序
目的:最近在做基于图像的驾驶员疲劳检测系统项目,其中行为检测包含驾驶员打电话和抽烟的危险行为,基于图像用之前的Dlib68特征点和opencv肤色和动态追踪图像处理已经远远达不到理想标准,我们需要获取脸部和手部关键点信息;为了精确识别打电话和抽烟或者是喝水等动作,这里引入了机器视觉中一经典开源模型——Openpose(人体姿态识别模型)。


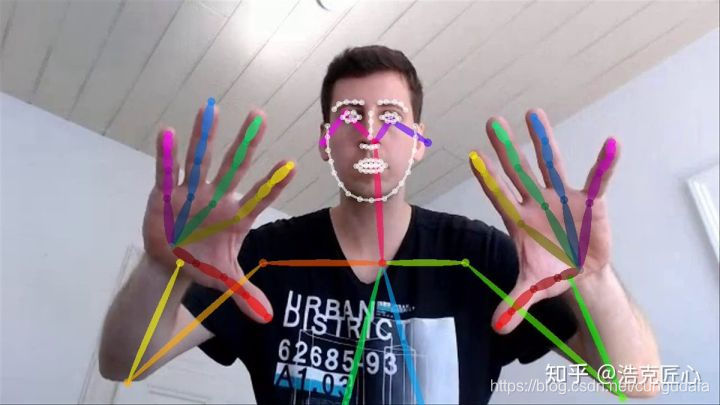
Openpose简介
参考:Github开源人体姿态识别项目OpenPose中文文档

OpenPose优点:将人体、人手、人脸的landmarks三元归一
正文
(1)配置Openpose环境
Windows10 + python3.7 + anaconda3 + jupyter5.6.0
可以按步骤配置,也可以直接下载训练好的模型
-
下载开源项目:https://github.com/CMU-Perceptual-Computing-Lab/openpose

-
解压,进入
..\openpose-master\models目录,双击运行getModels.bat
等待加载模型pose_iter_584000.caffemodel:
等待时间较长,如中途中断,重新双击运行
getModels.bat即可,
完整加载模型大小:100M,
保存位置:..\openpose-master\models\pose\body_25\pose_iter_584000.caffemodel
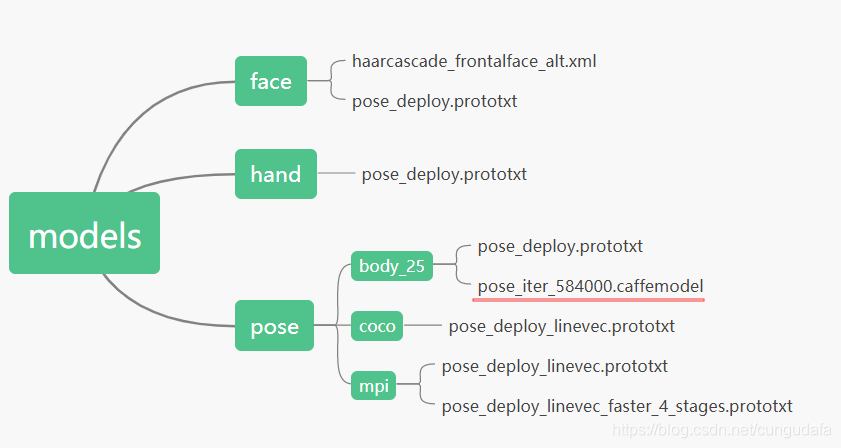
跑了一天完全加载5个模型如图,openpose总大小800M,编译真的太心寒了,这里快速下载入口。
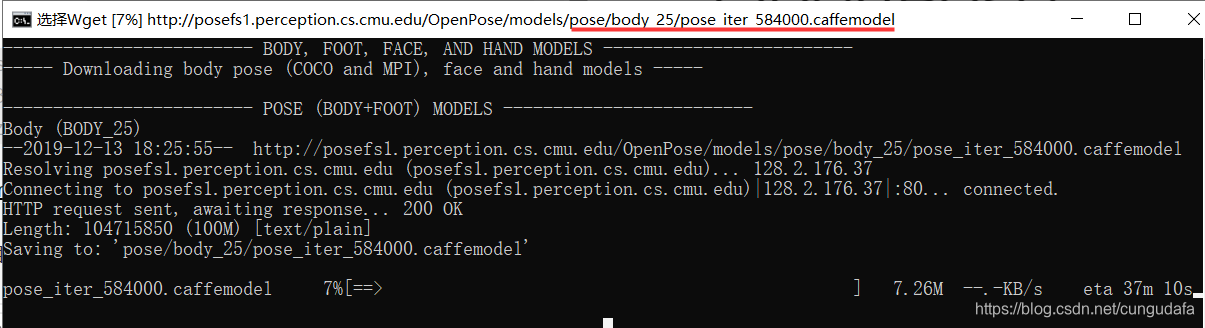
OpenPose 人体姿态模型下载路径:
BODY25:http://posefs1.perception.cs.cmu.edu/OpenPose/models/pose/body_25/pose_iter_584000.caffemodel
COCO: http://posefs1.perception.cs.cmu.edu/OpenPose/models/pose/coco/pose_iter_440000.caffemodel
MPI: http://posefs1.perception.cs.cmu.edu/OpenPose/models/pose/mpi/pose_iter_160000.caffemodel
(2)主要模型介绍
- 目录
openpose分别检测:人脸、人手、人姿态(又分为三种数据集,mpi为较小的数据集)

- 一个简单地demo:
Windows10 + python3.7 + anaconda3 + jupyter5.6.0
import cv2
import time
import numpy as np
import matplotlib.pyplot as plt
import os
# Load a Caffe Model
if not os.path.isdir('model'):
os.mkdir("model")
protoFile = "D:/myworkspace/JupyterNotebook/openpose/openpose-master/models/pose/mpi/pose_deploy_linevec_faster_4_stages.prototxt"
weightsFile = "D:/myworkspace/JupyterNotebook/openpose/openpose-master/models/pose/mpi/pose_iter_160000.caffemodel"
# Specify number of points in the model
nPoints = 15
POSE_PAIRS = [[0,1], [1,2], [2,3], [3,4], [1,5], [5,6], [6,7], [1,14], [14,8], [8,9], [9,10], [14,11], [11,12], [12,13] ]
net = cv2.dnn.readNetFromCaffe(protoFile, weightsFile)
# Read Image
im = cv2.imread("D:/myworkspace/JupyterNotebook/openpose/tf-pose-estimation-master/images/apink1.jpg")
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
inWidth = im.shape[1]
inHeight = im.shape[0]
# Convert image to blob
netInputSize = (368, 368)
inpBlob = cv2.dnn.blobFromImage(im, 1.0 / 255, netInputSize, (0, 0, 0), swapRB=True, crop=False)
net.setInput(inpBlob)
# Run Inference (forward pass)
output = net.forward()
# Display probability maps
plt.figure(figsize=(20,10))
plt.title('Probability Maps of Keypoints')
for i in range(nPoints):
probMap = output[0, i, :, :]
displayMap = cv2.resize(probMap, (inWidth, inHeight), cv2.INTER_LINEAR)
plt.subplot(3, 5, i+1); plt.axis('off'); plt.imshow(displayMap, cmap='jet')
# Extract points
# X and Y Scale
scaleX = float(inWidth) / output.shape[3]
scaleY = float(inHeight) / output.shape[2]
# Empty list to store the detected keypoints
points = []
# Confidence treshold
threshold = 0.1
for i in range(nPoints):
# Obtain probability map
probMap = output[0, i, :, :]
# Find global maxima of the probMap.
minVal, prob, minLoc, point = cv2.minMaxLoc(probMap)
# Scale the point to fit on the original image
x = scaleX * point[0]
y = scaleY * point[1]
if prob > threshold :
# Add the point to the list if the probability is greater than the threshold
points.append((int(x), int(y)))
else :
points.append(None)
# Display Points & Skeleton
imPoints = im.copy()
imSkeleton = im.copy()
# Draw points
for i, p in enumerate(points):
cv2.circle(imPoints, p, 8, (255, 255,0), thickness=-1, lineType=cv2.FILLED)
cv2.putText(imPoints, "{}".format(i), p, cv2.FONT_HERSHEY_SIMPLEX, 1, (255,0,0), 2, lineType=cv2.LINE_AA)
# Draw skeleton
for pair in POSE_PAIRS:
partA = pair[0]
partB = pair[1]
if points[partA] and points[partB]:
cv2.line(imSkeleton, points[partA], points[partB], (255, 255,0), 2)
cv2.circle(imSkeleton, points[partA], 8, (255, 0, 0), thickness=-1, lineType=cv2.FILLED)
plt.figure(figsize=(20,10))
plt.subplot(121); plt.axis('off'); plt.imshow(imPoints);
#plt.title('Displaying Points')
plt.subplot(122); plt.axis('off'); plt.imshow(imSkeleton);
#plt.title('Displaying Skeleton')
plt.show()
- 运行效果:
标出了15个人体姿态特征点


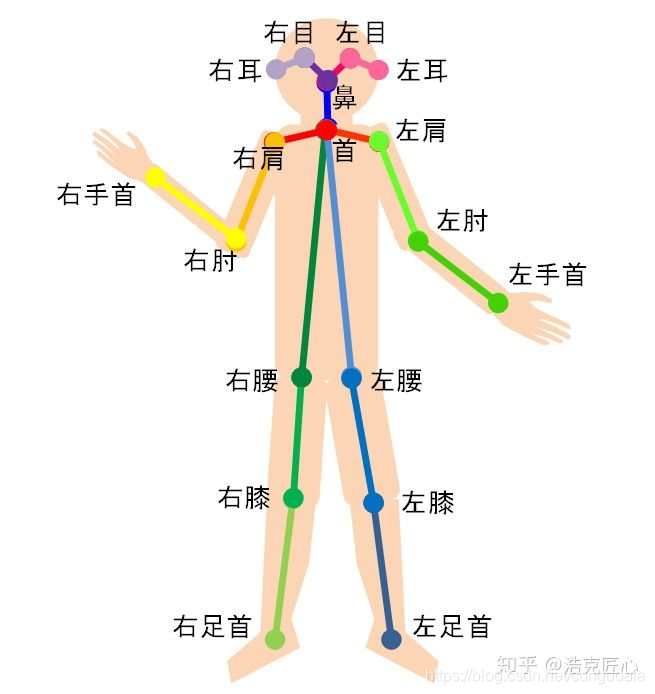
mpi15个关键点参考说明:

(3)主要模型参考图
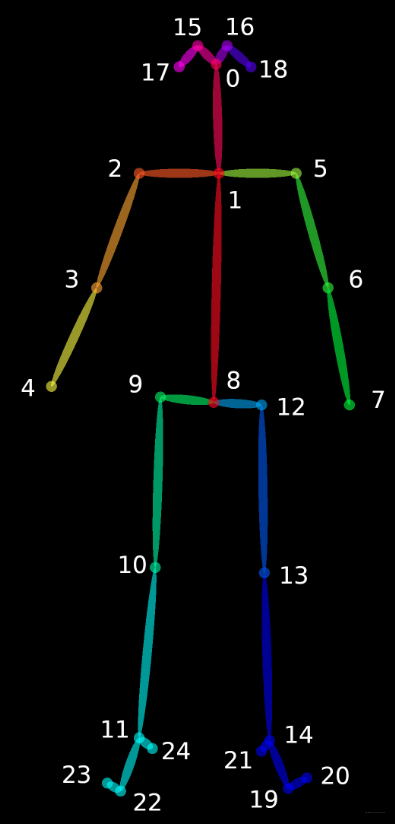
# Body25: 25 points
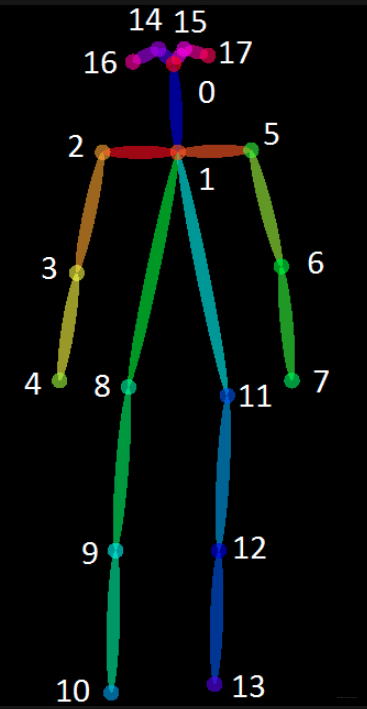
# COCO: 18 points
# MPI: 15 points
左:BODY_25, 右:COCO
Face
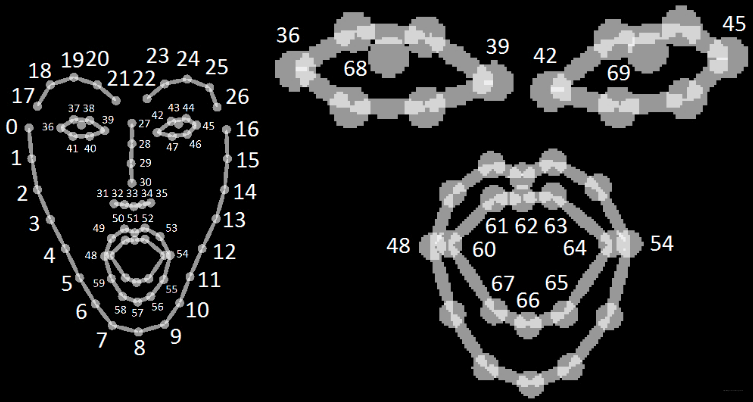
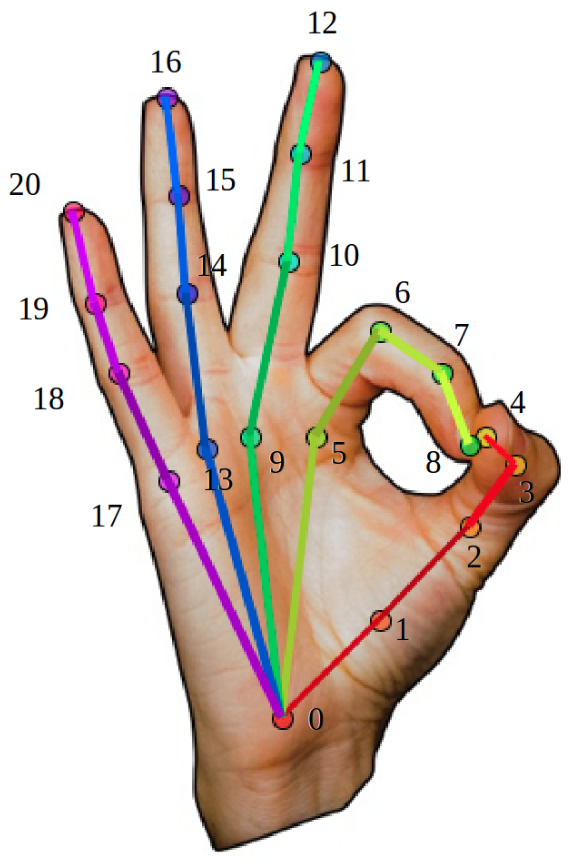
Hand
(4)人体姿态各模型检测
#!/usr/bin/python3
#!--*-- coding: utf-8 --*--
from __future__ import division
import cv2
import time
import numpy as np
import matplotlib.pyplot as plt
import os
class general_pose_model(object):
def __init__(self, modelpath, mode="BODY25"):
# 指定采用的模型
# Body25: 25 points
# COCO: 18 points
# MPI: 15 points
self.inWidth = 368
self.inHeight = 368
self.threshold = 0.1
if mode == "BODY25":
self.pose_net = self.general_body25_model(modelpath)
elif mode == "COCO":
self.pose_net = self.general_coco_model(modelpath)
elif mode == "MPI":
self.pose_net = self.get_mpi_model(modelpath)
def get_mpi_model(self, modelpath):
self.points_name = {
"Head": 0, "Neck": 1,
"RShoulder": 2, "RElbow": 3, "RWrist": 4,
"LShoulder": 5, "LElbow": 6, "LWrist":
7, "RHip": 8, "RKnee": 9, "RAnkle": 10,
"LHip": 11, "LKnee": 12, "LAnkle": 13,
"Chest": 14, "Background": 15 }
self.num_points = 15
self.point_pairs = [[0, 1], [1, 2], [2, 3],
[3, 4], [1, 5], [5, 6],
[6, 7], [1, 14],[14, 8],
[8, 9], [9, 10], [14, 11],
[11, 12], [12, 13]
]
prototxt = os.path.join(
modelpath,
"pose/mpi/pose_deploy_linevec_faster_4_stages.prototxt")
caffemodel = os.path.join(
modelpath,
"pose/mpi/pose_iter_160000.caffemodel")
mpi_model = cv2.dnn.readNetFromCaffe(prototxt, caffemodel)
return mpi_model
def general_coco_model(self, modelpath):
self.points_name = {
"Nose": 0, "Neck": 1,
"RShoulder": 2, "RElbow": 3, "RWrist": 4,
"LShoulder": 5, "LElbow": 6, "LWrist": 7,
"RHip": 8, "RKnee": 9, "RAnkle": 10,
"LHip": 11, "LKnee": 12, "LAnkle": 13,
"REye": 14, "LEye": 15,
"REar": 16, "LEar": 17,
"Background": 18}
self.num_points = 18
self.point_pairs = [[1, 0], [1, 2], [1, 5],
[2, 3], [3, 4], [5, 6],
[6, 7], [1, 8], [8, 9],
[9, 10], [1, 11], [11, 12],
[12, 13], [0, 14], [0, 15],
[14, 16], [15, 17]]
prototxt = os.path.join(
modelpath,
"pose/coco/pose_deploy_linevec.prototxt")
caffemodel = os.path.join(
modelpath,
"pose/coco/pose_iter_440000.caffemodel")
coco_model = cv2.dnn.readNetFromCaffe(prototxt, caffemodel)
return coco_model
def general_body25_model(self, modelpath):
self.num_points = 25
self.point_pairs = [[1, 0], [1, 2], [1, 5],
[2, 3], [3, 4], [5, 6],
[6, 7], [0, 15], [15, 17],
[0, 16], [16, 18], [1, 8],
[8, 9], [9, 10], [10, 11],
[11, 22], [22, 23], [11, 24],
[8, 12], [12, 13], [13, 14],
[14, 19], [19, 20], [14, 21]]
prototxt = os.path.join(
modelpath,
"pose/body_25/pose_deploy.prototxt")
caffemodel = os.path.join(
modelpath,
"pose/body_25/pose_iter_584000.caffemodel")
coco_model = cv2.dnn.readNetFromCaffe(prototxt, caffemodel)
return coco_model
def predict(self, imgfile):
img_cv2 = cv2.imread(imgfile)
img_height, img_width, _ = img_cv2.shape
inpBlob = cv2.dnn.blobFromImage(img_cv2,
1.0 / 255,
(self.inWidth, self.inHeight),
(0, 0, 0),
swapRB=False,
crop=False)
self.pose_net.setInput(inpBlob)
self.pose_net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
self.pose_net.setPreferableTarget(cv2.dnn.DNN_TARGET_OPENCL)
output = self.pose_net.forward()
H = output.shape[2]
W = output.shape[3]
print(output.shape)
# vis heatmaps
self.vis_heatmaps(img_file, output)
#
points = []
for idx in range(self.num_points):
probMap = output[0, idx, :, :] # confidence map.
# Find global maxima of the probMap.
minVal, prob, minLoc, point = cv2.minMaxLoc(probMap)
# Scale the point to fit on the original image
x = (img_width * point[0]) / W
y = (img_height * point[1]) / H
if prob > self.threshold:
points.append((int(x), int(y)))
else:
points.append(None)
return points
def vis_heatmaps(self, imgfile, net_outputs):
img_cv2 = cv2.imread(imgfile)
plt.figure(figsize=[10, 10])
for pdx in range(self.num_points):
probMap = net_outputs[0, pdx, :, :]
probMap = cv2.resize(
probMap,
(img_cv2.shape[1], img_cv2.shape[0])
)
plt.subplot(5, 5, pdx+1)
plt.imshow(cv2.cvtColor(img_cv2, cv2.COLOR_BGR2RGB))
plt.imshow(probMap, alpha=0.6)
plt.colorbar()
plt.axis("off")
plt.show()
def vis_pose(self, imgfile, points):
img_cv2 = cv2.imread(imgfile)
img_cv2_copy = np.copy(img_cv2)
for idx in range(len(points)):
if points[idx]:
cv2.circle(img_cv2_copy,
points[idx],
8,
(0, 255, 255),
thickness=-1,
lineType=cv2.FILLED)
cv2.putText(img_cv2_copy,
"{}".format(idx),
points[idx],
cv2.FONT_HERSHEY_SIMPLEX,
1,
(0, 0, 255),
2,
lineType=cv2.LINE_AA)
# Draw Skeleton
for pair in self.point_pairs:
partA = pair[0]
partB = pair[1]
if points[partA] and points[partB]:
cv2.line(img_cv2,
points[partA],
points[partB],
(0, 255, 255), 3)
cv2.circle(img_cv2,
points[partA],
8,
(0, 0, 255),
thickness=-1,
lineType=cv2.FILLED)
plt.figure(figsize=[10, 10])
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(img_cv2, cv2.COLOR_BGR2RGB))
plt.axis("off")
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(img_cv2_copy, cv2.COLOR_BGR2RGB))
plt.axis("off")
plt.show()
if __name__ == '__main__':
print("[INFO]Pose estimation.")
img_file = "D:/myworkspace/JupyterNotebook/openpose/tf-pose-estimation-master/images/apink1.jpg"
#
start = time.time()
modelpath = "D:/myworkspace/JupyterNotebook/openpose/openpose-master/models/"
# pose_model = general_pose_model(modelpath, mode="BODY25")# 可以三选一
# pose_model = general_pose_model(modelpath, mode="COCO")
pose_model = general_pose_model(modelpath, mode="MPI")
print("[INFO]Model loads time: ", time.time() - start)
start = time.time()
res_points = pose_model.predict(img_file)
print("[INFO]Model predicts time: ", time.time() - start)
pose_model.vis_pose(img_file, res_points)
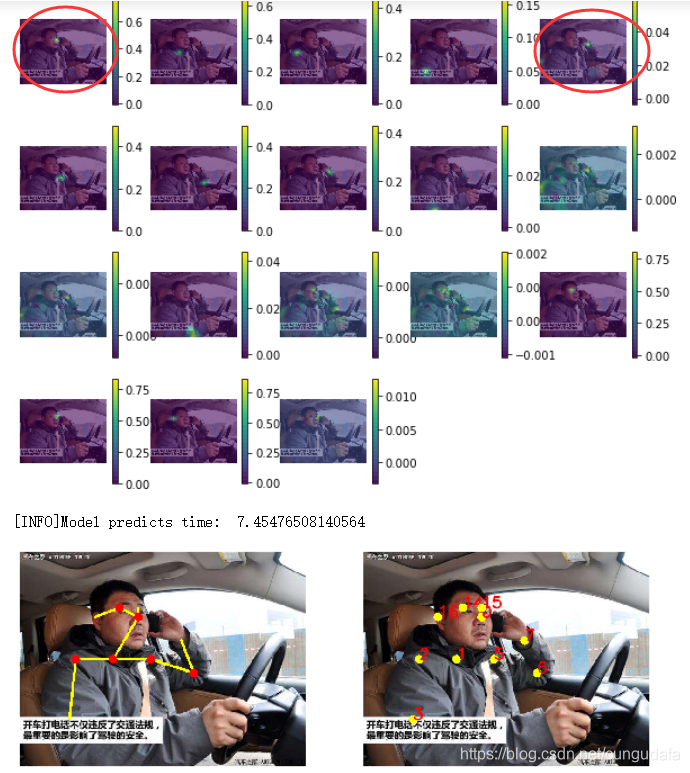
由图示我们可以发现,
-
接电话 可以计算右手到右耳的距离(左手倒左耳的距离)来进行判断,即点4到点16的距离(点7到点17的距离)。
-
抽烟 可以用双手到鼻的距离来进行判断,即点4,7到点0的距离。
多人姿态估计参考:https://www.aiuai.cn/aifarm946.html
(5)手部检测
模型快速下载:
/models/hand/pose_deploy.prototxt
/models/hand/pose_iter_102000.caffemodel
# 参考:https://blog.csdn.net/zziahgf/article/details/90706693
# 作者:AIHGF
#!/usr/bin/python3
#!--*-- coding: utf-8 --*--
from __future__ import division
import os
import cv2
import time
import numpy as np
import matplotlib.pyplot as plt
class general_pose_model(object):
def __init__(self, modelpath):
self.num_points = 22
self.point_pairs = [[0,1],[1,2],[2,3],[3,4],
[0,5],[5,6],[6,7],[7,8],
[0,9],[9,10],[10,11],[11,12],
[0,13],[13,14],[14,15],[15,16],
[0,17],[17,18],[18,19],[19,20]]
# self.inWidth = 368
self.inHeight = 368
self.threshold = 0.1
self.hand_net = self.get_hand_model(modelpath)
def get_hand_model(self, modelpath):
prototxt = os.path.join(modelpath, "hand/pose_deploy.prototxt")
caffemodel = os.path.join(modelpath, "hand/pose_iter_102000.caffemodel")
hand_model = cv2.dnn.readNetFromCaffe(prototxt, caffemodel)
return hand_model
def predict(self, imgfile):
img_cv2 = cv2.imread(imgfile)
img_height, img_width, _ = img_cv2.shape
aspect_ratio = img_width / img_height
inWidth = int(((aspect_ratio * self.inHeight) * 8) // 8)
inpBlob = cv2.dnn.blobFromImage(img_cv2, 1.0 / 255, (inWidth, self.inHeight), (0, 0, 0), swapRB=False, crop=False)
self.hand_net.setInput(inpBlob)
output = self.hand_net.forward()
# vis heatmaps
self.vis_heatmaps(imgfile, output)
#
points = []
for idx in range(self.num_points):
probMap = output[0, idx, :, :] # confidence map.
probMap = cv2.resize(probMap, (img_width, img_height))
# Find global maxima of the probMap.
minVal, prob, minLoc, point = cv2.minMaxLoc(probMap)
if prob > self.threshold:
points.append((int(point[0]), int(point[1])))
else:
points.append(None)
return points
def vis_heatmaps(self, imgfile, net_outputs):
img_cv2 = cv2.imread(imgfile)
plt.figure(figsize=[10, 10])
for pdx in range(self.num_points):
probMap = net_outputs[0, pdx, :, :]
probMap = cv2.resize(probMap, (img_cv2.shape[1], img_cv2.shape[0]))
plt.subplot(5, 5, pdx+1)
plt.imshow(cv2.cvtColor(img_cv2, cv2.COLOR_BGR2RGB))
plt.imshow(probMap, alpha=0.6)
plt.colorbar()
plt.axis("off")
plt.show()
def vis_pose(self, imgfile, points):
img_cv2 = cv2.imread(imgfile)
img_cv2_copy = np.copy(img_cv2)
for idx in range(len(points)):
if points[idx]:
cv2.circle(img_cv2_copy, points[idx], 8, (0, 255, 255), thickness=-1,
lineType=cv2.FILLED)
cv2.putText(img_cv2_copy, "{}".format(idx), points[idx], cv2.FONT_HERSHEY_SIMPLEX,
1, (0, 0, 255), 2, lineType=cv2.LINE_AA)
# Draw Skeleton
for pair in self.point_pairs:
partA = pair[0]
partB = pair[1]
if points[partA] and points[partB]:
cv2.line(img_cv2, points[partA], points[partB], (0, 255, 255), 3)
cv2.circle(img_cv2, points[partA], 8, (0, 0, 255), thickness=-1, lineType=cv2.FILLED)
plt.figure(figsize=[10, 10])
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(img_cv2, cv2.COLOR_BGR2RGB))
plt.axis("off")
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(img_cv2_copy, cv2.COLOR_BGR2RGB))
plt.axis("off")
plt.show()
if __name__ == '__main__':
print("[INFO]Pose estimation.")
imgs_path = "D:/myworkspace/JupyterNotebook/openpose/images"
img_files = [os.path.join(imgs_path, img_file) for img_file in os.listdir(imgs_path)]
#
start = time.time()
modelpath = "D:/myworkspace/JupyterNotebook/openpose/openpose-master/models/"
pose_model = general_pose_model(modelpath)
print("[INFO]Model loads time: ", time.time() - start)
for img_file in img_files:
start = time.time()
res_points = pose_model.predict(img_file)
print("[INFO]Model predicts time: ", time.time() - start)
pose_model.vis_pose(img_file, res_points)
print("[INFO]Done.")


(6)驾驶员危险驾驶检测
# 单人姿态估计
#!/usr/bin/python3
#!--*-- coding: utf-8 --*--
from __future__ import division
import cv2
import time
import numpy as np
import matplotlib.pyplot as plt
import os
class general_pose_model(object):
def __init__(self, modelpath, mode="COCO"):
# COCO: 18 points
self.inWidth = 368
self.inHeight = 368
self.threshold = 0.1
self.pose_net = self.general_coco_model(modelpath)
self.num_points = 22
self.point_pairs = [[0,1],[1,2],[2,3],[3,4],
[0,5],[5,6],[6,7],[7,8],
[0,9],[9,10],[10,11],[11,12],
[0,13],[13,14],[14,15],[15,16],
[0,17],[17,18],[18,19],[19,20]]
self.hand_net = self.get_hand_model(modelpath)
def get_hand_model(self, modelpath):
prototxt = os.path.join(modelpath, "hand/pose_deploy.prototxt")
caffemodel = os.path.join(modelpath, "hand/pose_iter_102000.caffemodel")
hand_model = cv2.dnn.readNetFromCaffe(prototxt, caffemodel)
return hand_model
def general_coco_model(self, modelpath):
self.points_name = {
"Nose": 0, "Neck": 1,
"RShoulder": 2, "RElbow": 3, "RWrist": 4,
"LShoulder": 5, "LElbow": 6, "LWrist": 7,
"RHip": 8, "RKnee": 9, "RAnkle": 10,
"LHip": 11, "LKnee": 12, "LAnkle": 13,
"REye": 14, "LEye": 15,
"REar": 16, "LEar": 17,
"Background": 18}
self.num_points = 18
self.point_pairs = [[1, 0], [1, 2], [1, 5],
[2, 3], [3, 4], [5, 6],
[6, 7], [1, 8], [8, 9],
[9, 10], [1, 11], [11, 12],
[12, 13], [0, 14], [0, 15],
[14, 16], [15, 17]]
prototxt = os.path.join(modelpath,"pose/coco/pose_deploy_linevec.prototxt")
caffemodel = os.path.join(modelpath,"pose/coco/pose_iter_440000.caffemodel")
coco_model = cv2.dnn.readNetFromCaffe(prototxt, caffemodel)
return coco_model
def predict(self, imgfile):
img_cv2 = cv2.imread(imgfile)
img_height, img_width, _ = img_cv2.shape
inpBlob = cv2.dnn.blobFromImage(img_cv2,
1.0 / 255,
(self.inWidth, self.inHeight),
(0, 0, 0),
swapRB=False,
crop=False)
self.pose_net.setInput(inpBlob)
self.pose_net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
self.pose_net.setPreferableTarget(cv2.dnn.DNN_TARGET_OPENCL)
output = self.pose_net.forward()
H = output.shape[2]
W = output.shape[3]
print(output.shape)
#
points = []
for idx in range(self.num_points):
probMap = output[0, idx, :, :] # confidence map.
