- 01 python全栈s3 day2 上节课复习
- 02 python全栈s3 day2 arp协议复习
- 03 python全栈s3 day2 字符编码
01 python全栈s3 day2 上节课复习
1、计算机发展史;
2、计算机组成——a硬件系统和b软件系统;
- 运算器;
- 控制器;
- 存储器;
- 输入设备;
- 输出设备;
CPU:
内存:基于电的方式工作,速度快,然而不能永久保存数据;
硬盘:基于磁的方式工作,速度慢一些,可永久保存数据;
3、软件系统:a.系统软件(操作系统);b.应用软件;
1)软件由硬盘加载到内存中,CPU从内存中读取;
2)系统的启动流程:BIOS概念的引入(Basic Input Output System)-》系统在哪块硬盘上-》从硬盘中加载至内存中-》CPU执行

3)应用软件的启动流程:双击可执行文件-》交给操作系统-》加载至内存-》程序运行-》
4、进制概念的引入
- 二进制
- 八进制
- 十进制
- 十六进制
- 各种进制之间的相互转换方式
5、机器数与真值
6、原码、补码和反码(把所有运算转换成加法运算)
7、OSI七层模型详解
- 互联网协议的引入
- 网络通信的原理
- 物理层
- 数据链路层
- 网络层
- 传输层
- 应用层(会话层&表示层&应用层)
- 计算机通信的方式:靠吼-广播
- ARP协议
- 端口号
- 跨广播域通信
02 python全栈s3 day2 arp协议复习
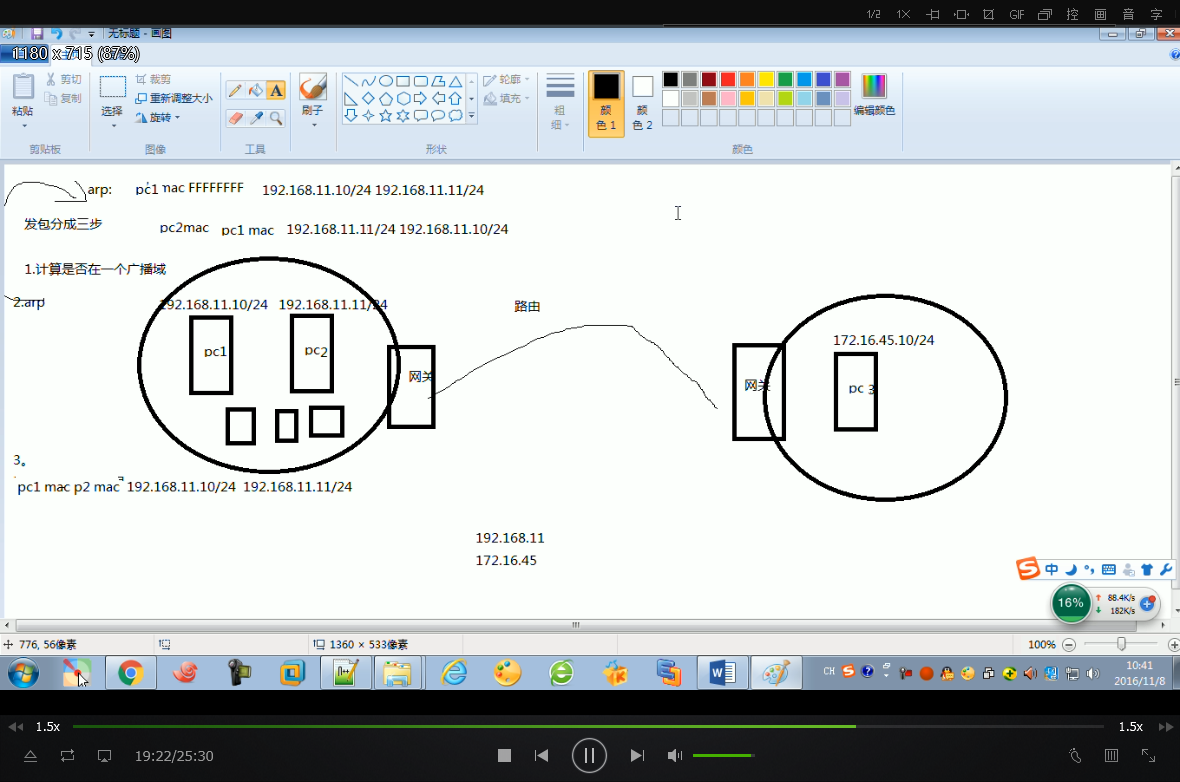
1、ARP协议-地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议。
1)计算机发包分3步:计算是否在一个相同的广播域,例如192.168.0.11/24和192.168.0.12/24 ;ARP协议获取网关的MAC;将数据包发送给目标MAC(中间加了一层代理);
03 python全栈s3 day2 字符编码
1、什么是字符编码;
通过上一节的对“二进制”的学习,我们已经认识到计算机只认二进制,生活中的数字要想让计算机理解就必须转成成“二进制”。十进制到二进制的转换只能解决计算机理解数字的问题,那么文字要怎样让计算机理解呢?
