起步
完成对爬虫基础知识的回顾,我们就正式进入了页面的爬取,这是我们第一个要爬取的图片页面:

第一个scrapy工程
打开cmd,新建工程目录PictureSpider
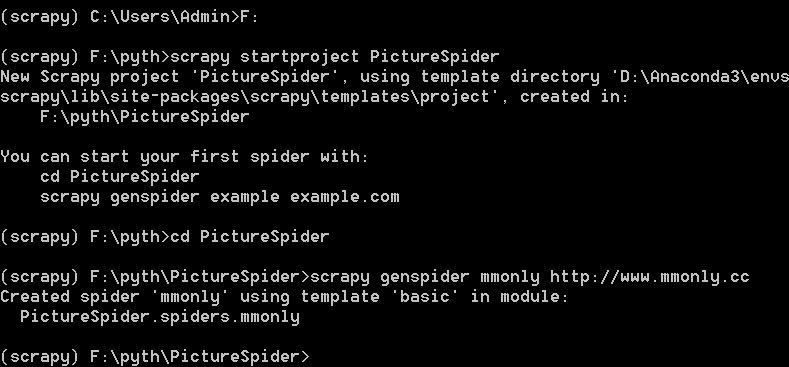
scrapy用basic模板自动创建的mmonly.py文件
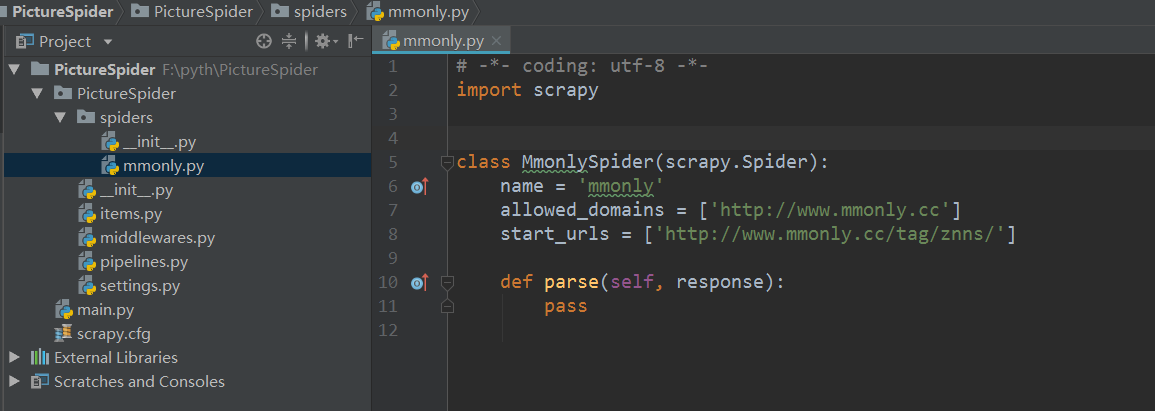
MmonlySpider类继承的scrapy.Spider类,里面的response和request与Django里的功能类似:
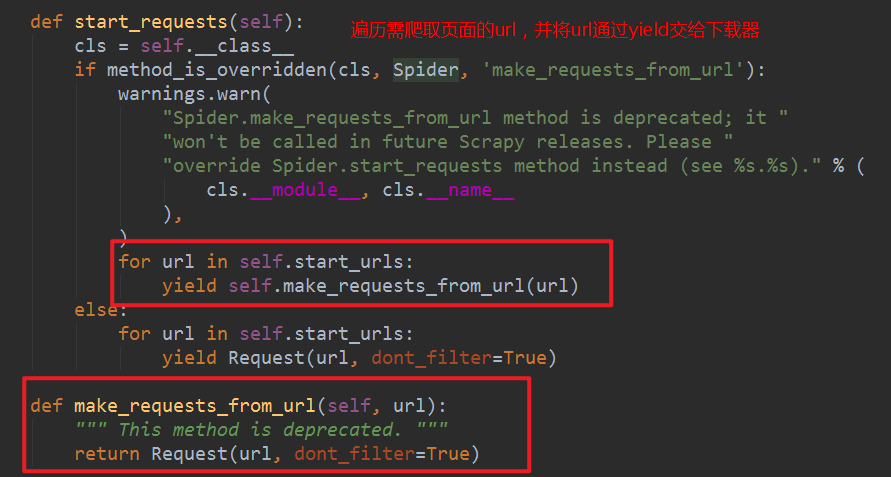
pycharm调试scrapy的技巧:
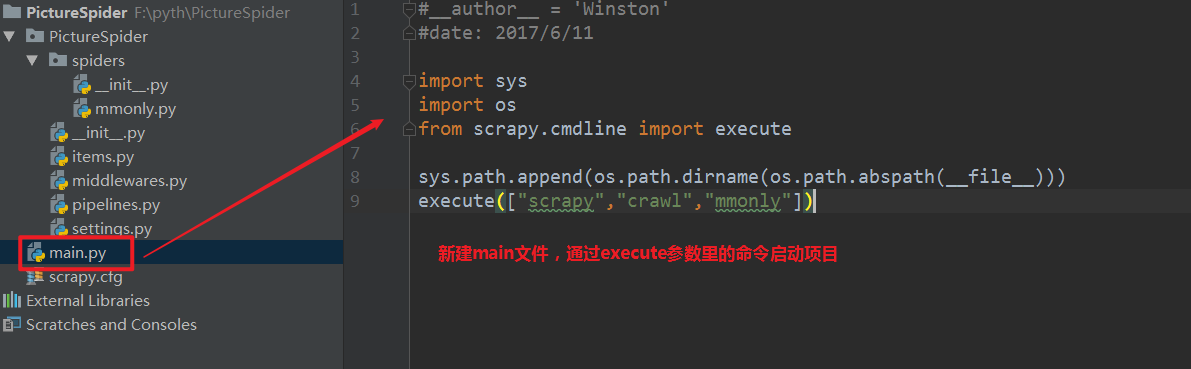
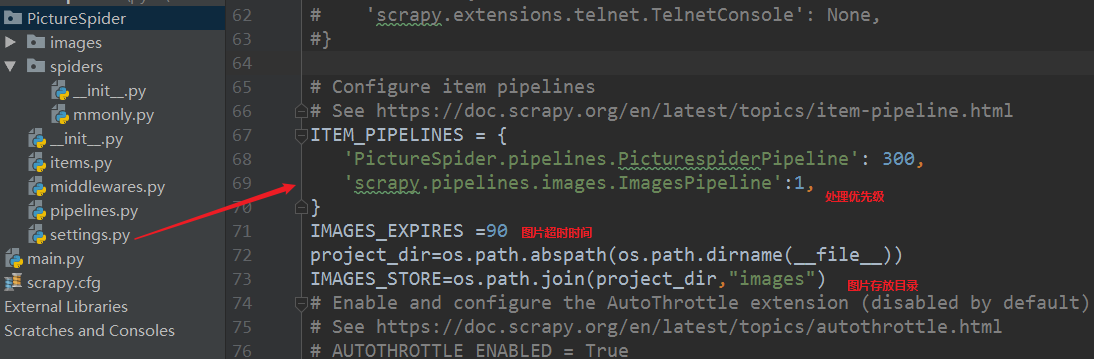
修改setting文件,不遵循robots协议:
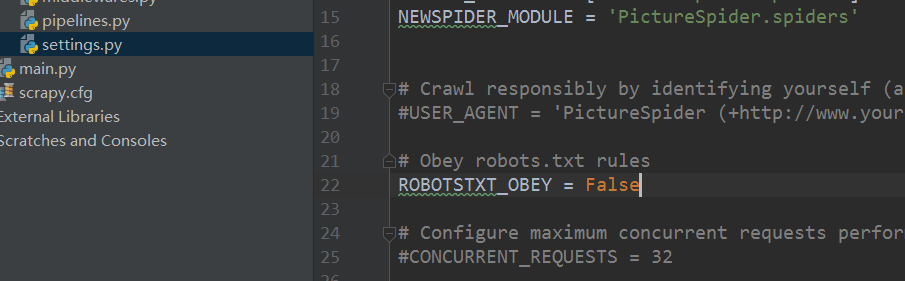
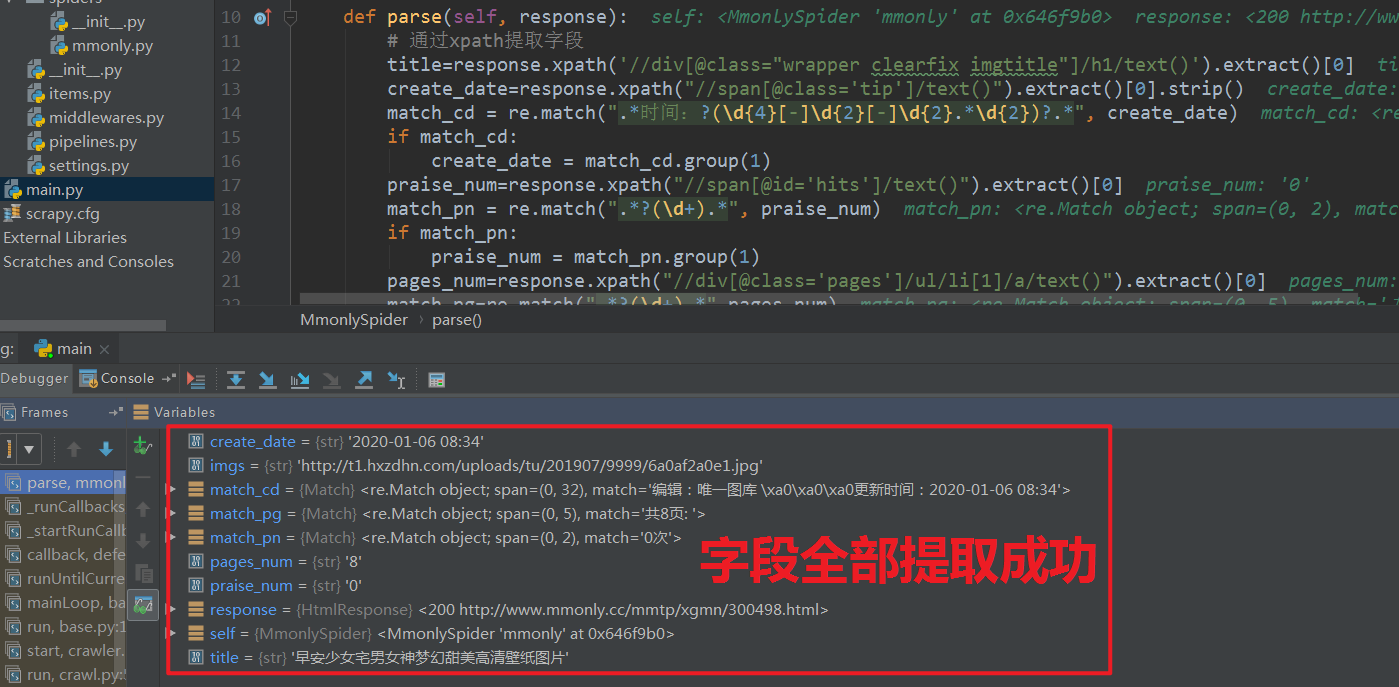
在mmonly.py中设置断点,debug main,py启动项目,按住Ctrl查看response内容:
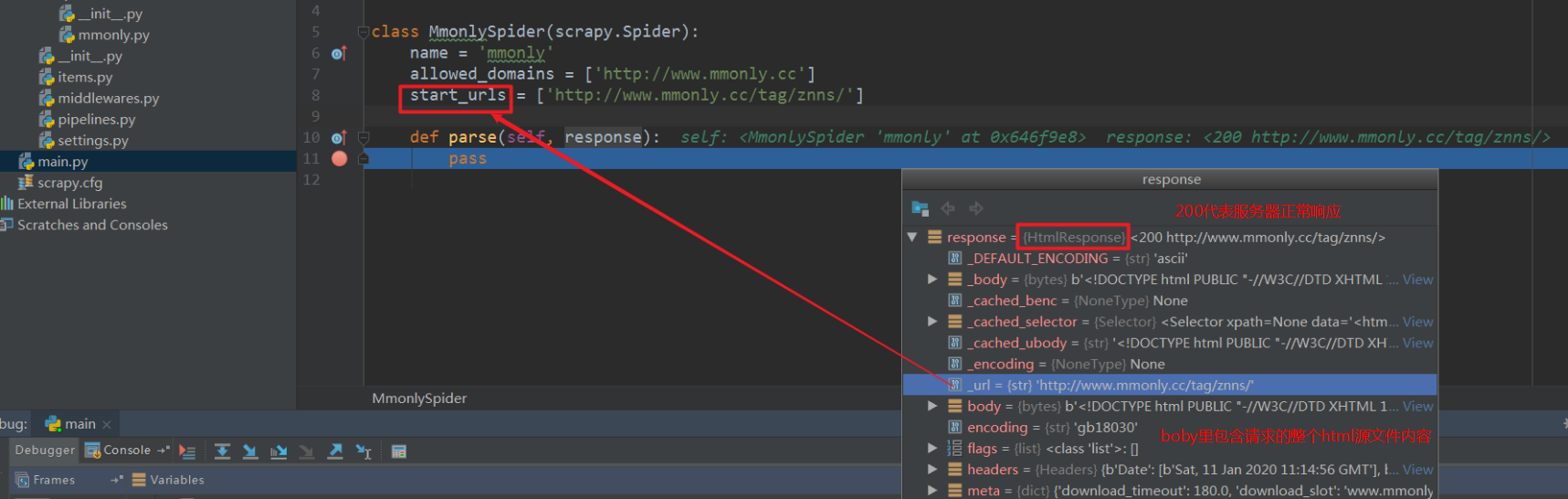
xpath



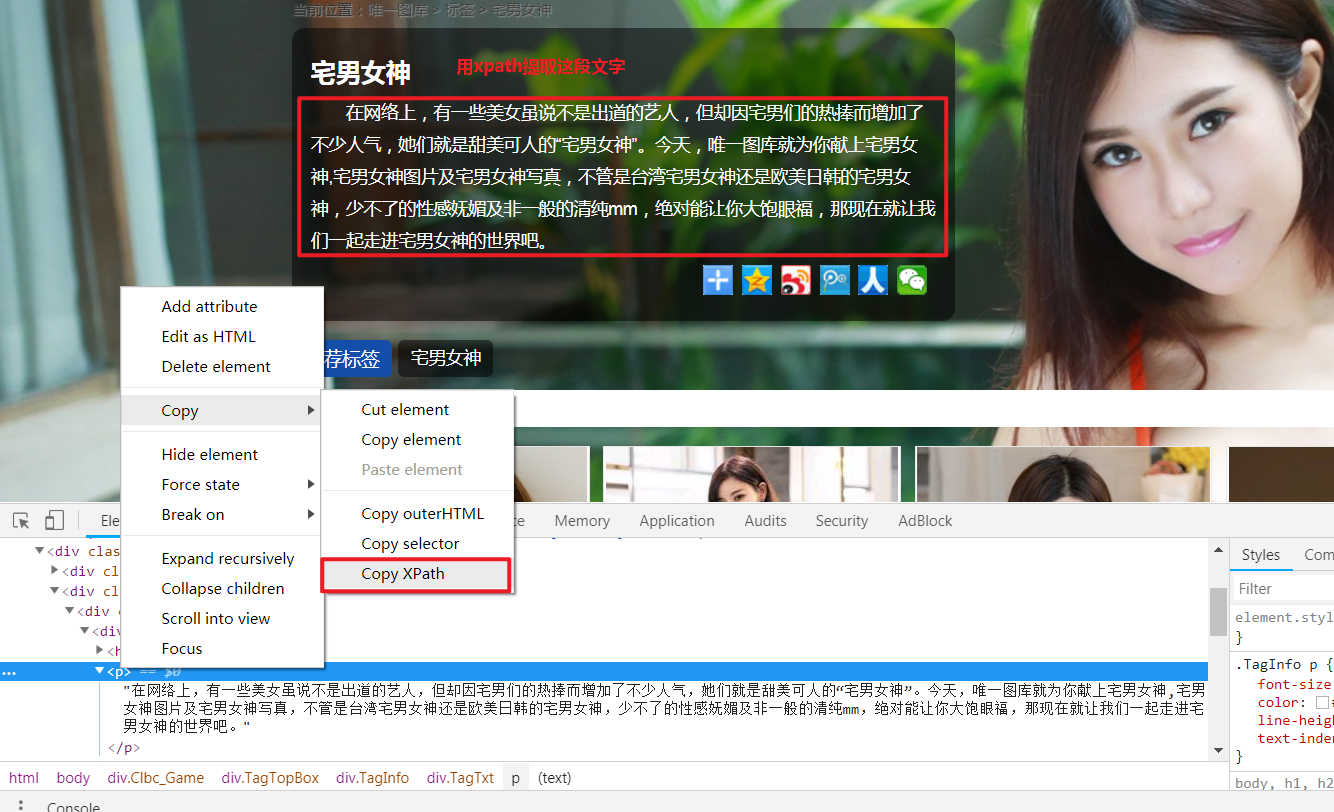
用xpath选择器提取页面信息:
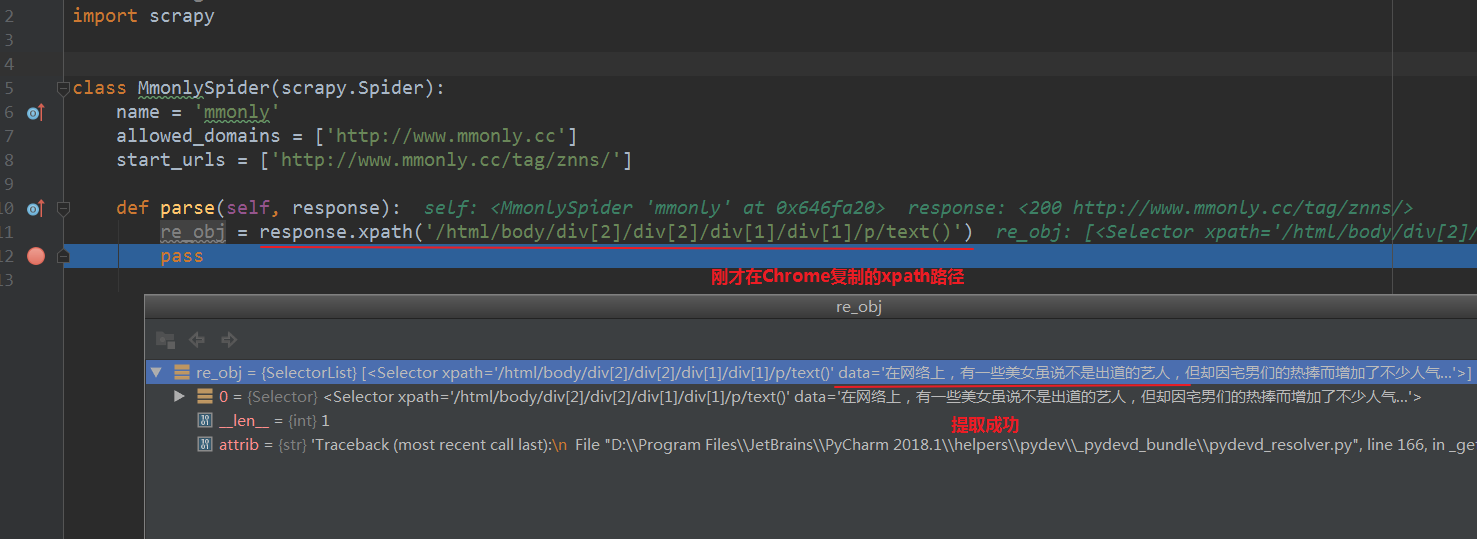
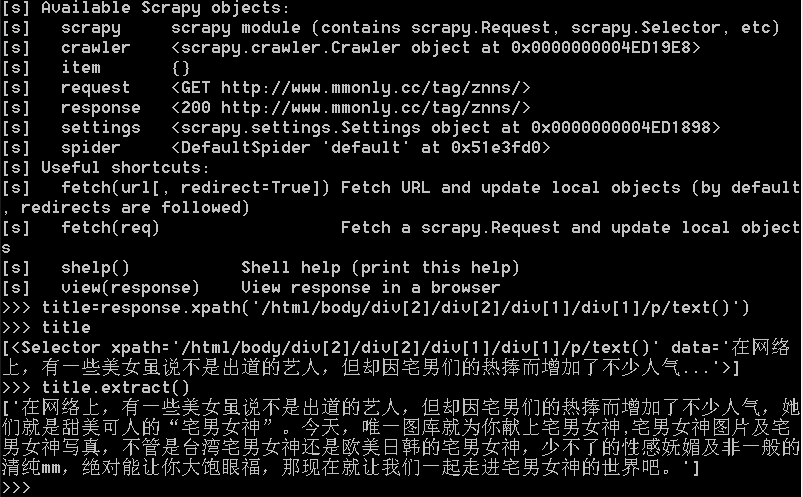
换种更为高效的调试模式,利用cmd:在项目根目录,输入scrapy shell +你需要爬取的页面url

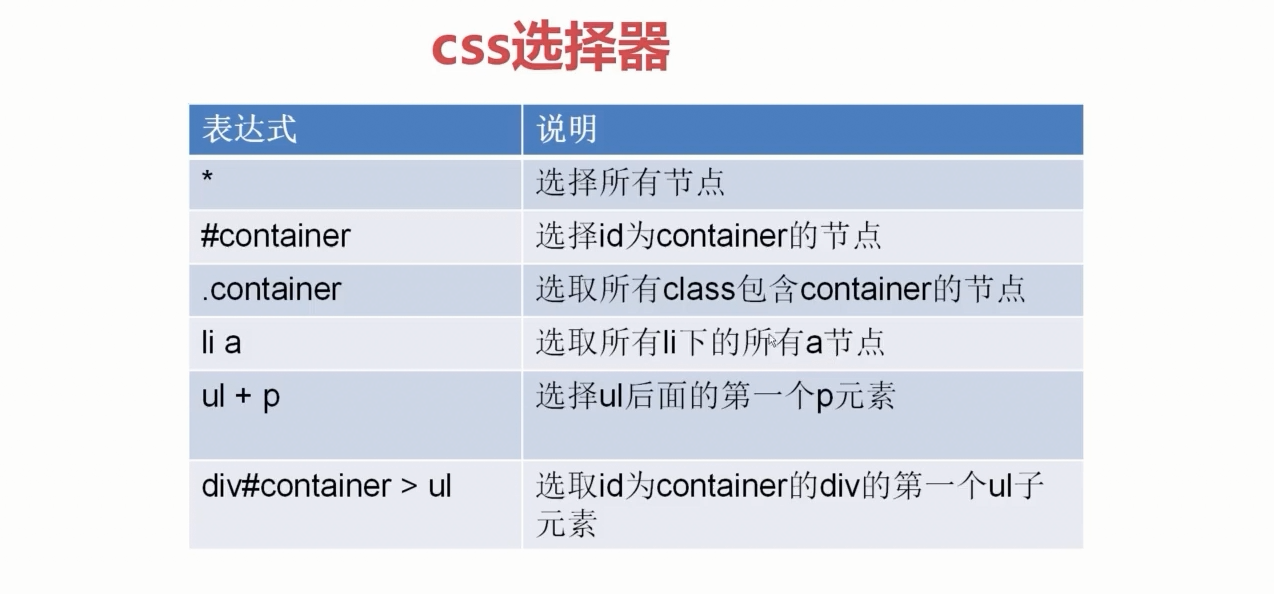
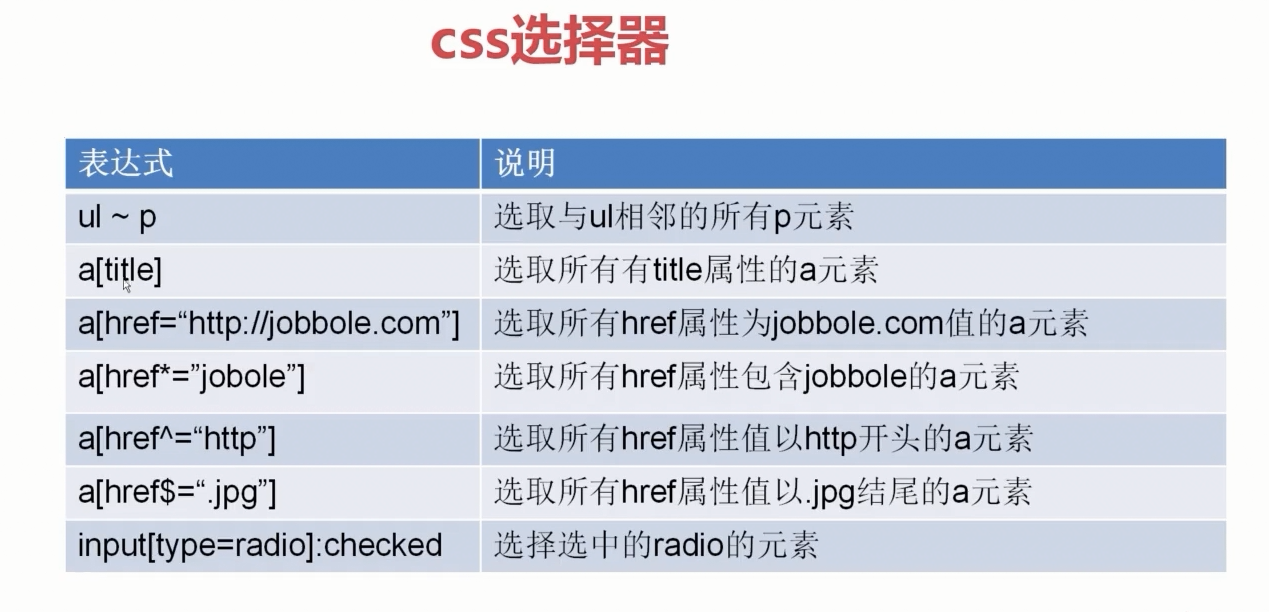
css选择器

用css选择器提取页面信息:
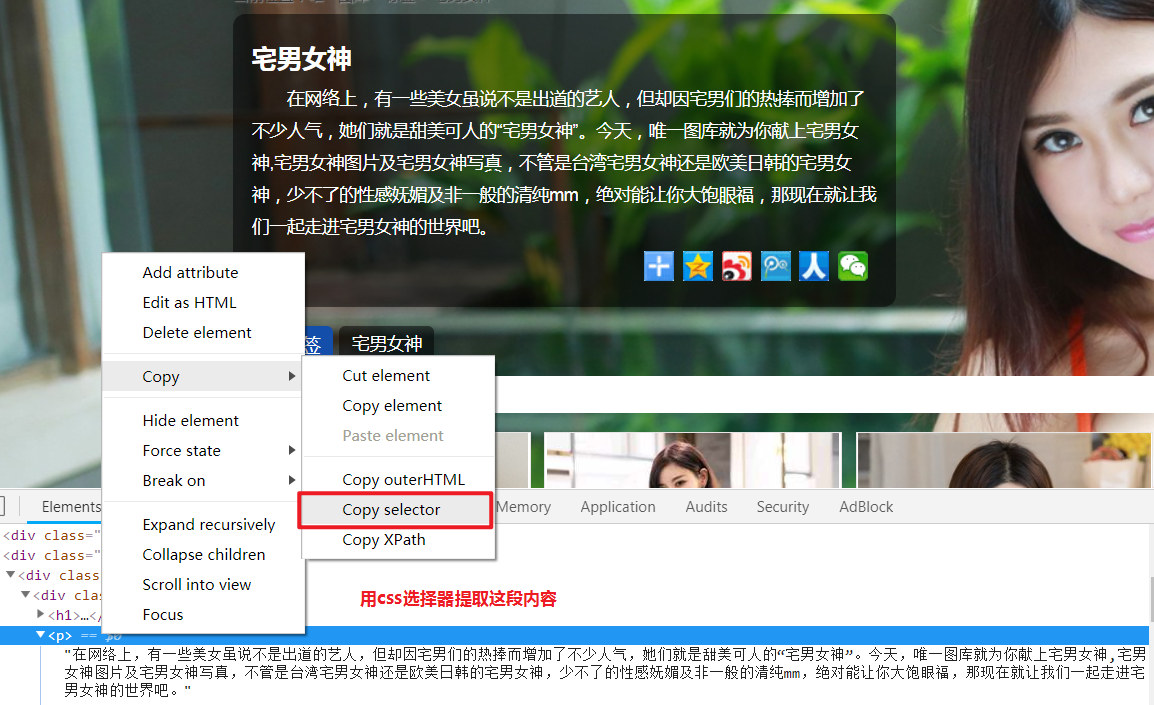
把上面复制的内容去除空格放入response.css(’ ')中:
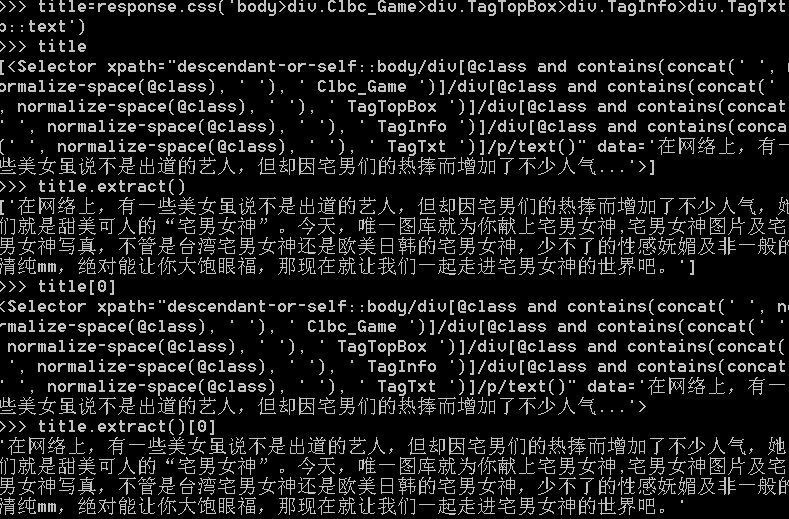
点开第一张图片,我们来用xpath和css提取更多的页面信息:
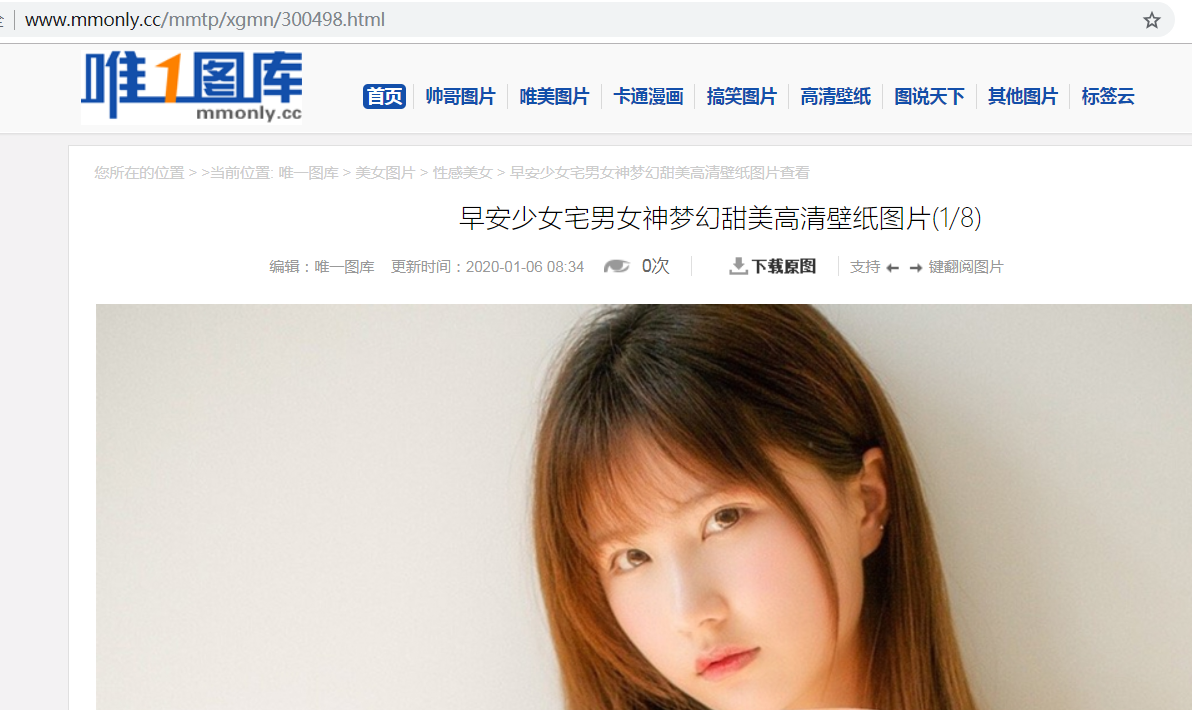
我们需要提取的字段名称:
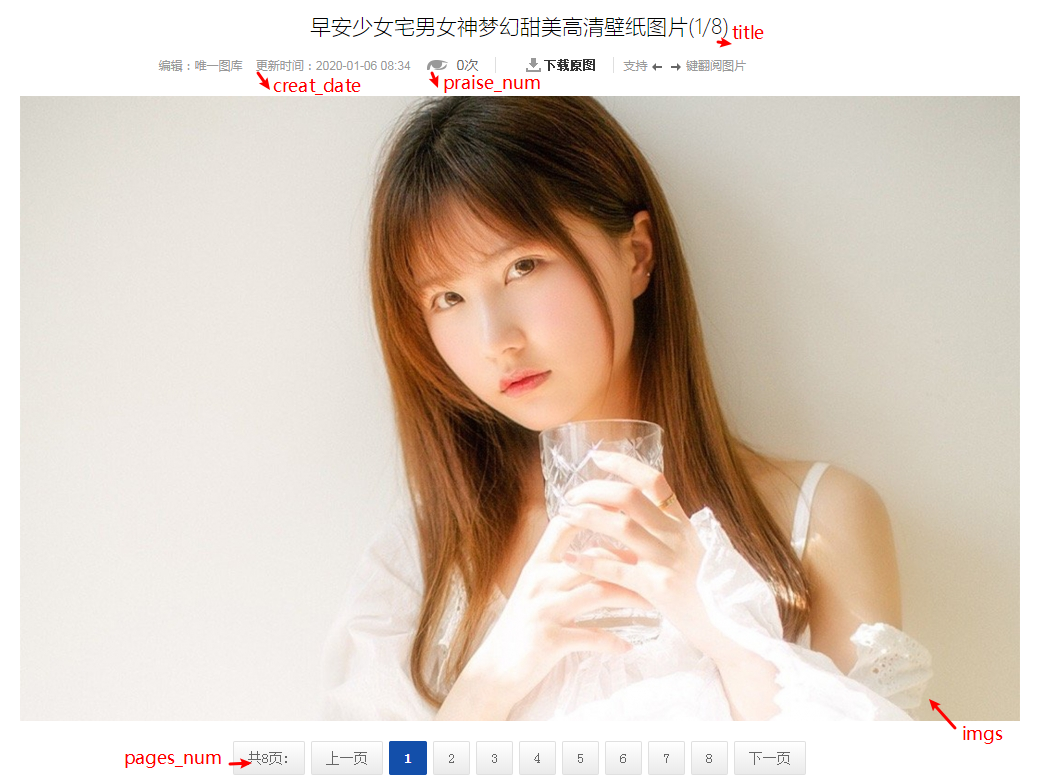
'''
通过xpath提取字段
'''
title=response.xpath('//div[@class="wrapper clearfix imgtitle"]/h1/text()').extract()[0]
create_date=response.xpath("//span[@class='tip']/text()").extract()[0].strip()
match_cd = re.match(".*时间:?(\d{4}[-]\d{2}[-]\d{2}.*\d{2})?.*", create_date)