# Find global maxima of the probMap.
minVal, prob, minLoc, point = cv2.minMaxLoc(probMap)
# Scale the point to fit on the original image
x = (img_width * point[0]) / W
y = (img_height * point[1]) / H
if prob > self.threshold:
points.append((int(x), int(y)))
else:
points.append(None)
return points
def predict_hand(self, imgfile):
img_cv2 = cv2.imread(imgfile)
img_height, img_width, _ = img_cv2.shape
aspect_ratio = img_width / img_height
inWidth = int(((aspect_ratio * self.inHeight) * 8) // 8)
inpBlob = cv2.dnn.blobFromImage(img_cv2, 1.0 / 255, (inWidth, self.inHeight), (0, 0, 0), swapRB=False, crop=False)
self.hand_net.setInput(inpBlob)
output = self.hand_net.forward()
#
points = []
for idx in range(self.num_points):
probMap = output[0, idx, :, :] # confidence map.
probMap = cv2.resize(probMap, (img_width, img_height))
# Find global maxima of the probMap.
minVal, prob, minLoc, point = cv2.minMaxLoc(probMap)
if prob > self.threshold:
points.append((int(point[0]), int(point[1])))
else:
points.append(None)
return points
def vis_pose(self, imgfile, points):
img_cv2 = cv2.imread(imgfile)
img_cv2_copy = np.copy(img_cv2)
for idx in range(len(points)):
if points[idx]:
cv2.circle(img_cv2_copy, points[idx], 8, (0, 255, 255), thickness=-1,
lineType=cv2.FILLED)
cv2.putText(img_cv2_copy, "{}".format(idx), points[idx], cv2.FONT_HERSHEY_SIMPLEX,
1, (0, 0, 255), 2, lineType=cv2.LINE_AA)
# Draw Skeleton
for pair in self.point_pairs:
partA = pair[0]
partB = pair[1]
if points[partA] and points[partB]:
cv2.line(img_cv2, points[partA], points[partB], (0, 255, 255), 3)
cv2.circle(img_cv2, points[partA], 8, (0, 0, 255), thickness=-1, lineType=cv2.FILLED)
plt.figure(figsize=[10, 10])
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(img_cv2, cv2.COLOR_BGR2RGB))
plt.axis("off")
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(img_cv2_copy, cv2.COLOR_BGR2RGB))
plt.axis("off")
plt.show()
if __name__ == '__main__':
print("[INFO]Pose estimation.")
#
start = time.time()
print("[INFO]Model loads time: ", time.time() - start)
start = time.time()
res_points = pose_model.predict(img_file)
print("[INFO]Model predicts time: ", time.time() - start)
pose_model.vis_pose(img_file, res_points)
print("[INFO]Pose estimation.")
imgs_path = "D:/myworkspace/JupyterNotebook/openpose/images"
img_files = [os.path.join(imgs_path, img_file) for img_file in os.listdir(imgs_path)]
#
start = time.time()
modelpath = "D:/myworkspace/JupyterNotebook/openpose/openpose-master/models/"
pose_model = general_pose_model(modelpath, mode="COCO")
pose_model_hand = general_pose_model(modelpath)
print("[INFO]Model loads time: ", time.time() - start)
for img_file in img_files:
start = time.time()
res_points_hand = pose_model_hand.predict_hand(img_file)
res_points = pose_model.predict(img_file)
print("[INFO]Model predicts time: ", time.time() - start)
pose_model.vis_pose(img_file, res_points)
pose_model_hand.vis_pose(img_file, res_points_hand)
print("[INFO]Done.")
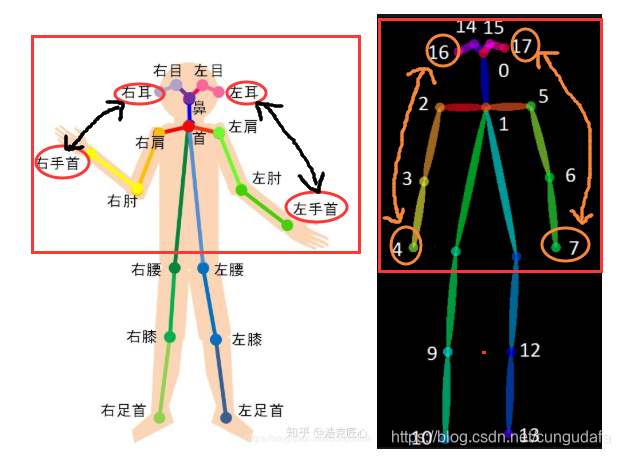
效果是比较明显的:


由下图可知:危险驾驶判断因素——主要应该以人体姿态参考为主,手关键点检测为辅。

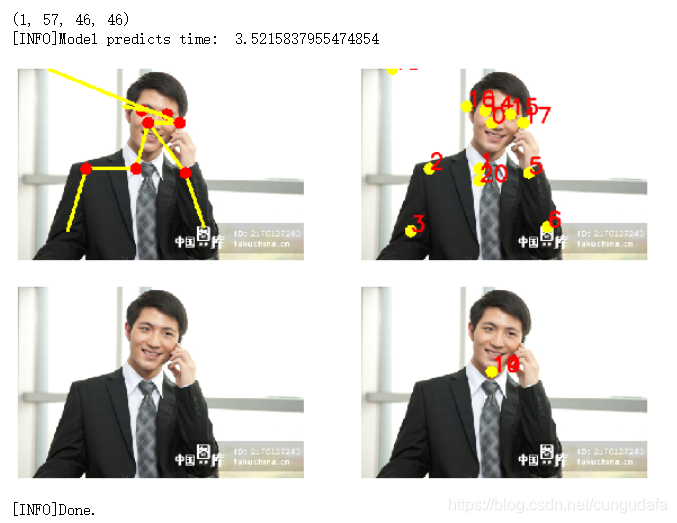
视频检测及判断标准待补充~
我是分界线!
