为什么是Hadoop
- 高可靠性:Hadoop维护多个数据副本当出现单点故障的时候可以对节点进行重新分布。
- 高扩展性:我们可以增加或者减少服务器节点/数据节点。非常适合于现在科技工业的运维。
- 高效性:Hadoop中的MapReduce采用分布式计算框架继续宁数据的处理,速度较快,(当然MapReduce在实际中用的并不多,因为读写硬盘非常的浪费时间,后米娜我们会提到)。
- 容错性:第一点我们说到Hadoop会保存多个副本,这也就不用我多说了。
Hadoop组成框图
我画了一个图方便大家理解,当然只需要知道就好,后面我们会详细说明。

- Hadoop HDFS:分布式文件系统
- Hadoop MapReduce:分布式计算框架,不过一般用于离线计算,具体原因上一篇blog我提到过,由于需要写入硬盘导致实时响应做不到。
- Hadoop YARN:主要负责作业调度,和集群资源管理的框架。
Hadoop安装
以下操作在Linux虚拟机上进行(建议红帽子,或者centos)我使用的红帽子,可能linux命令以及目录结构对于不同的linux系统有些许差异
- 关闭防火墙
禁用:systemctl disable firewalld.service
查看状态:systemctl status firewalld.service
对于selinux我们同样需要关闭
进入/etc/selinux/config,将SELINUX=enforcing改为SELINUX=disabled - 修改ip
gedit或者vi /etc/sysconfig/network-scripts/ifcfg-ens33
ip地址要看虚拟机的网络编辑器上面nat模式现实的ip,修够最后面的字段就好。
BOOTPROTO=static
ONBOOT=yes
IPADDR=AAA.BBB.X.111
GATEWAY=AAA.BBB.X.2
DNS1=8.8.8.8
DNS2=8.8.4.4
NETMASK=255.255.255.0
gedit /etc/resolv.conf
nameserver 8.8.8.8
nameserver 8.8.4.4
ps::重启网卡
命令如下
service network restart
- 在虚拟机中找一个地方专门来存放有关大数据方面的软件,这是一个必备的好习惯。
- 安装jdk(不详细讲了,这个大家查一下很简单,注意要配置变量)
- ip和主机名做映射
- 修改主机名
hostnamectlset-hostname主机名 - IP和主机名关系映射
vi /etc/hosts
你虚拟机1的ip bigdata1
在windows的C:\Windows\System32\drivers\etc路径下找到hosts并添加
你虚拟机1的ip bigdata111
- 伪分布部署Hadoop
- SSH免密登陆(不配置的话启动一次集群需要输入好几次密码)
生成公钥和私钥:
ssh-keygen -t rsa然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)将公钥拷贝到要免密登录的目标机器上ssh-copy-id 主机名1(这里写本身的虚拟机1
的名字就好)
.ssh文件夹下的文件功能解释
(1)~/.ssh/known_hosts:记录ssh访问过计算机的公钥(public key)
(2)id_rsa:生成的私钥
(3)id_rsa.pub:生成的公钥
(4)authorized_keys:存放授权过得无秘登录服务器公钥
- 在官网上下载Hadoop,版本选择2.7.3就好,当然别的版本也可以。
下载好后通过 tar -zxvf 命令解压到一个你自定义的专门存放解压后的软件的目录。 - 开始伪分布的配置
- 进入/opt/moudle/hadoop-2.7.3/etc/hadoop目录的core-site.xml文件
<!-- 指定HDFS中NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://当前主机的主机名:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.X.X/data/tmp</value>
</property>
- 进入/opt/moudle/hadoop-2.7.3/etc/hadoop目录的hdfs-site.xml文件
<!--数据冗余数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondary的地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>当前主机的主机名:50090</value>
<!--由于是伪分布式所以这里我们依然使用本机作为secondary节点的地址-->
</property>
<!--关闭权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
- 依然是这个路径下的yarn-site.xml文件
<!-- reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>依然是当前的主机名</value>
</property>
<!-- 日志聚集功能使能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天(秒) 当然时间可以自己定义-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
- 还是当前的路径在修改最后一个文件mapred-site.xml
<!-- 指定mr运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--历史服务器的地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>主机名:10020</value>
</property>
<!--历史服务器页面的地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>主机名:19888</value>
</property>
- 下一步,我们要为hadoop伪分布生态配置jdk环境
我们还是如上的路径找到
hadoop-env.sh yarn-env.sh mapred-env.sh这三个配置文件加上下面这一句话
export JAVA_HOME=自己jdk的安装路径
到目前为止伪分布的配置工作就已经完成了。由于是第一次启动,所以先要格式化namenode。提到namenode大家可能有一些陌生,所以我要插叙一下Hadoop生态的基本架构了。后面第三讲我会详细解释,现在我简单提一下为了大家能够理解。
什么是namenode呢,我们插播一下Hadoop生态,首先我们知道Hadoop是非常出色的分布式框架,
同时我们以后会经常提到集群这个词语,在正常的生产中,Hadoop回搭建在数以十、百计的服务器上,
那么我们将每个服务器都叫做一个节点,也就是node。那么namenode呢,嗯,就是node的老大,
不过只是其中的一个老大。因为后面还有yarn的老大,hinv的老大,spark的老大,有可能是同一个node,
也可能不是一个node。
先这么理解就好。
所以格式化这么重要的步骤就一定要在老大机上进行了。哈哈
我们/opt/moudle/hadoop-2.7.3/bin中执行 hdfs namenode -format命令进行格式化,因为伪分布就是将老大和小弟都放在一台机子上了,所以就直接进行格式化就行,在完全分布的时候我们要切换到namenode上去执行这个命令。格式化完成后,下次启动集群就不需要再次格式化了。
- 启动集群
启动集群得命令:
Namenode的主节点:sbin/start-dfs.sh
Yarn的主节点:sbin/stop-yarn.sh
然后我们输入jps命令查看如图

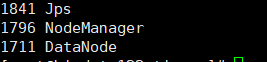
这里我是全分布所以会有第一幅主节点和第二幅分节点的情况。但是伪分布肯定是在一台机器上所以只要你有上面的所有的东西就可以了,数量不一定会一样。具体的到底每个代表什么意思我会在下一讲说明白。
总之如果你看到了上面的东西那么祝贺你,伪分布已经成功地在你的机器上运行了起来。、
题外话,大家千万注意不要直接挂其虚拟机,一定要在之前关闭集群,否则下次就会出现错误,我吃了不少亏了,在这里提醒大家。停止集群的命令是
ps:stop-all.sh
我们第三讲见。