if match_cd:
create_date = match_cd.group(1)
praise_num=response.xpath("//span[@id='hits']/text()").extract()[0]
match_pn = re.match(".*?(\d+).*", praise_num)
if match_pn:
praise_num = match_pn.group(1)
pages_num=response.xpath("//div[@class='pages']/ul/li[1]/a/text()").extract()[0]
match_pg=re.match(".*?(\d+).*",pages_num)
if match_pg:
pages_num=match_pg.group(1)
imgs=response.xpath('//*[@id="big-pic"]/p/a/img/@src').extract()[0]
'''
通过css提取字段
'''
title=response.css(".wrapper h1::text").extract()[0] # 图片标题
create_date =response.css(".tip ::text").extract()[0] # 创建时间
match_cd = re.match(".*时间:?(\d{4}[-]\d{2}[-]\d{2}.*\d{2})?.*", create_date)
if match_cd:
create_date = match_cd.group(1)
praise_num=response.css("#hits ::text").extract()[0]
match_pn = re.match(".*?(\d+).*", praise_num)
if match_pn:
praise_num = int(match_pn.group(1))
else:
praise_num = 0
pages_num=response.css(".pages ::text").extract()[2]
match_pg = re.match(".*?(\d+).*", pages_num)
if match_pg:
pages_num = int(match_pg.group(1))
else:
pages_num= 0
imgs=response.css("a[href] img::attr(src)").extract()[1]
爬取首页图片列表中的全部图片
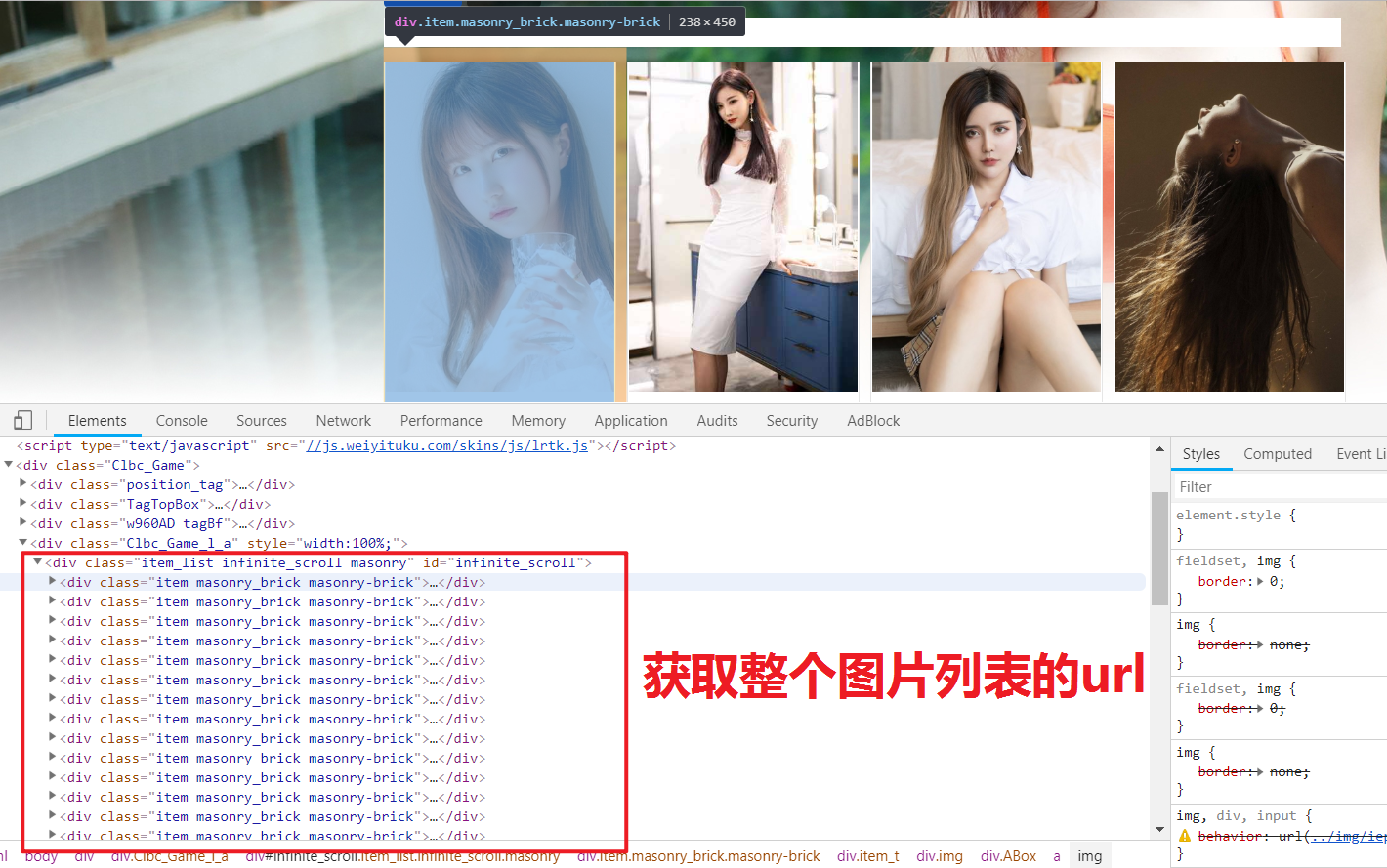
一级首页图片列表共24张图,对应24个url
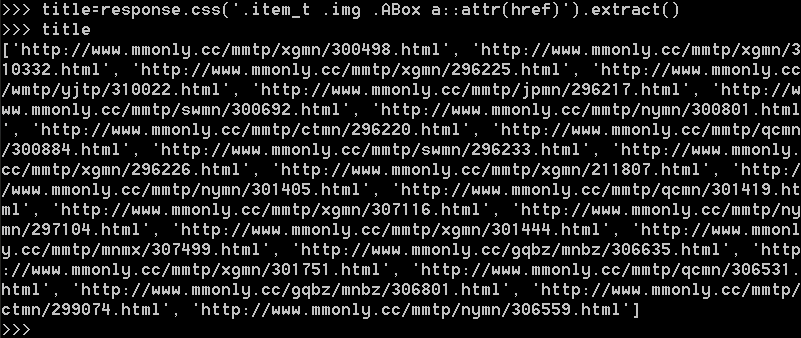
获取一级图片列表页中的下一页url:

next_url = response.css(".pages li:nth-last-child(2) a ::attr(href)").extract()[0] # 一级列表页的下一页
寻找二级详情页中url与页码的规律:

根据规律遍历详情页的url:
pag_num=response.css(".pages li:nth-child(1) a::text").extract()[0]
