引言
本来在研究完B树之后,应该直接撸红黑树的。但是突然想起来一种可以快速查找、插入、删除的数据结构,据说可以代替红黑树。就是本文的标题——跳表(SkipList)。跳表还有一个优点是实现起来简单。
redis中的有序集合,其实就是基于跳表实现的。
为啥叫做跳表,听到这个名字我第一反应是感觉它很跳。


其实
- 跳表结合了链表和二分查找的思想
- 由原始链表和一些通过“跳跃”生成的链表组成
- 第0层是原始链表,越上层“跳跃”的越高,元素越少
- 上层链表是下层链表的子序列
- 查找时从顶层向下,不断缩小搜索范围
特性
跳表有很多层,如果只看0层的话,就是一个有序链表。那么其他层是什么呢?
我们知道,链表的查询复杂度为

如果在这个基础之上,增加一层“索引”,查找就会快一点点。
之前直接查找单链表,比如查询节点7:

会经过6个节点,那通过索引呢?

经过4个节点就能找到了。是不是快了一点。
要注意到,每一层上的索引是可以向下层走的。上面的图只是一个简化结构,更严谨的一个结构应该如下:
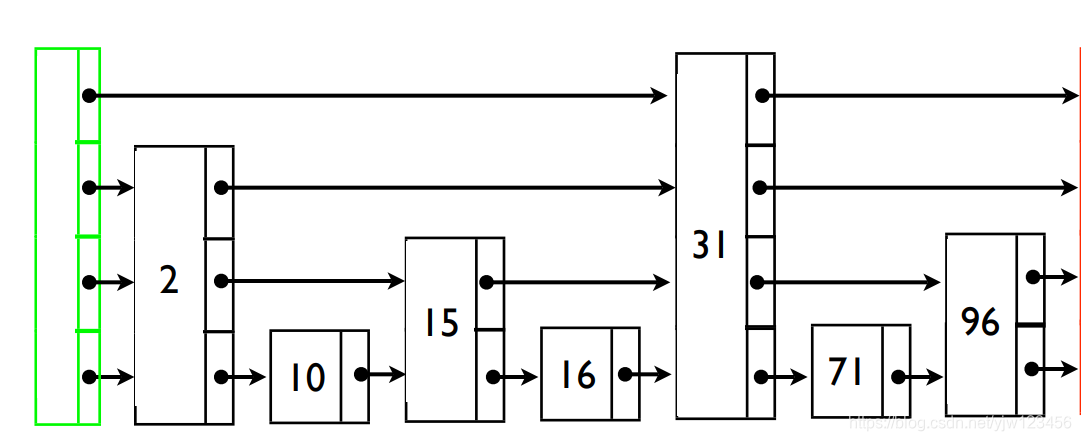
最左边的是header节点,不存值,上图的31,出现在了0,1,2,3层,其实就是一个节点。不是四个节点(这个要看具体的实现,这里是通过数组实现,可以通过下标访问,也可以通过链式实现)。这些层次信息是通过forwards(ArrayList)保存的。因此可以很快的访问到下一层。
如果元素个数很多的话,通常层数也会相应的增加。比如我们再增加一层。

现在访问节点7经过的节点为:1->6->7。
这里有必要提出的是,每隔两个节点往上提升一层建立索引只是理想情况,实际上是通过随机层数来实现的。这点后面会分析。
实现
结构
我们将每个节点值以及每层上的索引信息封装到一个类中:
private class Node {
//保存值
E data;
//保存了每一层上的节点信息,可能为null
List<Node> forwards;
Node(E data) {
this.data = data;
forwards = new ArrayList<>();
//事先把每一层都置为null,虽然空间利用率没那么高,但是简化了实现
//也可以通过自定义列表(比如B树实现中用到的Vector)来实现,就可以不用下面的操作
for (int i = 0; i <= maxLevel; i++) {
forwards.add(null);
}
}
@Override
public String toString() {
return data == null ? " " : "" + data;
}
/**
* 得到当前节点level层上的下一个(右边一个)节点
*
* @param level
* @return
*/
Node next(int level) {
return this.forwards.get(level);
}
}
同样地,这个Node也是通过内部类来实现的,forwards保存了每一层上的索引信息。

