In this blog, we are going to know some commands related with I/O, and it is called I/O redirection. The I/O stands for “input and output” . You can redirect the input and output of commands to and from file by its facility, and you can connect multiple commands together into powerful command pipelines. Those commands are below.

- Standard input, output and error
1.1. The output of programs often consist of two types. First, the data the programis designed to produce ,and second, we have status and error messages that tell us how the program is getting along.
keeping with the Unix theme of “everything is a file”, programs such as “ls” actually send their results to a special file called standard output (stdout) and their stauts messages to another file called standard error (stderr). By default, both standard output and standard error are linked to the screen and not saved into a disk file.
In addition, many programs take input from a facility called standard input (stdin) whihc is, by default, attached to the keyboard.
I/O redirection allows us to change where output goes and where input comes from.
1.2. Redirecting standard output : “>”
I/O redirection allows us to redefine where standard output goes. To redirect standard output to another file besides the screen, we use the “>” redirection operator followed by the name of the file.
e.g. Tell the shell to send the output of “ls” command to the file, ls-output.txt, instead of the screen:

see the content of this file :


If we change to a error directory, see what’s happen.

The contend of the file is gone since “nothing” is send to the file from the “stdout”(the file now is empty.), error messages are sent to the “stderr” file. Finally, the contend of stderr is shown on the screen.
So, if we ever need to actually truncate a file (or create a new, empty file) we can use a trick like this:

if we want to append redirected output to a file instaed of overwriting the file, we can use the “>>” redirection operator.

1.3. Redirecting standard error :
While we have referred to the first three of these file streams as standard input, output and error, the shell references them internally as file descriptors zero, one and two, respectively. The shell provides a notation for redirecting files using the file descriptor number. Since standard error is the same as file descriptor number two, we can redirect standard error with this notation.
e.g. The file descriptor “2” is placed immediately before the redirection operator to perform the redirection of standard error to the file stderrTest.txt.

1.4. Redirecting standard output and standard error to one file :
There are two ways to do this. First, the traditional way, which works with versions of the shell:
e.g. 
Recent versions of bash provide a second, more streamlined method fro performing this combined redirection:
e.g.

1.5. Disposing of unwanted output :
Sometimes “silence is golden,” and we don’t want output from a command, we just want to throw it away. This applies particularly to error and status messages. The system provides a way to do this by redirecting output to a special file called “/dev/null”. This file is a system device called a bit bucket which accepts input and does nothing with it.
e.g. To suppress error messages from a command :

Tips:

1.6. Redirecting standard input :
1.6.1. Concatenate files : “cat”
The cat command reads one or more files and copies them to standard output.
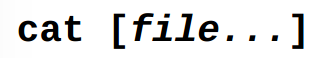
e.g. 
Tips: Since cat can accept more than one file as an argument, it can also be used to join files together. Say we have downloaded a large file that has been split into multiple parts (multimedia files are often split this way on USENET), and we want to join them back together.
1.6.2.
In the absence of filename arguments, cat copies standard input to standard output, so we see our line of text repeated. We can use this behavior to create short text files. Remember to type Ctrl-d at the end.
e.g.
1.6.3. Redirecting standard input by “cat”, “<” :
Using the “<” redirection operator, we change the source of standard input from the keyboard to the file lazy_dog.txt. We see that the result is the same as passing a single filename argument. This is not particularly useful compared to passing a filename argument, but it serves to demonstrate using a file as a source of standard input.
e.g. 
- Pipelines : “|”
The ability of commands to read data from standard input and send to standard output is utilized by a shell feature called pipelines. Using the pipe operator “|” (vertical bar), the standard output of one command can be piped into the standard input of another.
Usage :
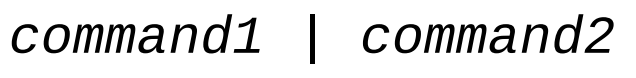
e.g. We can use less to display, page-by-page, the output of any command that sends its results to standard output:


- Filters
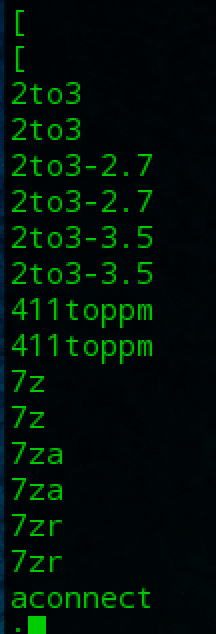
Pipelines are often used to perform complex operations on data. It is possible to put several commands together into a pipeline. Frequently, the commands used this way are referred to as filters. Filters take input, change it somehow and then output it. The first one we will try is sort.
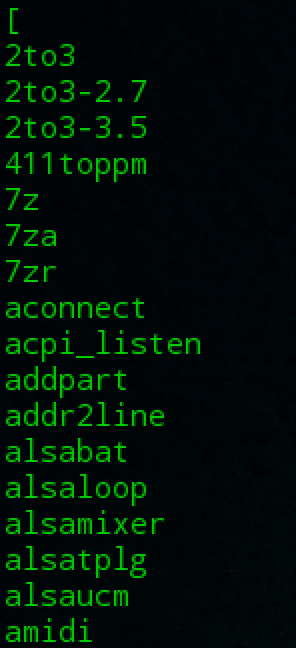
e.g. We wanted to make a combined list of all of the executable programs in /bin and /usr/bin, put them in sorted order and view it.
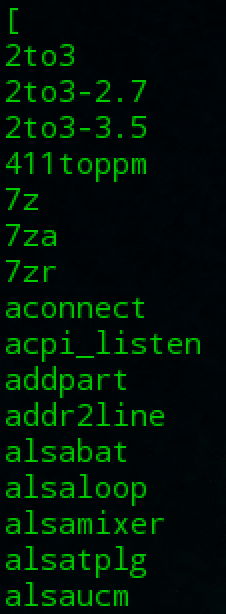
- Report or on it repeated lines : “uniq”
The uniq command is often used in conjunction with sort. uniq accepts a sorted list of data from either standard input or a single filename argument and, by default, removes any duplicates from the list.
e.g.

If we want to see the list of duplicates instead, we can add the “-d” option with uniq like:

- Print line, word ,and byte counts : “wc”
The wc (word count) command is used to display the number of lines, words, and bytes contained in files.
e.g.

- Print line matching a pattern : “grep”
grep is a powerful program used to find text patterns within files.
Usage :
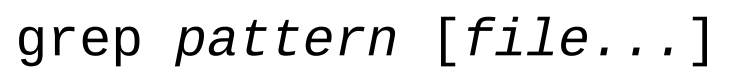
e.g. Find all the files in our list of programs that had the word “zip” embedded in the name.
Tips:
There are a couple of handy options for grep: “-i” which causes grep to ignore case when performing the search (normally searches are case sensitive) and “-v” which tells grep to only print lines that do not match the pattern.
- Print first/last part of files : “head/tail”
Sometimes you don’t want all of the output from a command. You may only want thefirst few lines or the last few lines. The head command prints the first ten lines of a file and the tail command prints the last ten lines. By default, both commands print ten lines of text, but this can be adjusted with the “-n” option.
e.g.

Tips :
“tail” has an option which allows you to view files in real-time. This is useful for watching the progress of log files as they are being written. In the following example, we will look at the messages file in /var/log.
e.g.

Using the “-f” option, tail continues to monitor the file and when new lines are appended, they immediately appear on the display. This continues until you type Ctrlc.
- Read from stdin and output to stdout and files : “tee”
In keeping with our plumbing metaphor, Linux provides a command called tee which creates a “tee” fitting on our pipe. The tee program reads standard input and copies it to both standard output (allowing the data to continue down the pipeline) and to one or more files. This is useful for capturing a pipeline’s contents at an intermediate stage of processing.
e.g. we repeat one of our earlier examples, this time including tee to capture the entire directory listing to the file ls.txt before grep filters the pipeline’s contents:

