一 mysql5.7
直接插入中文数据报错。
1、修改配置文件
vim /etc/my.cnf
在最后加上中文字符集配置
character_set_server=utf8
2、重新启动mysql
3、已生成的库表字符集如何变更
修改数据库的字符集
mysql> alter database mydb character set ‘utf8’;
修改数据表的字符集
mysql> alter table mytbl convert to character set ‘utf8’;
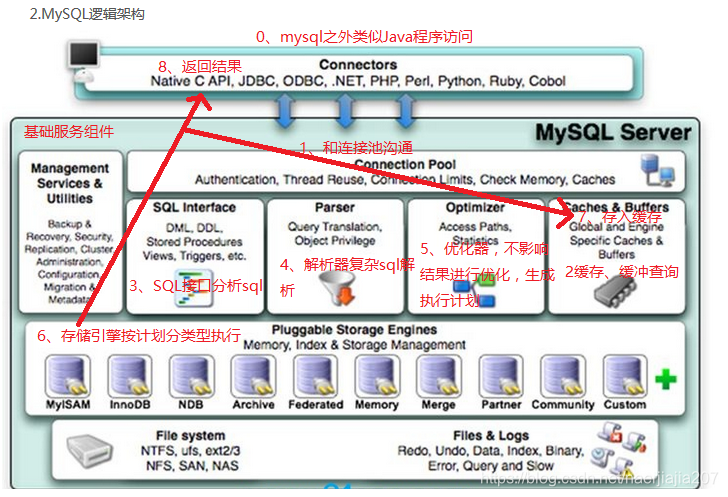
二 mysql逻辑架构
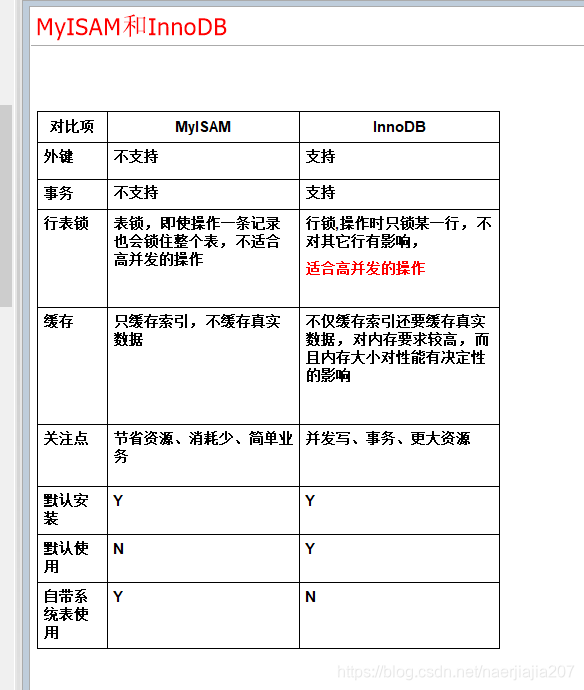
Myisam和InnoDB的区别
CSV引擎
CSV引擎可以将普通的CSV文件作为MySQL的表来处理,但不支持索引。
CSV引擎可以作为一种数据交换的机制,非常有用。
CSV存储的数据直接可以在操作系统里,用文本编辑器,或者excel读取。
三 索引优化
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
可以得到索引的本质:索引是数据结构。
你可以简单理解为“排好序的快速查找数据结构”。
B树和B+树的概念和区别
1)B-树的关键字和记录是放在一起的,叶子节点可以看作外部节点,不包含任何信息;B+树的非叶子节点中只有关键字和指向下一个节点的索引,记录只放在叶子节点中。
2)在B-树中,越靠近根节点的记录查找时间越快,只要找到关键字即可确定记录的存在;而B+树中每个记录的查找时间基本是一样的,都需要从根节点走到叶子节点,而且在叶子节点中还要再比较关键字。从这个角度看B-树的性能好像要比B+树好,而在实际应用中却是B+树的性能要好些。因为B+树的非叶子节点不存放实际的数据,这样每个节点可容纳的元素个数比B-树多,树高比B-树小,这样带来的好处是减少磁盘访问次数。尽管B+树找到一个记录所需的比较次数要比B-树多,但是一次磁盘访问的时间相当于成百上千次内存比较的时间,因此实际中B+树的性能可能还会好些,而且B+树的叶子节点使用指针连接在一起,方便顺序遍历(例如查看一个目录下的所有文件,一个表中的所有记录等),这也是很多数据库和文件系统使用B+树的缘故。
思考:为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?
