在引入了缓存后,我们对数据的访问流程一般是下面这样的:
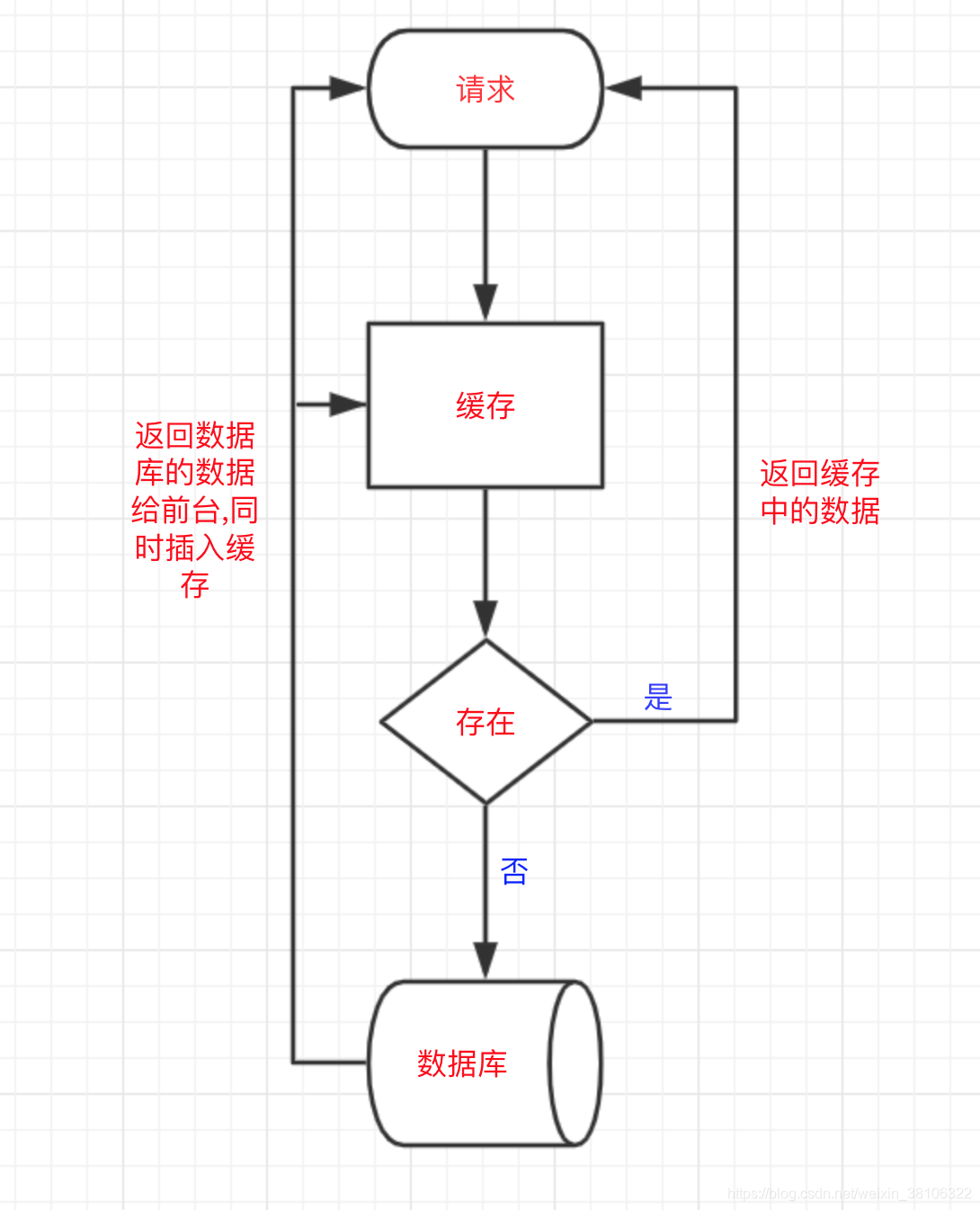
简单的用语言描述上述流程,前台请求进来后,会先经过缓存,如果数据存在于缓存里,则直接返回缓存里的数据,无需访问数据库,减少了数据库的压力,如果数据不存在于缓存,则会去访问数据库,将数据库里的数据返回给前台,同时将该数据插入缓存里,下次请求就可以从缓存里直接读取了。
什么是缓存穿透
这里就引发了一个问题,要是这个请求的数据是缓存和数据库都不存在的数据,比如缓存的key是表的主键id,同时我们id是用int自增型的,而这个请求过来的的id却是UUID字符串,那么数据库也永远不会有这个数据,那么在数据库查询不存在后,这个数据也不会被同步给缓存,这样就造成了每次这个请求都会穿透过缓存,访问到数据库,一次两次这个请求还好,要是恶意发起个几千次,数据库就扛不住了,所以缓存穿透很可能造成数据库服务器宕机。
缓存穿透的解决办法
-
为不存在key维护一个"null"值
请求一旦查询到数据库,哪怕数据不存在于数据库,我们也为它设置一个"null"值作为value,同步进缓存,设置较短的过期时间,防止缓存穿透导致数据库宕机。 -
使用布隆过滤器
什么是布隆过滤器?
本质上来说,布隆过滤器就是个概率型的数据结构,它实际上是一个很长的二进制向量和一系列随机映射函数,它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。布隆过滤器可以告诉我们这个数据可能存在,以及这个数据一定不存在,我们要用的就是这个数据一定不存在的判断。布隆过滤器简单实现
google提供了一套框架Guava,该框架提供了布隆过滤器的具体实现:BloomFilter,免去了开发自己写布隆过滤器的时间和精力。
BloomFilter最终构造方法如下,简单说下各个参数的作用:
// funnel 指定布隆过滤器里存的内存数据
// expectedInsertions 预期中需要存储的数据量
// fpp 误判率,默认值是0.03
@VisibleForTesting
static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy);
简单代码实现:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class TestMain {
private static int size = 6000;
//构建布隆过滤器
private static BloomFilter<Integer> integerBloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) throws Exception {
//往布隆过滤器里添加数据
for (int i = 0; i < size; i++) {
integerBloomFilter.put(i);
}
//判断6000的数字中是否包含600这个数
if (integerBloomFilter.mightContain(600)) {
System.out.println("存在");
}
//判断6000的数字中是否包含60001这个数
if (integerBloomFilter.mightContain(600)) {
System.out.println("不存在");
}
}
}
这段代码做的事很简单就是往一个布隆过滤器里加入1~6000的int类型数据,然后判断某些数据是否存在于布隆过滤器里
运行结果:

什么是缓存并发
缓存并发就是多个线程同时访问缓存,然后缓存数据不存在,所以又同时访问了数据库,然后又同时更新了缓存,其实这多个请求要的数据是一样的,我们却多次访问数据库和缓存,这样不仅会增加数据库的访问压力,还会导致redis的请求资源被无必要的占用,造成浪费。
缓存并发的解决办法
要解决并发问题,我们第一个想到的就是加锁,而redis正好有一个方法可以实现加锁操作-----SETNX
SETNX key value 方法作用:将 key 的值设为 value ,当且仅当 key 不存在。若给定的 key 已经存在,则 SETNX 不做任何动作。
所以每当请求到缓存这层时,如果缓存数据为空,那么就用SETNX方法设置一个标识值,如果设置成功,说明这个请求是第一个请求这数据的,那么就访问数据库取值,同时更新缓存,如果设置失败了,那么就说明,已经有请求捷足先登了,那么就让这个请求先等一会,等待结束后再重新发起,会发现缓存已经有值了,自然就不用再走到数据库这层了。