match_pn = re.match(".*?(\d+).*", pag_num)
if match_pn:
pag_num = int(match_pn.group(1))
for i in [response.url.replace('.html','') + "_{}.html".format(str(x)) for x in range(1, pag_num + 1)]:
if i == response.url.replace('.html','') + "_1.html":
item['Referer'] = i.replace('_1','')
else:
item['Referer'] = i
完整步骤
mmonly.py
def parse(self, response):
'''
一级列表页处理
'''
post_nodes = response.css('.item_t .img .ABox a') # 一级列表页中的图片的所有url列表
for post_node in post_nodes: # 循环遍历url列表 取出二级详情页首页url
post_url = post_node.css("::attr(href)").extract_first("")
yield Request(url=post_url,callback=self.parse_image) # 将二级详情页首页url回调给parse_image函数处理
next_url = response.css(".pages li:nth-last-child(2) a ::attr(href)").extract()[0] # 一级列表页的下一页
if next_url: # 下一页有值 就回调给本函数再次遍历
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
def parse_image(self, response):
'''
二级详情页首页处理
'''
item = PicturespiderItem()
pag_num=response.css(".pages li:nth-child(1) a::text").extract()[0]
match_pn = re.match(".*?(\d+).*", pag_num)
if match_pn:
pag_num = int(match_pn.group(1))
for i in [response.url.replace('.html','') + "_{}.html".format(str(x)) for x in range(1, pag_num + 1)]:
if i == response.url.replace('.html','') + "_1.html":
item['Referer'] = i.replace('_1','')
else:
item['Referer'] = i
yield Request(url=item['Referer'],meta={'meta_1': item},callback=self.parse_detail,dont_filter=True) # 回调给详情页字段提取函数 关闭自动去重
'''
二级详情页字段提取