于是我们就选择了一种“曲线救国”的方式,既然数字可以转换成十进制,那么我们只要想办法把文字转换成数字,这样文字就可以表示成二进制了。
文字应该怎么转换成数字呢?就是强制转换!
文字——>十进制——>二进制
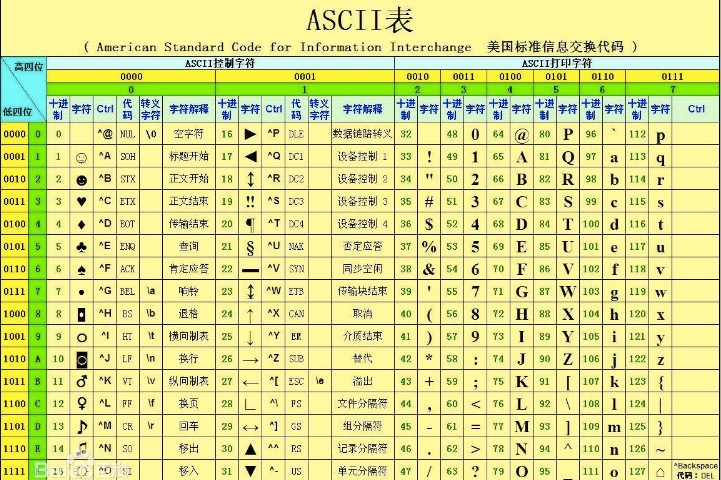
我们自己强行约定了一个表,把文字和数字对应上,这张表就相当于翻译官,我们可以拿着一个数字来对比对应表找到相应的文字,反之亦然。这行表就叫做ASCII码表。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,它是现今最通用的“单字节编码系统”,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。
如此,就可以把文字与数字的对应关系就可以表示了。
1)ASCII码表
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
我们中国人制定了一张关于中文和数字的对应关系表,但是试想一下,全世界有上百种语言,各国有各国的标准,就会不可避免的出现冲突,结构就是出现乱码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多。
但是新的问题又出现了,如果统一成Unicode编码,乱码问题从此消失了,但是,如果我们写的文本基本全部都是英文的话,用Unicode编码比ASCII编码需要多处一倍的存储空间,在存储和传输上就十分不划算。
So,本着节约的精神,又出现了吧Unicode编码转换为“可变长编码”的UTF-8,它是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
UTF-8编码有一个好处,就是ASCII编码实际上可以被看成是UTF-8的一部分,所以,大量仅支持ASCII编码的历史遗留软件可以在UTF-8下继续工作。
2)计算机存储单位
bit 位 计算机中最小的表示单位;
8bit =1bytes 字节,最小的存储单位,1bytes缩写为1B
1KB = 1024B
1MB=1024KB
1GB=1024MB
1TB=1024GB
1PB=1024TB
1EB=1024PB
1ZB=1024EB
1YB=1024ZB
1BB=1024YB
其中,2**10=1024