分析Node的代码前,需要理解Node的工作机制,需要先了解其工作原理:
https://github.com/alibaba/otter/wiki/Otter调度模型
这里用到了SEDA模型,SEDA模型这里有偏文章介绍的很好:
https://www.jianshu.com/p/e184fdc0ade4
下面就是Otter-Node模块的工作流程图

说明:
otter通过select模块串行获取canal的批数据,注意是串行获取,每批次获取到的数据,就会有一个全局标识,otter里称之为processId.
select模块获取到数据后,将其传递给后续的ETL模型. 这里E和T模块会是一个并行处理
将数据最后传递到Load时,会根据每批数据对应的processId,按照顺序进行串行加载。 ( 比如有一个processId=2的数据先到了Load模块,但会阻塞等processId=1的数据Load完成后才会被执行)
简单一点说,Select/Load模块会是一个串行机制来保证binlog处理的顺序性,Extract/Transform会是一个并行,加速传输效率.
并行度
类似于tcp滑动窗口大小,比如整个滑动窗口设置了并行度为5时,只有等第一个processId Load完成后,第6个Select才会去获取数据。
数据可靠性
如何保证数据不丢:2pc. (get/ack)
如何处理重传协议:get/ack/rollback
如何支持并行化:多get cursor+ack curosr (可以参看Canal的异步ACK模型)
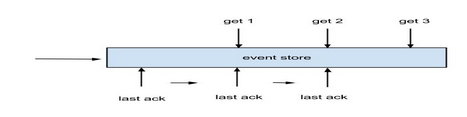

说明: 将并行化调度的串行/并行处理,进行隐藏,抽象了await/single的接口,整个调度称之为仲裁器。(有了这层抽象,不同的仲裁器实现可以解决同机房,异地机房的同步需求)
模型接口:
await模拟object获取锁操作
notify被唤醒后提交任务到thread pools
single模拟object释放锁操作,触发下一个stage
这里使用了SEDA模型的优势:
共享thread pool,解决流控机制
划分多stage,提升资源利用率
统一编程模型,支持同机房,跨机房不同的调度算法
仲裁器算法
主要包括: 令牌生成(processId) + 事件通知.
令牌生成:
基于AtomicLong.inc()机制,(纯内存机制,解决同机房,单节点同步需求,不需要多节点交互)
基于zookeeper的自增id机制,(解决异地机房,多节点协作同步需求)
事件通知: (简单原理: 每个stage都会有个block queue,接收上一个stage的single信号通知,当前stage会阻塞在该block queue上,直到有信号通知)
block queue + put/take方法,(纯内存机制)
block queue + rpc + put/take方法 (两个stage对应的node不同,需要rpc调用,需要依赖负载均衡算法解决node节点的选择问题)
block queue + zookeeper watcher ()
负载均衡算法:
Stick : 类似于session stick技术,一旦第一次选择了node,下一次选择会继续使用该node. (有一个好处,资源上下文缓存命中率高)
Random : 随机算法
RoundRbin : 轮询算法
注意点:每个node节点,都会在zookeeper中生成Ephemeral节点,每个node都会缓存住当前存活的node列表,node节点消失,通过zookeeper watcher机制刷新每个node机器的内存。然后针对每次负载均衡选择时只针对当前存活的节点,保证调度的可靠性。
Node模块代码详解:
一、canal
1.communication
注:canal大家应该都不陌生,主要作用是将自己伪装成一个Mysql从库,拉取Mysql主库binlog信息,实时同步增量数据。
这个模块依赖了canal的一些代码
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.instance.manager</artifactId>
<version>${otter_canal_version}</version>
<exclusions>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.parse</artifactId>
<version>${otter_canal_version}</version>
<exclusions>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.server</artifactId>
<version>${otter_canal_version}</version>
<exclusions>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
</exclusion>
</exclusions>
</dependency>
CanalCommmunicationClient类
–callManager方法,对List 中的地址进行调用
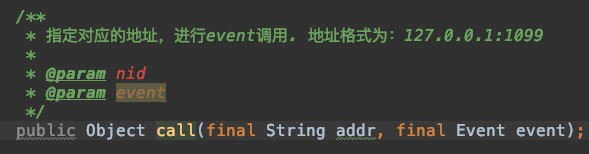
这里调用的地址,为Manager地址和端口,这个地址在node的主配置文件otter.properties里可配:
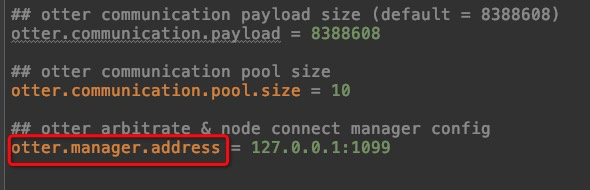
这个类主要是对Manager http接口的调用,然后manager再调用canal
CanalConfigClient类也是类似,封装的主要是为了获取canal的状态信息,包含以下接口:
- findCanal --根据对应的destinantion查询Canal信息
- findFilter --根据对应的destinantion查询filter信息
2.ha
AuthenticationInfoUtils
MediaHAController 继承 AbstractCanalLifeCycle
start()方法:主要检测数据库Master节点是否发生变更,如果发生变更,触发回调


二、common模块
1、communication
2、config
3、statistics
三、deployer模块
Otter-Node节点的启动类,主配置文件都在这个模块下。
四、etl模块
etl模块大概是otter里面最核心也最复杂的代码了,S.E.T.L功能模块:

SETL四个模块通过pipe进行交互
1、common
-
datasource

连接池配置在这里,一般32个连接也足够满足需求了。
这里实际上Otter是利用canal将binlog同步出来,然后拼装成SQL,然后插入目标库 -
db
1、dialect:
mysql:
MysqlDialect类:继承自AbstractDbDialect

初始化一个sqlTemplate,并注入了jdbcTemplate、Mysql版本号,库名等。重点在于这个MysqlTemplate,这个类里面有个方法叫:getMergeSql()如下:

根据Canal解析出的列名,字段名,数据等,拼装成SQL插入到目标库。
oracle略
2、lob:getJdbcExtractor():根据数据源的名称,node拿到不同的jdbc Connection,Statement用于执行SQL。
3、utils:DdlUtils类:SQL解析,使用Druid(阿里开源连接池)中的SQL解析器 -
io
1、compress
提供了各种文件、流、字节数组间的转换方法
2、crypto
加密算法,对byte[]数据进行加解密
3、download
otter支持了静态文件的上传同步功能,这里是文件的方法实现,想使用这个功能,还需要系统安装aria2(需要高版本gcc编译)
4、signature
主要是校验数据完整性的一些接口,CRC校验(32位) -
jetty
-
jetty的嵌入式启动入口
-
jmx
1、JmxConnectorServerFactoryBean继承Spring的:ConnectorServerFactoryBean
spring为将bean提供为mbean,用于外接监控提供了现成的方法。这里的jmx端口,默认为服务端口+1

-
pipe
-
task
GlobalTask --S、E、T、L 的主线程
成员变量


sendRollBackTermin:发送回滚命令,这里将TerminType.ROLLBACK包裹成事件,调用single方法回滚,single有三种实现:

基于仲裁器、基于内存、基于zk的三种实现。
调用single会调用仲裁器的single方法

仲裁器会根据pipelineId,来选择一种仲裁模式chooseMode

这里很明显,如果Node节点为跨机房部署(双活需求),那仲裁模式肯定是RPC调用方式。如果Node节点既承担从canal拉取数据抽取,转换,又承担插入目标库的角色,那么一台Node,内存模式的仲裁即可。
基于内存版的Termin信号处理,查看类:TerminMemoryArbitrateEvent

MemoryStageController中的 BlockingQueue termins;
TeminEventData「
NORMAL,
WARNING,
ROLLBACK,
RESTART,
SHUTDOWN
」
所有的TeminEventData事件,都向这个队列里插。不管正常还是回滚。
上面调用termin后:


replys数据结构:Map
key:StageType(S|T|E|L) value:ReplyProcessQueue
S、T、E、L每个模块都对应一个队列ReplyProcessQueue,这个自定义队列内部又封装了一个PriorityQueue tables 里面存着 处理事件的id->processId
initSelect从replys队列中取出select队列,然后根据pipelineId取出并行度,并行度是指数据从canal中同步出来后,会并发的进行抽取转换,然后并发插入目标库,提高同步效率。
当select的队列小于并行度,并且并行度>0,则将处理id+1插入selectId,
2、conflict
处理冲突模块(暂时略)
3、extract
ExtractTask extends GlobalTask



基于内存的仲裁者实现如下 (*重点来了):

4、load
LoadTask extends GlobalTask
和ExtractTask类似,启动个线程,阻塞到pipeline await

5、model.protobuf
基于protobuf的流转化
6、select
内嵌canal,从DB拉取数据,
- CanalEmbedSelector类的start()方法,为canal同步的初始化代码,最终调用CanalServerWithEmbeded的start()方法启动(canal有内嵌式,和独立部署式,这里用内嵌式canal)
- CanalFilterSupport类主要为otter的过滤方法,同步哪些数据,不同步哪些数据,在Manager配置的表达式,都在这里过滤
- OtterDownStreamHandler类主要功能负责canal -store模块的数据输出处理。canal分为三个主要的模块,parse,sink,store,parse主要负责解析binlog,sink负责数据转发,store模块负责数据的归属,原生的canal,store模块用了内存模式的RingBuffer,也有人改造store模块,用消息队列来存储,Otter这里为了和SEDA模型的线程处理整合,做了额外的特殊的处理,继承了AbstractCanalEventDownStreamHandler,重写了before,retry,after接口,before接口里,考虑了故障场景的同步初始化。


7、transform
S、E、T、L模块,各有一个主线程,分别叫做:
SelectTask
ExtractTask
TransformTask
LoadTask
每个Task都继承自GlobalTask,每个Task内部都有一个线程池
每个线程的处理逻辑如下:
while(true){
blockingQueue.get();
thread{
1.处理Task(S、E、T、L)
2.处理完通知下一个模块(向下一个blockingQueue插入通知)
}
executorService.execute(thread);
}
整体S、E、T、L是由OtterController类进行维护,实时接收manager推送的NodeTask调度信息。
OtterController内部维护这样一个数据结构:
Map<Long, Map<StageType, GlobalTask>> controllers ;
第一层:key :pipeline-ID
第二层:key:S、E、T、L模块,value:S、E、T、L对应的GlobalTask(线程池)
故,每个同步任务由一个pipeline负责,而每个pipleline又分为S、E、T、L处理模块处理。