'''
def parse_detail(self, response):
item = response.meta['meta_1']
image_url = response.css("a[href] img::attr(src)").extract()[1]
title = response.css(".wrapper h1::text").extract()[0]
item["image_url"] = image_url
item["title"] =title
yield item
items.py
class PicturespiderItem(scrapy.Item):
'''
定义item中的字段
'''
title = scrapy.Field()
image_url = scrapy.Field()
image_path = scrapy.Field()
Referer = scrapy.Field()
pipelines.py
# 移动图片
import shutil
import scrapy
# 导入项目设置
from scrapy.utils.project import get_project_settings
# 导入scrapy框架的图片下载类
from scrapy.pipelines.images import ImagesPipeline
import os
class PicturespiderPipeline(ImagesPipeline):
# 获取settings文件里设置的变量值
IMAGES_STORE = get_project_settings().get("IMAGES_STORE")
def get_media_requests(self, item, info):
'''
图片下载请求
'''
image_url = item["image_url"]
#headers是请求头主要是防反爬虫
yield scrapy.Request(image_url,headers={'Referer':item['Referer']})
def item_completed(self, result, item, info):
'''
按二级详情页的图片标题分类保存
'''
image_path = [x["path"] for ok, x in result if ok]
# 定义分类保存的路径
img_path = "%s\%s" % (self.IMAGES_STORE, item['title'])
# 目录不存在则创建目录
if os.path.exists(img_path) == False:
os.mkdir(img_path)
# 将文件从默认下路路径移动到指定路径下
shutil.move(self.IMAGES_STORE + "\\" +image_path[0], img_path + "\\" +image_path[0][image_path[0].find("full\\")+6:])
item['image_path'] = img_path + "\\" + image_path[0][image_path[0].find("full\\")+6:]
return item
setting.py