简介
openstack的nova项目在创建虚拟机的时候,需要在多个主机中选择一个主机来创建虚拟机,这个选择的过程通过nova-scheduler完成,整个选择过程分析如下。
首先nova-scheduler收到创建的请求会在filter_scheduler通过类FilterScheduler的schedule_run_instance启动调度创建虚拟机的流程。
代码如下,红色为关键代码(红色加粗为获取可用主机的部分)
def schedule_run_instance(self, context, request_spec,
admin_password, injected_files,
requested_networks, is_first_time,
filter_properties, legacy_bdm_in_spec):
vm_uuids = request_spec.get('instance_uuids')
*#get available hosts for vm create
weighed_hosts = self._schedule(context, request_spec,filter_properties, vm_uuids)*
instance_uuids = request_spec.pop('instance_uuids')
filter_properties.pop('context', None)
for num, instance_uuid in enumerate(instance_uuids):
request_spec['instance_properties']['launch_index'] = num
try:
try:
#choose the best host for vm create
weighed_host = weighed_hosts.pop(0))
except IndexError:
raise exception.NoValidHost(reason="")
**#execute vm create
self._provision_resource(context, weighed_host,
request_spec,
filter_properties,
requested_networks,
injected_files, admin_password,
is_first_time,
instance_uuid=instance_uuid,
legacy_bdm_in_spec=legacy_bdm_in_spec)**
except Exception as ex:
#exception hander
retry = filter_properties.get('retry', {})
retry['hosts'] = []
self.notifier.info(context, 'scheduler.run_instance.end', payload)
将获取到可以使用的主机后,我们会选择最优的主机作为虚拟机创建的虚拟机,如果有多个创建,依此类推选择后面的主机(通过pop(0)实现)
self._provision_resource就会将请求发送到compute节点,通过发送rpc的cast调用,去计算节点执行虚拟机的创建。
def _provision_resource(self, context, weighed_host, request_spec,
filter_properties, requested_networks, injected_files,
admin_password, is_first_time, instance_uuid=None,
legacy_bdm_in_spec=True):
**self.compute_rpcapi.run_instance(context,
instance=updated_instance,
host=weighed_host.obj.host,
request_spec=request_spec,
filter_properties=filter_properties,
requested_networks=requested_networks,
injected_files=injected_files,
admin_password=admin_password, is_first_time=is_first_time,
node=weighed_host.obj.nodename,
legacy_bdm_in_spec=legacy_bdm_in_spec)**
def run_instance(self, ctxt, instance, host, request_spec,
filter_properties, requested_networks,
injected_files, admin_password,
is_first_time, node=None, legacy_bdm_in_spec=True):
# NOTE(russellb) Havana compat
version = self._get_compat_version('3.0', '2.37')
instance_p = jsonutils.to_primitive(instance)
msg_kwargs = {'instance': instance_p, 'request_spec': request_spec,
'filter_properties': filter_properties,
'requested_networks': requested_networks,
'injected_files': injected_files,
'admin_password': admin_password,
'is_first_time': is_first_time, 'node': node,
'legacy_bdm_in_spec': legacy_bdm_in_spec}