forwards描述了上图中标红的部分,16是通过data属性保存的。
节点的结构还是挺简单的,这里我增加了一个next()方法用来访问同层的右边节点。
有了这个之后,我们来看一下查找的实现是怎样的。
查找
查找时从顶层向下,不断缩小搜索范围。
以前面的图片为例,假设有这样一个跳表。查询节点值为7的过程如上所示。
首先从头结点header开始,并起始于顶层(这里是1)。
第1层:经由1,4,6。 由于6的下一个节点(这里说的下一个节点都是指右边一个,不是下一层)是8,我们要查找的是7,因此小于7的最大节点就是6,我们从此处往下到达下一层。
第0层:经由6,7。 从6往右就到了7了。找到了!!
整个查询的复杂度为
public Node find(E e) {
if (empty()) {
return null;
}
return find(e, head, curLevel);
}
private Node find(E e, Node current, int level) {
while (level >= 0) {
current = findNext(e, current, level);
level--;
}
return current;
}
//返回给定层数中小于e的最大者
private Node findNext(E e, Node current, int level) {
Node next = current.next(level);
while (next != null) {
if (e.compareTo(next.data) < 0) {
break;
}
//到这说明e >= next.data
current = next;
next = current.next(level);
}
return current;
}
插入

给定如上跳表,假设要插入节点2。
首先需要判断节点2是否已经存在,若存在则返回false。
否则,随机生成待插入节点的层数。
/**
* 生成随机层数[0,maxLevel)
* 生成的值越大,概率越小
*
* @return
*/
private int randomLevel() {
int level = 0;
while (Math.random() < PROBABILITY && level < maxLevel - 1) {
++level;
}
return level;
}
这里的PROBABILITY =0.5。上面算法的意思是返回1的概率是
;返回2的概率是
;返回3的概率是
,依次类推。看成一个分布的话,第0层包含所有节点,第1层含有
个节点,第2层含有
个节点…
注意这里有一个最大层数maxLevel,也可以不设置最大层数。
通过这种随机生成层数的方式使得实现起来简单。
假设我们生成的层数是3。