其他
基于temsorflow的openpose安装
windows10 + python3.7 + anaconda3 + jupyter5.6
-
第一步:查看本地temsorflow版本号:
'1.13.1'python import tensorflow as tf tf.__version__ tf.__path__
-
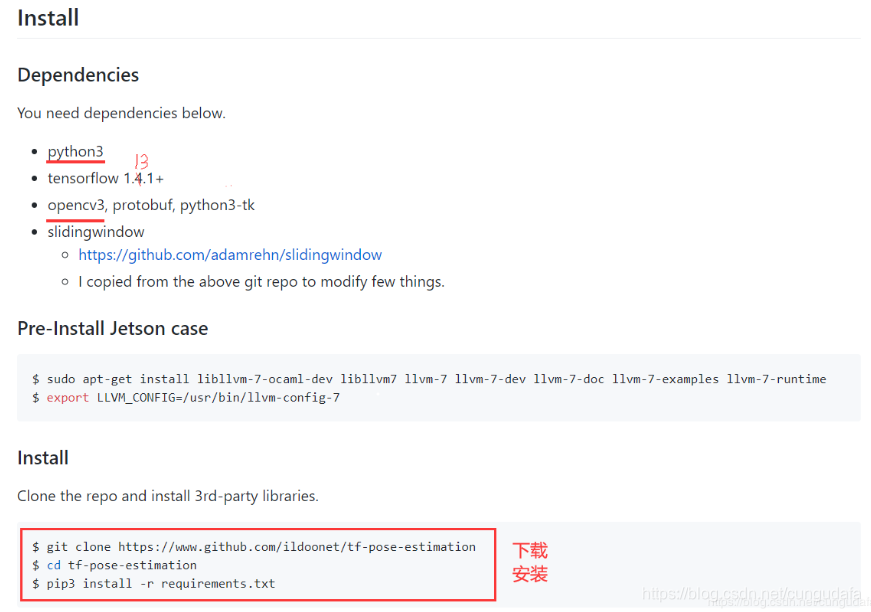
第二步:下载tf-pose-estimation
链接:https://github.com/ildoonet/tf-pose-estimation
-
第三步:根据提示配置依赖
解压压缩包,找到requirements.txt

运行这个txt需要安装git,之前安装过的可以跳过这一节
https://git-scm.com/downloads/
如果不愿意安装git,可以单独安装每一个模块:
pip install argparse或者conda install argparse打开控制台批量安装
pip install -r requirements.txt
遇见问题:下载pycocotools失败,是因为和anaconda环境冲突了,用conda命令下载
conda install pycocotools即可。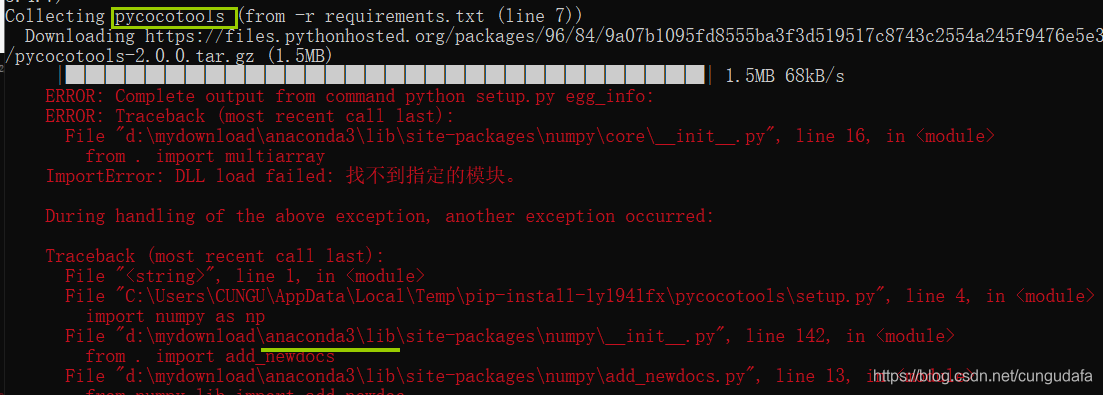
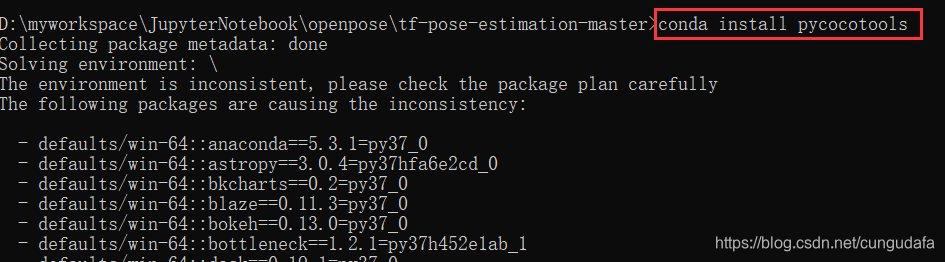
同理,如果txt中有任何下载冲突失败的,都可以用conda install+xxxxx -
第四步:没错,官方还要我们用swig编译一次
ok,先来下swig,同样之前下过的可以跳过这一节
我的swig版本是swigwin-4.0.1,下载地址是 http://www.swig.org/download.html具体步骤:
解压zip,比如:D:\mydownload
添加环境变量到path, 比如: D:\mydownload\swigwin-4.0.1