cctxt = self.client.prepare(server=host, version=version)
cctxt.cast(ctxt, 'run_instance', **msg_kwargs)
主机调度整个过程可以通过一张图展示,主要分为过滤和计算权值两步
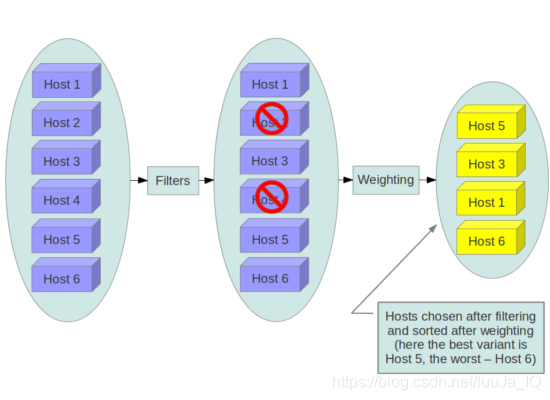
可以看出首先对所有的主机进行过滤,得到可以使用的主机,再对可以使用主机计算权值进行排序,取最优主机作为目的主机创建vm。
上文已将看到看到了虚拟机创建过程中主机调度选择的概括描述,调度主要分为过滤(filter)和权值计算(weighting),现详细分析这两步(直接从weighed_hosts = self._schedule(context, request_spec,filter_properties, vm_uuids)的关键处开始分析)
这块的filter_properties是虚拟机创建的详情包含(instance_type、force_nodes指定主机创建、镜像信息,以及虚拟机名称等其他信息)
根据对象的初始化,我们可以查看到self.host_manager初始化的是host_manager.HostManager
在过滤之前首先获得所有的主机
filters详细过程
负责将需要执行filter过滤条件执行一次,通过过滤条件将获取到的所有主机进行筛选
过滤条件默认为default=[
‘RetryFilter’,
‘AvailabilityZoneFilter’,
‘RamFilter’,
‘ComputeFilter’,
‘ComputeCapabilitiesFilter’,
‘ImagePropertiesFilter’,
‘ServerGroupAntiAffinityFilter’,
‘ServerGroupAffinityFilter’,
],
每个过滤类都需要继承BaseHostFilter,并实现自己的host_passes(),他自己实现了基类的_filter_one()
可以在配置文件nova.conf中scheduler_default_filters指定过滤条件(适合自己扩展)
表示需要将上述所有对应的过滤类进行一次过滤,过滤条件是每个class中的host_passes(),如果该主机不符合,返回false。
分析nova.filters.py代码
class BaseFilterHandler(loadables.BaseLoader):
"""Base class to handle loading filter classes.
This class should be subclassed where one needs to use filters.
"""
def get_filtered_objects(self, filter_classes, objs,
filter_properties, index=0):
LOG.debug(_("Starting with %d host(s)"), len(list_objs))
for filter_cls in filter_classes: #过滤类
cls_name = filter_cls.__name__
filter = filter_cls()
if filter.run_filter_for_index(index):
**objs = filter.filter_all(list_objs, filter_properties)**
if objs is None:
LOG.debug(_("Filter %(cls_name)s says to stop filtering"),
{'cls_name': cls_name})
return
list_objs = list(objs)
if not list_objs:
LOG.info(_("Filter %s returned 0 hosts"), cls_name)
break
LOG.debug(_("Filter %(cls_name)s returned " "%(obj_len)d host(s)"),
{'cls_name': cls_name, 'obj_len': len(list_objs)})
return list_objs
filter_all的过程如下所示
def filter_all(self, filter_obj_list, filter_properties):
"""Yield objects that pass the filter.
Can be overridden in a subclass, if you need to base filtering
decisions on all objects. Otherwise, one can just override
_filter_one() to filter a single object.
"""
for obj in filter_obj_list:
if self._filter_one(obj, filter_properties):
yield obj
#yield负责为结果的迭代器生成一个新的元素,每执行一次,多一个
class BaseHostFilter(filters.BaseFilter):
"""Base class for host filters."""
def _filter_one(self, obj, filter_properties):
"""Return True if the object passes the filter, otherwise False."""
return self.host_passes(obj, filter_properties)
def host_passes(self, host_state, filter_properties):
"""Return True if the HostState passes the filter, otherwise False.
Override this in a subclass.
"""
raise NotImplementedError()
然后这里会根据上面每个过滤类(都继承BaseHostFilter),调用自己实现的host_passes(),对主机上该类型资源进行过滤。
以RamFilter举例,该filter的host_passes()会根据虚拟机申请的instance_type中ram和所有主机ram进行匹配,如果不匹配,返回false,删除该主机作为创建的备选主机。
1、通过虚拟机请求的filter_properties的instance_type中ram设置为request_ram
2、获取host的free_ram_mb,total_usable_ram_db(主机总内存)
3、获取ram超买ram_allocation_ratio
4、计算
memory_mb_limit=total_usable_ram_db*ram_allocation_ratio(超买后的总内存)
used_ram_mb=total_usable_ram_db-free_ram_mb(实际已经使用的内存)
usable_ram=memory_mb_limit-used_ram_mb(超买后当前可用内存)
5、过滤
用request_ram和当前可用内存usable_ram比较,如果usable_ram不足以提供所需内存,return false,该主机过滤,
进行下一步过滤或者权值,从可用主机列表删除。
6、实时维护host中的memory_mb_limit。
weighting详细过程
在获得可以使用的主机列表之后,我们需要计算每个主机的权值,根据权值大小获取最优主机
HostManager使用nova.weights.BaseWeightHandler中的get_weighed_objects计算权值。
get_weighed_objects计算权值的过程如下
1、遍历权值计算对应资源类,分别计算不同类型资源对应的权值
资源计算类型主要是两种: nova.scheduler.weights.metrics.MetricsWeigher,
nova.scheduler.weights.ram.RAMWeigher.
2、各类型资源权值计算如下(以RAM为示例)
a、遍历所有主机去主机的free_ram_mb赋值给对应的weight,并设置全局的minval和maxval。
minval默认为0,maxval为None,和weight列表对应,始终保持minval最小,maxval最大。
b、normalize处理是计算权值的关键,返回主机对应的权值列表,权值结果在0-1之间
_range=maxval-minval;
各主机该资源类型的权值=(weight-minval)/_range
3、将主机对应的权值*权值乘数,并和主机对象原有的权值相加将新的权值赋给主机对象,权值乘数取自配置文件
for i, weight in enumerate(weights):
obj = weighed_objs[i]
obj.weight += weigher.weight_multiplier() * weight
4、将主机列表按照weight属性进行倒序排序
return sorted(weighed_objs, key=lambda x: x.weight, reverse=True)
其他
在完成过滤和权重后得到可用主机列表后,系统会首先根据scheduler_host_subset_size(默认为1)在可用主机列表中取字列表返回给schedule_run_instance供虚拟机创建的选择,这样scheduler那边选择的并不是最初获取的主机列表。filter_scheduler的_schedule负责
selected_hosts = []
if instance_uuids:
num_instances = len(instance_uuids)
else:
num_instances = request_spec.get('num_instances', 1)
for num in xrange(num_instances):
# Filter local hosts based on requirements ...
hosts = self.host_manager.get_filtered_hosts(hosts,filter_properties, index=num)
#weighting host
weighed_hosts = self.host_manager.get_weighed_hosts(hosts,filter_properties)
scheduler_host_subset_size = CONF.scheduler_host_subset_size
if scheduler_host_subset_size > len(weighed_hosts):
scheduler_host_subset_size = len(weighed_hosts)
if scheduler_host_subset_size < 1:
scheduler_host_subset_size = 1
chosen_host = random.choice(
weighed_hosts[0:scheduler_host_subset_size])
selected_hosts.append(chosen_host)
return selected_hosts
如果并发创建则会根据虚拟机创建个数选择多次,每选择一个主机发现还有要创建虚拟机,会重新进行filter和weighting,重新获取到主机列表,这样schedule_run_instance会获取到和虚拟机个数对应的一个主机列表。
关键参数
1、scheduler_host_manager默认为nova.scheduler.host_manager.HostManager
cfg.StrOpt(‘scheduler_host_manager’,default=‘nova.scheduler.host_manager.HostManager’,
help=‘The scheduler host manager class to use’),
2、scheduler_host_subset_size,为一个虚拟机选择多少个主机备选,默认1
3、权值乘数对应参数
ram ram_weight_multiplier
4、scheduler_default_filters scheduler默认使用的过滤策略