在1和3之间插入节点2,层数是3,也就是节点2跳跃到了第3层。
public boolean add(E e) {
if (contains(e)) {
return false;
}
int level = randomLevel();
if (level > curLevel) {
curLevel = level;
}
Node newNode = new Node(e);
Node current = head;
//插入方向由上到下
while (level >= 0) {
//找到比e小的最大节点
current = findNext(e, current, level);
//将newNode插入到current后面
//newNode的next指针指向该节点的后继
newNode.forwards.add(0, current.next(level));
//该节点的next指向newNode
current.forwards.set(level, newNode);
level--;//每层都要插入
}
size++;
return true;
}
我们通过一个例子来模拟,由于实现了直观的打印算法,因此就不画图了。
假设我们要插入1, 6, 9, 3, 5, 7, 4, 8
过程如下:
add: 1
Level 0: 1
add: 6
Level 0: 1 6
add: 9
Level 2: 9
Level 1: 9
Level 0: 1 6 9
add: 3
Level 2: 3 9
Level 1: 3 9
Level 0: 1 3 6 9
add: 5
Level 2: 3 9
Level 1: 3 5 9
Level 0: 1 3 5 6 9
add: 7
Level 2: 3 9
Level 1: 3 5 9
Level 0: 1 3 5 6 7 9
add: 4
Level 2: 3 9
Level 1: 3 5 9
Level 0: 1 3 4 5 6 7 9
add: 8
Level 2: 3 9
Level 1: 3 5 9
Level 0: 1 3 4 5 6 7 8 9
删除
之前在研究二叉树的时候,发现所有的平衡的二叉树(也包括多叉树,如B树)删除算法都是最难的。
上文说了跳表的一个优点是实现简单,删除也不例外,也是异常的简单。
该删除算法是根据查找算法实现的,并通过大量的测试(随机插入2000个数据,并根据插入顺序删除,没有抛出异常,因此应该是没问题的,如果发现删除实现有问题,请一定要告诉我)。
我看了网上其他 的删除算法实现基本都是基于双向链表的,但是双向链表需要多维护一个pre指针,或者额外需要一个updates列表来记录前驱节点,增加了复杂度。根据查找算法,理论上是可以在一次查找过程中找到它的前驱节点,并进行删除的。
测试代码如下:
public static void main(String[] args) {
Random random = new Random();
int[] values = random.ints(2000, 1, 10000).toArray();
// int[] values = {1, 6, 9, 3, 5, 7, 4, 8};
SkipList<Integer> list = new SkipList<>();
for (int value : values) {
//System.out.println("add: " + value);
list.add(value);
//list.print();
//System.out.println();
}
for (int value : values) {
list.remove(value);
System.out.println("remove: " + value);
list.print();
System.out.println();
}
}
删除可以说是插入的逆过程
上文中我们插入了节点2,如果想要删除它的话,就是将它的前驱节点指向它的后继节点(跳表需要对链表的操作比较熟悉,如果不太了解的话,建议先去搜一下)。
把握住这个思路,实现删除就不难了。
/**
* O(logN)的删除算法
*
* @param e
* @return
*/
public boolean remove(E e) {
if (empty()) {
return false;
}
boolean removed = false;//记录是否删除
int level = curLevel;
//current用于遍历,pre指向待删除节点前一个节点
Node current = head.next(level), pre = head;
while (level >= 0) {
while (current != null) {
//e < current.data
if (e.compareTo(current.data) < 0) {
break;
}
//只有e >= current.data才需要继续
//如果e == current.data
if (e.compareTo(current.data) == 0) {
//pre指向它的后继
pre.forwards.set(level, current.next(level));
//设置删除标记
removed = true;
//跳出循环内层循环
break;
}
pre = current;
current = current.next(level);
}
//继续搜索下一层
level--;
if (level < 0) {
//防止next(-1)
break;
}
//往下一层,从pre开始往下即可,不需要从头(header)开始
current = pre.next(level);
}
if (removed) {
size--;//不要忘记size--
return true;
}
return false;
}
整个代码实现完成后,发现真的很简单,也很简短。
还是插入1, 6, 9, 3, 5, 7, 4, 8,然后依次删除它:
before remove:
Level 4: 7
Level 3: 7 8
Level 2: 4 7 8
Level 1: 4 5 7 8
Level 0: 1 3 4 5 6 7 8 9
remove: 1
Level 4: 7
Level 3: 7 8
Level 2: 4 7 8
Level 1: 4 5 7 8
Level 0: 3 4 5 6 7 8 9
remove: 6
Level 4: 7
Level 3: 7 8
Level 2: 4 7 8
Level 1: 4 5 7 8
Level 0: 3 4 5 7 8 9
remove: 9
Level 4: 7
Level 3: 7 8
Level 2: 4 7 8
Level 1: 4 5 7 8
Level 0: 3 4 5 7 8
remove: 3
Level 4: 7
Level 3: 7 8
Level 2: 4 7 8
Level 1: 4 5 7 8
Level 0: 4 5 7 8
remove: 5
Level 4: 7
Level 3: 7 8
Level 2: 4 7 8
Level 1: 4 7 8
Level 0: 4 7 8
remove: 7
Level 4:
Level 3: 8
Level 2: 4 8
Level 1: 4 8
Level 0: 4 8
remove: 4
Level 4:
Level 3: 8
Level 2: 8
Level 1: 8
Level 0: 8
remove: 8
Level 4:
Level 3:
Level 2:
Level 1:
Level 0:
完整代码
package com.algorithms.list;
import java.util.*;
/**
* 跳表
*
* @Author: Yinjingwei
* @Date: 2019/7/9/009 21:36
* @Description:
*/
public class SkipList<E extends Comparable<? super E>> implements Iterable<E> {
//当前层数
private int curLevel;
//头结点,不保存值
private Node head;
//跳表中元素个数
private int size;
//用于生成随机层数
private static final double PROBABILITY = 0.5;
//最大层数,也可以写成通过构造函数注入的方式动态设置
private static final int maxLevel = 8;
public SkipList() {
size = 0;
curLevel = 0;
head = new Node(null);
}
public int size() {
return size;
}
public boolean add(E e) {
if (contains(e)) {
return false;
}
int level = randomLevel();
if (level > curLevel) {
curLevel = level;
}
Node newNode = new Node(e);
Node current = head;
//插入方向由上到下
while (level >= 0) {
//找到比e小的最大节点
current = findNext(e, current, level);
//将newNode插入到current后面
//newNode的next指针指向该节点的后继
newNode.forwards.add(0, current.next(level));
//该节点的next指向newNode
current.forwards.set(level, newNode);
level--;//每层都要插入
}
size++;
return true;
}
//返回给定层数中小于e的最大者