在命令行执行: swig --help,不报错说明安装成功了。进入tf_pose/pafprocess目录下,打开控制台安装:
swig -python -c++ pafprocess.i && python3 setup.py build_ext --inplace
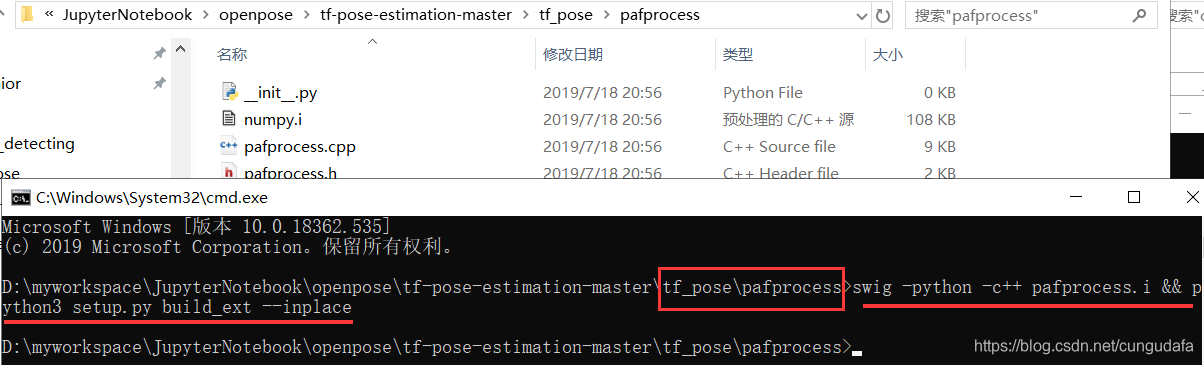
-
第五步:运行示例
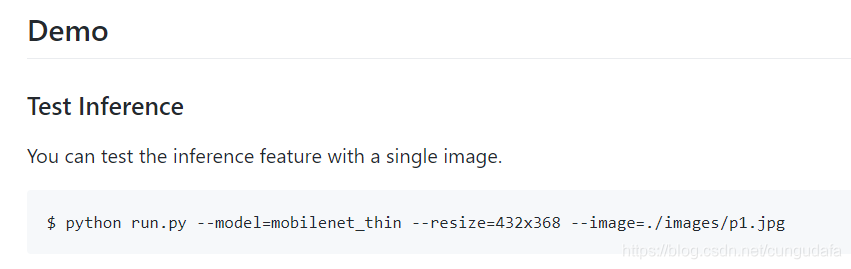
退回到tf-pose-estimation-master目录,打开控制台:
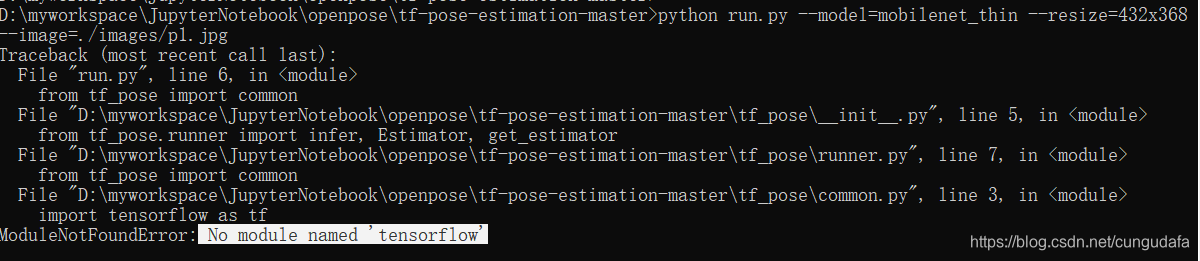
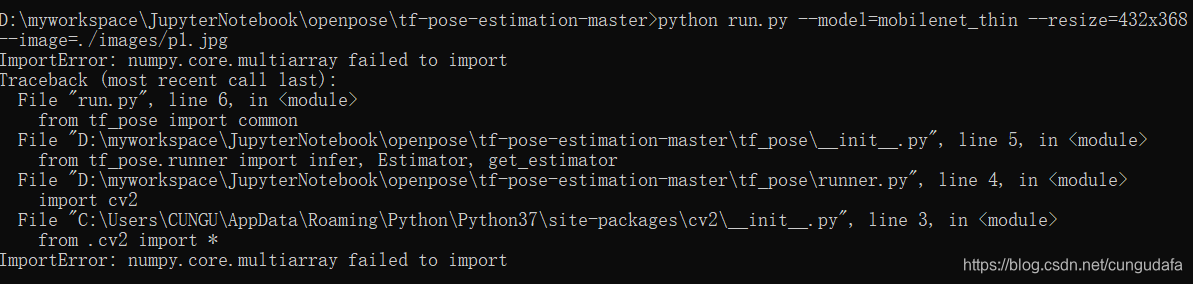
python run.py --model=mobilenet_thin --resize=432x368 --image=./images/p1.jpg
这里有一个报错:import cv2错误:ImportError: numpy.core.multiarray failed to import
pip安装过,但conda环境下没有安装。
用conda安装时,出现警告弹窗:无法定位程序输入点OPENSSL_sk_new_reserve于动态链接库
解决方法:
把Anaconda/DLLS目录下的libssl-1_1-x64 dlls文件复制到 Anaconda/Library/bin 目录下就好了,具体目录到自己的安装目录找哦。
再重新安装conda install numpy
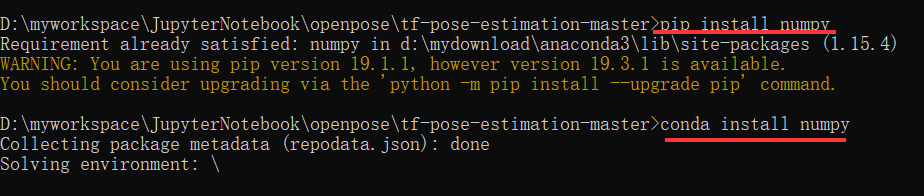
运行依然报错:numpy,强制卸载numpy,下载新版:

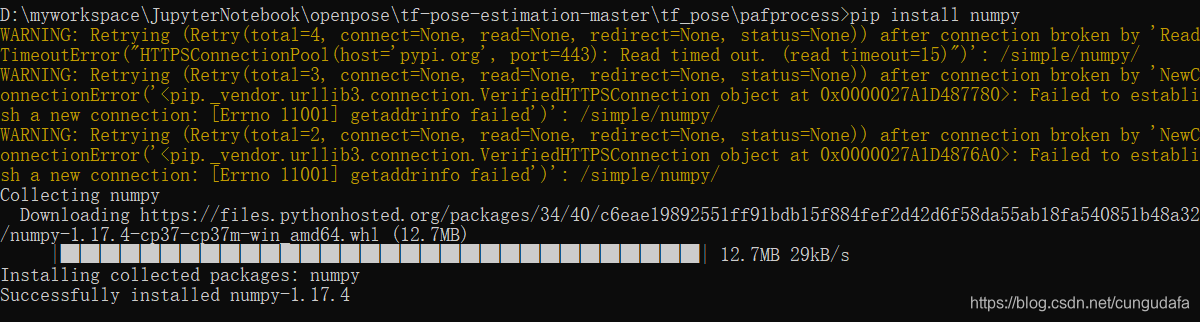
重复第四步swig编译:
成功编译后的文件目录:
运行demo:
遇见问题:找不到TensorFlow:
是因为之前把anaconda的dll补丁替换了,需要重新下载TensorFlow;