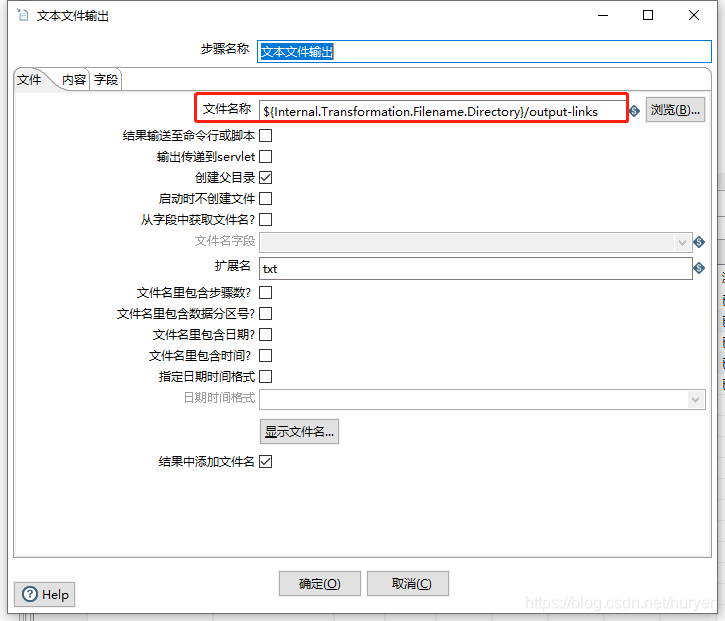
文本文件输出
将结果输出到脚本的当前目录:
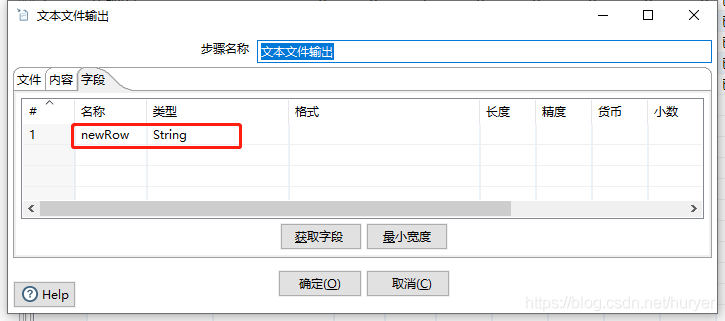
输出字段为:newRow
写日志
此步骤保留为空,则默认输出全部内容:

输出结果