private Node findNext(E e, Node current, int level) {
Node next = current.next(level);
while (next != null) {
if (e.compareTo(next.data) < 0) {
break;
}
//到这说明e >= next.data
current = next;
next = current.next(level);
}
return current;
}
public Node find(E e) {
if (empty()) {
return null;
}
return find(e, head, curLevel);
}
private Node find(E e, Node current, int level) {
while (level >= 0) {
current = findNext(e, current, level);
level--;
}
return current;
}
public boolean empty() {
return size == 0;
}
/**
* O(logN)的删除算法
*
* @param e
* @return
*/
public boolean remove(E e) {
if (empty()) {
return false;
}
boolean removed = false;//记录是否删除
int level = curLevel;
//current用于遍历,pre指向待删除节点前一个节点
Node current = head.next(level), pre = head;
while (level >= 0) {
while (current != null) {
//e < current.data
if (e.compareTo(current.data) < 0) {
break;
}
//只有e >= current.data才需要继续
//如果e == current.data
if (e.compareTo(current.data) == 0) {
//pre指向它的后继
pre.forwards.set(level, current.next(level));
//设置删除标记
removed = true;
//跳出循环内层循环
break;
}
pre = current;
current = current.next(level);
}
//继续搜索下一层
level--;
if (level < 0) {
//防止next(-1)
break;
}
//往下一层,从pre开始往下即可,不需要从头(header)开始
current = pre.next(level);
}
if (removed) {
size--;//不要忘记size--
return true;
}
return false;
}
/**
* 生成随机层数[0,maxLevel)
* 生成的值越大,概率越小
*
* @return
*/
private int randomLevel() {
int level = 0;
while (Math.random() < PROBABILITY && level < maxLevel - 1) {
++level;
}
return level;
}
public boolean contains(E e) {
Node node = find(e);
return node != null && node.data != null && node.data.compareTo(e) == 0;
}
@Override
public Iterator<E> iterator() {
return new SkipListIterator();
}
private class SkipListIterator implements Iterator<E> {
Node current = head;
@Override
public boolean hasNext() {
return current.next(0) != null;
}
@Override
public E next() {
current = current.next(0);
return current.data;
}
}
private class Node {
//保存值
E data;
//保存了每一层上的节点信息,可能为null
List<Node> forwards;
Node(E data) {
this.data = data;
forwards = new ArrayList<>();
//事先把每一层都置为null,虽然空间利用率没那么高,但是简化了实现
//也可以通过自定义列表(比如B树实现中用到的Vector)来实现,就可以不用下面的操作
for (int i = 0; i <= maxLevel; i++) {
forwards.add(null);
}
}
@Override
public String toString() {
return data == null ? " " : "" + data;
}
/**
* 得到当前节点level层上的下一个(右边一个)节点
*
* @param level
* @return
*/
Node next(int level) {
return this.forwards.get(level);
}
}
public void print() {
//记录了第0层值对应的索引,从1开始
Map<E, Integer> indexMap = new HashMap<>();
Node current = head.next(0);
int index = 1;
int maxWidth = 1;//值的最大宽度,为了格式化好看一点
while (current != null) {
int curWidth = current.data.toString().length();
if (curWidth > maxWidth) {
maxWidth = curWidth;//得到最大宽度
}
indexMap.put(current.data, index++);
current = current.next(0);
}
print(indexMap, maxWidth);
}
private void print(int level, Node current, Map<E, Integer> indexMap, int width) {
System.out.print("Level " + level + ": ");
int preIndex = 0;//该层前一个元素的索引
while (current != null) {
//当前元素的索引
int curIndex = indexMap.get(current.data);
if (level == 0) {
//第0层直接打印即可
printSpace(curIndex - preIndex);
} else {
//其他层稍微复杂一点
//计算空格数
//相差的元素个数 + 相差的元素个数乘以宽度
int num = (curIndex - preIndex) + (curIndex - preIndex - 1) * width;
printSpace(num);
}
System.out.printf("%" + width + "s", current.data);
preIndex = curIndex;
current = current.next(level);
}
System.out.println();
}
/**
* 打印num个空格
*
* @param num
*/
private void printSpace(int num) {
for (int i = 0; i < num; i++) {
System.out.print(' ');
}
}
private void print(Map<E, Integer> map, int width) {
//从顶层开始打印
int level = curLevel;
while (level >= 0) {
print(level, head.next(level), map, width);
level--;
}
}
public static void main(String[] args) {
//Random random = new Random();
//int[] values = random.ints(2000, 1, 10000).toArray();
int[] values = {1, 6, 9, 3, 5, 7, 4, 8};
SkipList<Integer> list = new SkipList<>();
for (int value : values) {
//System.out.println("add: " + value);
list.add(value);
//list.print();
//System.out.println();
}
System.out.println("before remove:");
list.print();
System.out.println();
for (int value : values) {
list.remove(value);
System.out.println("remove: " + value);
list.print();
System.out.println();
}
}
}
复杂度
空间复杂度
跳表会不会很浪费内存?建立的索引必然会占用内存,但是会占用多少呢?我们来分析一下。
假设原始链表大小为 ,那么第1层索引大约有 个节点,第2层有 个节点,依次类推,直到最后剩下2个节点,总数为: ,因此空间复杂度是
时间复杂度
上文说了,查找的时间复杂度为
,根据上面的图解,也不难理解,其实插入和删除都是在一次查找过程中实现的。
插入和删除的复杂度也是
