本文环境:Mac 系统,Python 3.7
准备工作
准备工作主要包括:创建项目虚拟环境、更新 pip 以及安装 Django 模块。
创建项目虚拟环境
首先创建虚拟环境,新建项目文件夹 tedxapi,右键在该文件夹处打开命令行窗口/终端窗口
python -m venv myvenv
这时项目文件夹内出现一个 myvenv 文件夹,执行以下命令启动虚拟环境
source myvenv/bin/activate
此时终端界面命令起始位置会出现 (myvenv) 字样,说明已进入虚拟环境中。
更新 pip
检查下已安装的模块
pip list
结果如下:
Package Version
---------- -------
pip 19.0.3
setuptools 40.8.0
You are using pip version 19.0.3, however version 19.3.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
那就先执行下更新 pip 的命令:
pip install --upgrade pip
安装 Django 模块
接下来继续安装 Django:
pip install django
安装成功后,准备工作完毕。
开始构建 API 框架
新建 Django 项目
首先使用 Django 的命令新建名为 myapi 的项目:
django-admin startproject myapi
这时可以看到 tedxapi 内结构如下:
.
├── myapi
│ ├── manage.py
│ └── myapi
└── myvenv
├── bin
├── include
├── lib
└── pyvenv.cfg
此时 命令行窗口/终端 所处路径是 tedxapi 文件夹,执行如下命令切换到新建的 myapi 文件夹内:
cd myapi
此时查看文件夹内组成,执行 ls 命令确保文件夹内含有 manage.py
执行如下命令启动新建项目:
python manage.py runserver
看到如下提示代表一切进展顺利:
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced).
You have 17 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
Run 'python manage.py migrate' to apply them.
November 18, 2019 - 02:29:05
Django version 2.2.7, using settings 'myapi.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
此时即可在浏览器中打开 http://127.0.0.1:8000/ 来连接此项目,页面中会显示 “The install worked successfully! Congratulations!” 等提示成功的信息。
同时,在命令行/终端窗口中 CONTROL 加 C 键退出该服务器连接,继续后续的配置。
创建具体应用
注意,刚我们创建的是 Django 项目 myapi,接下来我们要在此项目内更具体地创建一个与要在页面中显示内容关联更密切的 Django 模型应用。命令行/终端 中执行以下命令:
python manage.py startapp hotlist
因为我们最终想在 api 中展示热榜信息,所以应用也命名为 hotlist,这时可以看到在 manage.py 附近出现了 hotlist 文件夹, myapi 文件夹内结构如下:
.
├── db.sqlite3
├── hotlist
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── manage.py
└── myapi
├── __init__.py
├── __pycache__
├── settings.py
├── urls.py
└── wsgi.py
此时我们已经新建了应用,需要在 Django 项目中添加此应用信息,用代码编辑器打开 myapi/myapi/settings.py 文件,在 INSTALLED_APPS 最后添加 hotlist 应用:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'hotlist',
]
创建应用中 API 模型
已经有了项目、应用,再具体就是 API 模型——究竟以什么形式保存、展示相关的 API 数据。一旦搭建好模型,Django 就通过此模型连接前端页面展现的数据和后台服务器数据库中储存的 API 数据。
模型的搭建要考虑前端页面要展现的内容,以及数据的来源。以我们接下来要搭建的 知乎热榜 API 为例,我们想在 API 返回的数据中包含哪些数据?我们能通过爬虫拿到哪些数据?这些如果没经验,可以先参考别人做好的 API 格式,例如今日热榜开放的 API 中关于知乎网站返回的 API 数据如下:
https://www.tophub.fun:8080/GetAllInfoGzip?id=1
{"CreateTime":"1574040650",
"Desc":"最新进展:曹雪涛校长回应,查完了会给大家回应。 11 月 15 日起,南开大学校长、中国工程院院士曹雪涛被曝 18 篇论文造假,论文实验图片有 PS 痕迹等消息在网上热传。截止发稿时止,在最初曝出曹雪涛论文造假的国外学术交流在线平台 PubPeer 上,能检索到有上述图像异常、作者署名包括曹雪涛的论文已超过 40 篇。 在这些以曹雪涛为作者或者通讯作者的论文里,出现了两次实验结果图像完全一致;一幅实验图中,局部点图多次「复制、粘贴」,两幅实验图中,部分一致,部分疑似有增添、删减等 PS 操作的现象。《中国新闻周刊》查阅到这 40 多篇论文中的 35 篇,其中曹雪涛担任通讯作者或共同通讯作者的文章有 29 篇。在这 40 多篇文章中,目前有 4 篇被更正勘误,有一篇 2008 年发表于《生物化学杂志》的论文被撤回,该期刊 2018 年的影响因子为 4.106。 对于这些质疑,曹雪涛于 15 日下午回复《中国新闻周刊》时表示,「我现在刚到上海实验室,要把这些事情查一下。我知道大家关注这个事情,查完了,我会给大家一个回复。」 新闻链接:南开大学校长曹雪涛被曝论文造假,本人回应:查完了会有回复 从下图分析,如何判定这个消息的真实性? 事件进展: 11 月 14 日 最先爆出来的是一位科研人员,斯坦福的博士毕业。 据悉,11 月 13 日南开校长曹雪涛还在人民大会堂「 2019 全国科学道德和学风建设宣讲教育报告会」发言。 其中涉及一篇 2014 年的 ScienceSearch publications and join the conversation.",
"Title":"网传南开大学校长曹雪涛院士约 47 篇论文涉嫌数据造假,你如何看待?",
"Url":"https://www.zhihu.com/question/355811571",
"approvalNum":"0",
"commentNum":"1",
"hotDesc":"",
"id":"653211",
"imgUrl":""}
我们也以此为模型先迈出第一步,打开 hotlist/models.py 并编辑一个包含上述结构的 class 并保存:
# hotlist/models.py
from django.db import models
class Website(models.Model):
CreateTime = models.CharField(u'时间',max_length=50)
Desc = models.CharField(u"描述",max_length=50)
Title = models.CharField(u'标题',max_length=50)
Url = models.CharField(u'链接', max_length=50)
approvalNum = models.CharField(u'点赞', max_length=50)
commentNum = models.CharField(u'评论', max_length=50)
hotDesc = models.CharField(u'热评', max_length=50)
idWeb = models.CharField(u'编号', max_length=50)
imgUrl = models.CharField(u'图片', max_length=50)
def __str__(self):
return self.Title
(由于直接使用 id 会导致后续报错,倒数第二个属性采用了 idWeb 名称)
可以看到,最开始的 from … import … 语句在 django.db 即数据库中导入了 models 模型,我们定义的 Website 通过继承了该模型,并在其内定义了我们想要的 9 个属性。最结尾的 str 定义指明了当通过该模型新建实例时可以打印的关于该模型的内容。
现在我们添加了新的模型,模型是连接数据库和前端数据的,那么需要将该模型添加到数据库中。保存代码编辑器中对 hotlist/models.py 的修改,接下来返回到 命令后/终端 窗口中,执行以下命令:
python manage.py makemigrations
可以看到如下关于新建模型的提示信息:
Migrations for 'hotlist':
hotlist/migrations/0001_initial.py
- Create model Website
然后执行如下命令,使 Django 完成对数据库的操作:
python manage.py migrate
可以看到如下结果:
Operations to perform:
Apply all migrations: admin, auth, contenttypes, hotlist, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying admin.0003_logentry_add_action_flag_choices... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying auth.0010_alter_group_name_max_length... OK
Applying auth.0011_update_proxy_permissions... OK
Applying hotlist.0001_initial... OK
Applying sessions.0001_initial... OK
至此,一切顺利,模型也已经被部署在数据库中了!
添加后台管理
目前我们只将模型应用到数据库中,接下来要将其和前端页面绑定,即通过前端页面可以通过该模型向后台添加、修改数据。在我们建立项目时,Django 已经为项目配备了 admin 管理页面和功能,我们要在此基础上完善。
在 hotlist/admin.py 中将我们新建的 API 模型进行注册:
from django.contrib import admin
from .models import Website
admin.site.register(Website)
至此,我们还差一步:刚提到项目有 admin 管理功能,但我们还没有设置拥有管理权限的账户。在终端中输入以下命令:
python manage.py createsuperuser
根据提示输入用户名、邮箱地址、密码及再次确认密码:
Username (leave blank to use 'ted'): tedxpy
Email address:
Password:
Password (again):
Superuser created successfully.
注意:输入密码时,终端中没有任何动静,这是正常的,它会让我们再次输入密码进行比对确认,如果正常最终会提示 “Superuser created successfully.”
下面仍然通过命令启动服务器:
python manage.py runserver
此时进入 http://127.0.0.1:8000/ 页面与之前并无不同,但我们将地址改为 http://127.0.0.1:8000/admin 即可进入管理登陆页面,使用刚创建的账户登入,可以看到如下页面:
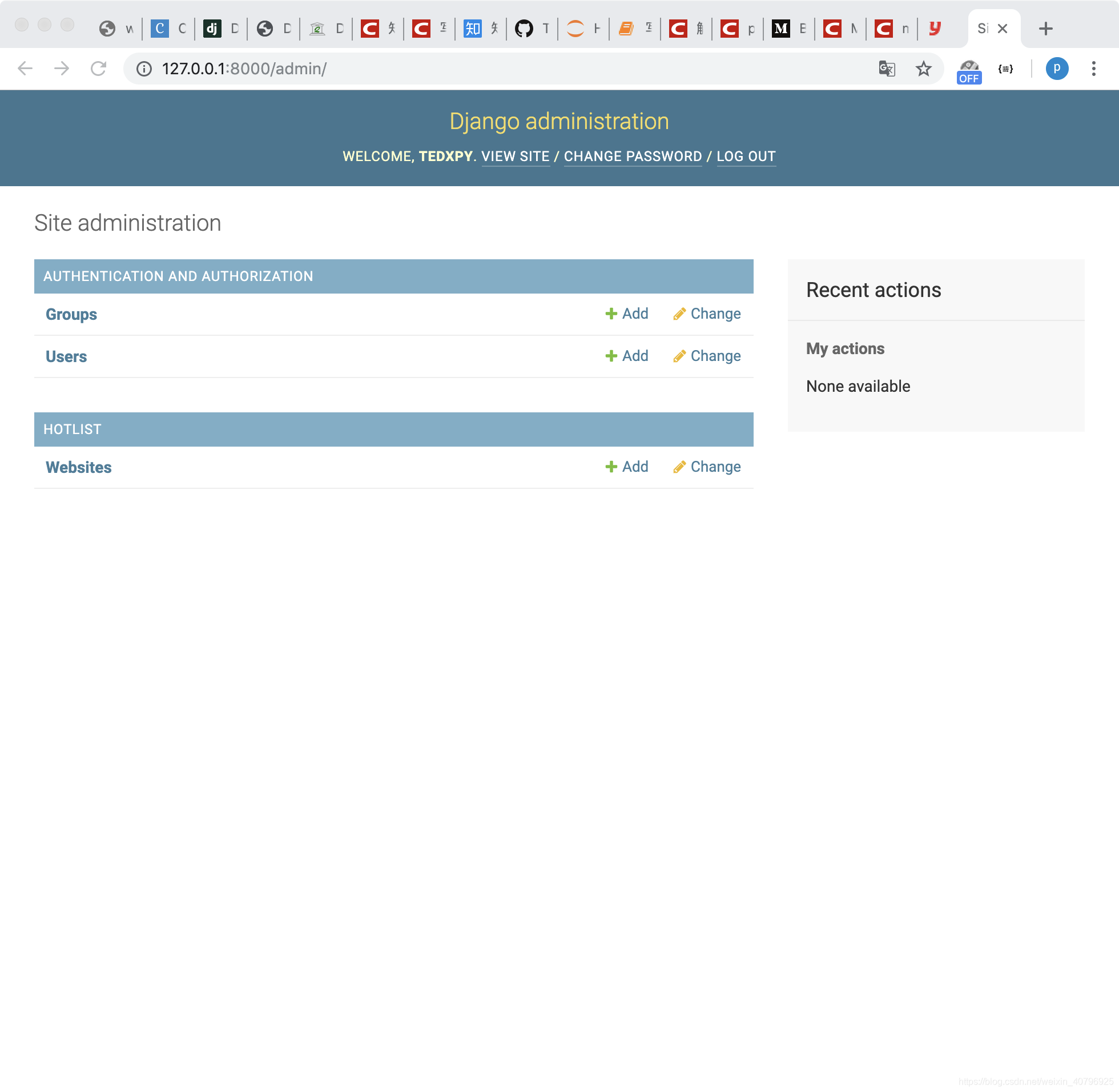
页面中可以看到我们新建的 HOTLIST(应用)和 Website(模型),点击 Website 右侧的 Add,新页面如下:
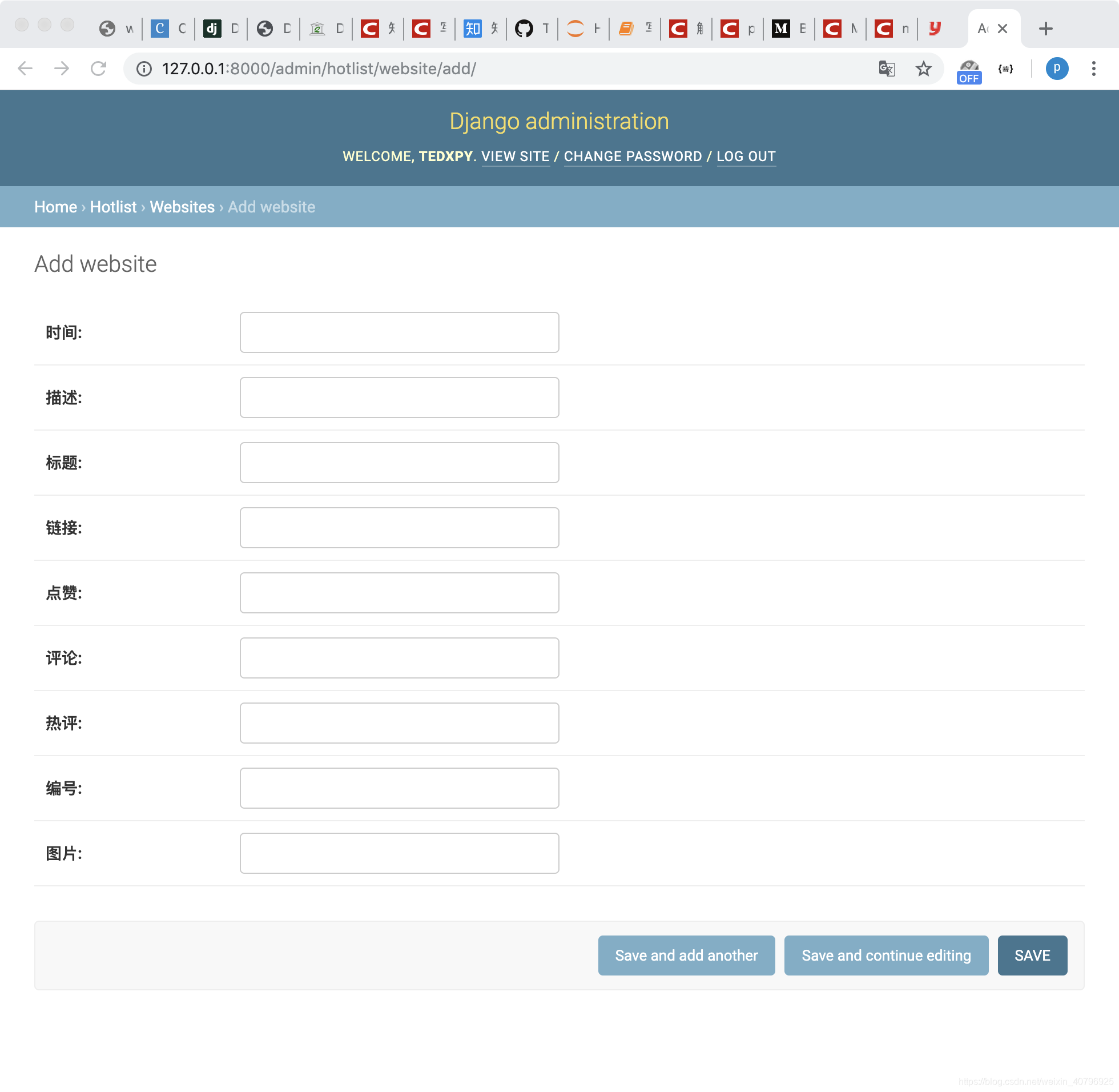
可以看到,我们在模型中定义的 9 个字段都显示在了页面中,我们可以随意输入保存,那么输入的内容将会作为一条 API 模型的数据存入数据库。
安装 REST Framework
我们采用 Django REST Framework 来实现我们的 API 展现,如果我们的终端还处于运行服务器状态中,运行 CONTROL 加 C,转到 (myvenv) 模式下的命令行,通过 pip 安装 Django REST Framework:
pip install djangorestframework
同时在 myapi/myapi/settings.py 中 INSTALLED_APPS 里添加 ‘rest_framework’:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'hotlist',
'rest_framework',
]
模型序列化
接下来我们要将搭建好的模型与 REST Framework 联系起来,通过其将模型数据给序列化处理。在 hotlist 文件夹中新建 serializers.py 文件,打开编辑代码如下:
# hotlist/serializers.py
from rest_framework import serializers
from .models import Website
class WebsiteSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Website
fields = ('CreateTime','Desc','Title','Url','approvalNum','commentNum','hotDesc','idWeb','imgUrl')
展示数据
现在模型中的数据通过 REST Framework 完成序列化,接下来我们要实现数据在页面上的绑定。在本项目中,hotlist/views.py 掌控了页面内容,代码编辑器打开该文件:
from django.shortcuts import render
from rest_framework import viewsets
from .serializers import WebsiteSerializer
from .models import Website
class WebsiteViewSet(viewsets.ModelViewSet):
queryset = Website.objects.all()
serializer_class = WebsiteSerializer
记得保存!继续配置页面路径,先打开 myapi/myapi/settings.py 修改以下代码:
# myapi/myapi/settings.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('hotlist.urls')),
]
再进入 hotlist 文件夹新建 urls.py 文件,打开编辑代码如下:
# hotlist/urls.py
from django.urls import include, path
from rest_framework import routers
from . import views
router = routers.DefaultRouter()
router.register(r'website',views.WebsiteViewSet)
urlpatterns = [
path('', include(router.urls)),
path('api-auth/', include('rest_framework.urls', namespace='rest_framework'))
]
至此,API 的配置已完成,可以在终端输入以下命令启动 Django 服务器来体验下效果了:
python manage.py runserver
这次页面有了内容:
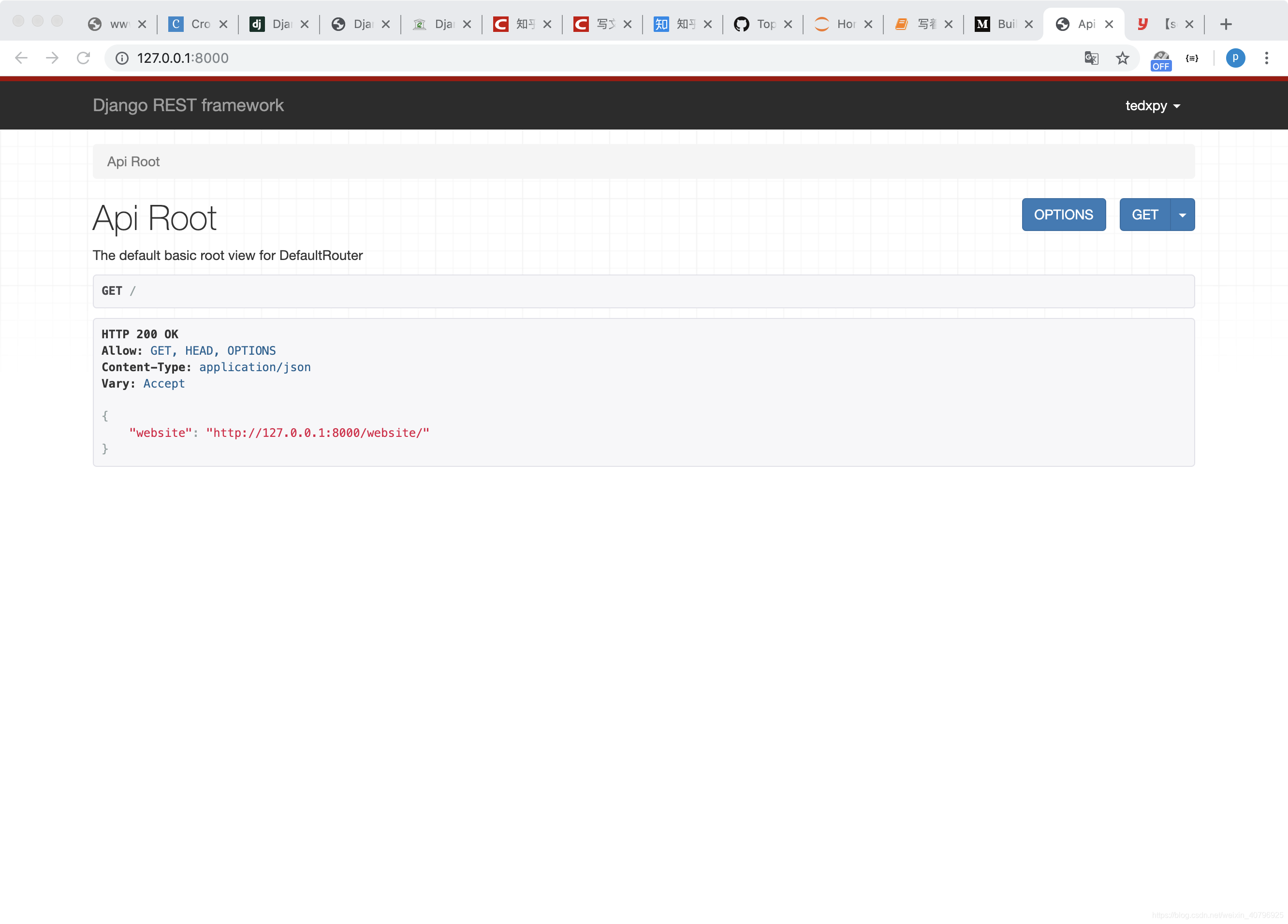
根据页面提示,我们在访问地址最后加上 /wenbsite,即 http://127.0.0.1:8000/website/ 重新载入,即可看到数据库中返回的数据信息。
设置权限
但是现在有个问题,无论是否登陆,我们都可以向其中添加数据,这个是不对的。当未登录时,应该只允许查看数据;已登陆状态下才可以向其中添加数据。
打开 myapi/myapi/settings.py 在最后位置添加如下代码:
# myapi/myapi/settings.py
REST_FRAMEWORK = {
# Use Django's standard `django.contrib.auth` permissions,
# or allow read-only access for unauthenticated users.
'DEFAULT_PERMISSION_CLASSES': [
'rest_framework.permissions.DjangoModelPermissionsOrAnonReadOnly'
]
}
此时再去看 http://127.0.0.1:8000/website/ 页面,未登录时只读不可编辑数据了。(可通过页面右上角切换登陆状态)
抓取数据存入数据库
目前看来,只差数据源了,即获取我们想要搭建的 知乎热榜 API 其要包含的数据。我们基于之前的文章来爬虫获取知乎热榜数据。
因为爬到的数据要存入 Django 项目的数据库并通过 API 展示,我们在 tedxapi/myapi 文件夹下新建 get_website.py 文件,该文件与 manage.py 位于相同目录。打开get_website.py 编辑代码如下:
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "myapi.settings")
import django
if django.VERSION >= (1,7):
django.setup()
import requests
import re
from bs4 import BeautifulSoup
def get_zhihu():
headers={"User-Agent":"","Cookie":""}
zh_url = "https://www.zhihu.com/billboard"
zh_response = requests.get(zh_url,headers=headers)
webcontent = zh_response.text
soup = BeautifulSoup(webcontent,"html.parser")
script_text = soup.find("script",id="js-initialData").get_text()
rule = r'"hotList":(.*?),"guestFeeds"'
result = re.findall(rule,script_text)
temp = result[0].replace("false","False").replace("true","True")
hot_list = eval(temp)
return hot_list
if __name__ == '__main__':
from hotlist.models import Website
import time
ted = get_zhihu()
Website.objects.all().delete()
count = 0
for item in ted:
count+=1
Website.objects.get_or_create(CreateTime=int(time.time()), Desc=item['target']['excerptArea']['text'], Title=item['target']['titleArea']['text'],Url=item['target']['link']['url'], approvalNum="0", commentNum=str(item['feedSpecific']['answerCount']), hotDesc=item['target']['metricsArea']['text'], idWeb=str(count), imgUrl=item['target']['imageArea']['url'])
print("done")
代码中,在定义爬知乎相关部分之前,我们先导入并配置 Django 环境。通过 get_zhihu() 函数我们获取到知乎热榜相关数据。在 main 主流程中,导入 Website 模型及其查询集(QuerySets),通过 Website.objects 相关命令 delete() 清空数据库、get_or_create() 命令向其中增加字段数据。此过程通过 Django ORM 来实现。
运行该代码,如果不报错正常执行,那么爬虫得到的批量数据将会成功导入数据库了!此时登陆 http://127.0.0.1:8000/website/ 即可看到 API 数据展示:
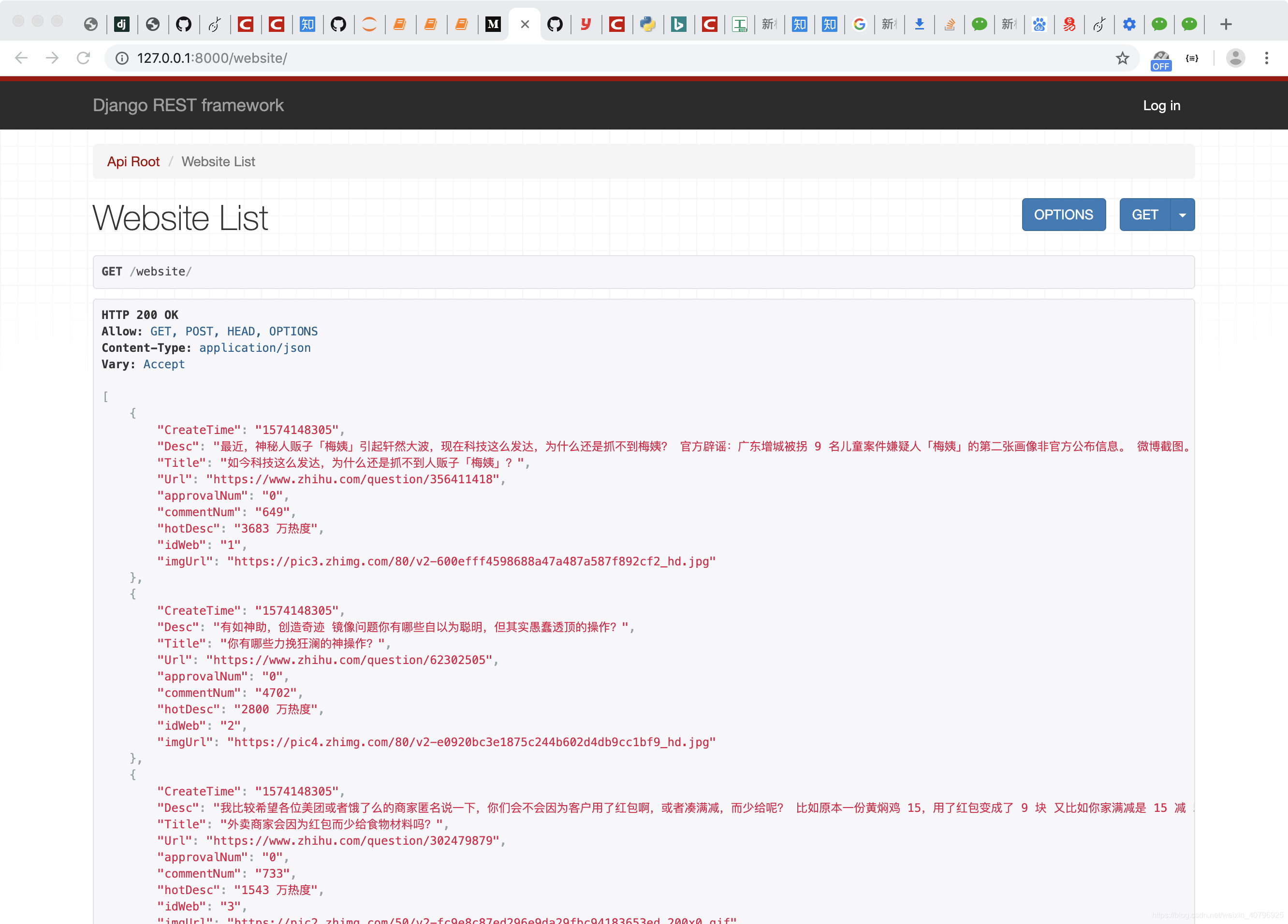
至此,知乎热榜 API 本地的搭建完成了!后续我们再尝试将其部署到外网服务器上~
以上,感谢阅读,也向你推荐我个微信公众号 TEDxPY,记录分享学习 Python 路上成长趣闻,有问题和建议也非常欢迎!

文章参考链接:
- https://wechat.python666.cn/static/djangogirl/djangogirl.html?page=1