- B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。 - B+树的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
基本语法
创建索引:
CREATE [UNIQUE ] INDEX [indexName] ON table_name(column))
删除:
DROP INDEX [indexName] ON mytable;
查看:
SHOW INDEX FROM table_name\G
有四种方式来添加数据表的索引:
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引。
性能分析
explain :查看执行计划
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是
如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈
重点字段
id
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
三种情况:
1.id相同,执行顺序由上至下
2.id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
3.id相同不同,同时存在,id如果相同,可以认为是一组,从上往下顺序执行;
在所有组中,id值越大,优先级越高,越先执行
== id号每个号码,表示一趟独立的查询。一个sql 的查询趟数越少越好。 ==
type
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
简易版:
system>const>eq_ref>ref>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
三个较差情况:
1.range:
只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引
一般就是在你的where语句中出现了between、<、>、in等的查询
这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引。
2.index:
出现index是sql使用了索引但是没用通过索引进行过滤,一般是使用了覆盖索引或者是利用索引进行了排序分组 ,一般是where后面没有优化索引
3.all(最差):
Full Table Scan,将遍历全表以找到匹配的行
备注:一般来说,得保证查询至少达到range级别,最好能达到ref。
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。
key_len字段能够帮你检查是否充分的利用上了索引,越大越好
rows
rows列显示MySQL认为它执行查询时必须检查的行数。物理扫描的行数,越小越好。不过此值是innodb引擎估计出来的数字并不一定准确。
Extra
包含不适合在其他列中显示但十分重要的额外信息,主要用来检测
order by,group by或者关联查询是否使用了索引。
有以下几种情况:
1.Using filesort 2.Using temporary 3.using join buffer都是很差的是使用方式。要建立索引。
4.impossible where:不可能出现的情况,一般为 逻辑出现错误。
5.USING index:
利用索引进行了排序或分组,
表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错!
如果同时出现using where,表明索引被用来执行索引键值的查找;
如果没有同时出现using where,表明索引只是用来读取数据而非利用索引执行查找。
四 查询优化
单表查询优化
常见索引失效:
1 . 系统中经常出现的sql语句如下:
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=4
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=4 AND emp.name = ‘abcd’
解决:
where后筛选字段有多少就建立多少索引
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME)
最佳左前缀法则
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
在创建索引的字段中第一个就是最左,每个左边的字段都是后面一个字段的一整个树,过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。要按照顺序命中索引
2.不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描,在where后使用计算、函数、(自动or手动)类型转换都会使索引失效
3.存储引擎不能使用索引中范围条件右边的列,即在建立索引时,范围查询要放到最后
4.mysql 在使用不等于(!= 或者<>)的时候无法使用索引会导致全表扫描
5.is not null 也无法使用索引,但是is null是可以使用索引的
6.like以通配符开头(’%abc…’)mysql索引失效会变成全表扫描的操作
7.字符串不加单引号索引失效,javabean类型和mysql字段的字符类型要一直,不然所以会失效。
关联查询优化
1、保证被驱动表的join字段已经被索引
2、left join 时,选择小表作为驱动表,大表作为被驱动表。
3、inner join 时,mysql会自己帮你把小结果集的表选为驱动表。
4、子查询尽量不要放在被驱动表,有可能使用不到索引。
5、能够直接多表关联的尽量直接关联,不用子查询。
子查询优化:
尽量不要使用not in 或者 not exists
用left outer join on xxx is null 替代
排序分组优化:
普通order by不能使用索引
无过滤 不索引,可加上过滤条件,使用索引
顺序错,必排序排序的顺序要对应
方向反 必排序 desc asc要一样
ORDER BY子句,尽量使用Index方式排序,避免使用FileSort方式排序
group by 使用索引的原则几乎跟order by一致 ,唯一区别是groupby 即使没有过滤条件用到索引,也可以直接使用索引。
最后使用索引的手段:覆盖索引 即不要使用select
不是全部都要优化,先找查询最慢,需求最多的,再去优化。
利用慢查询优化。可以使用日志分析工具,找运维帮忙在生产环境开启几天后看查询最多最慢的语句再使用explain分析。
