为什么会产生哈希冲突
因为输入数据长度不固定,而输出的哈希值却是固定长度的,这意味着哈希值是一个有限集合,而输入数据则可以是无穷多个,那么建立一对一关系明显是不现实的,所以“碰撞”是必然会发生的.。
为什么要用hashCode
hashCode()是不可靠的。那它不可靠为什么还要用它?因为它快!
两个对象之间的比较:
- equals()相等的两个对象他们的hashCode()肯定相等,也就是用equals()对比是绝对可靠的。
- hashCode()相等的两个对象他们的equal()不一定相等,也就是hashCode()不是绝对可靠的。
HashMap简介
- HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置。当程序执行 map.put(String,Obect)方法 时,系统将调用String的 hashCode() 方法得到其 hashCode 值。
- 每个 Java 对象都可以通过 hashCode() 方法获得它的hashCode 值。得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置。
HashMap如何解决hash冲突
- 散列表要解决的一个问题就是散列值的冲突问题,通常是两种方法:链表法和开放地址法。HashMap采用的是链表法。
- 它有一个桶的概念:对于Entry数组而言,数组的每个元素处存储的是链表,而不是直接的Value。在链表中的每个元素才是真正的<Key, Value>。而一个链表,就是一个桶!因此HashMap最多可以有Entry.length个桶。
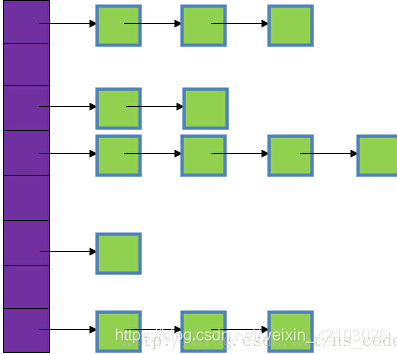
图中,紫色部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
threshold(临界值)和 load factor(加载因子)
threshold(临界值):
- 当实际大小超过临界值时,会进行扩容。
- threshold = 加载因子*容量。
load factor(加载因子):
- 这是时间和空间成本上一种折衷,默认值0.75
- 负载因子越大,填满的元素越多,好处是,空间利用率高了,但冲突的机会加大了,链表长度会越来越长,查找效率降低。
- 负载因子越小,填满的元素越少,好处是:冲突的机会减小了,但空间浪费多了,表中的数据将过于稀疏(很多空间还没用,就开始扩容了)
