在JVM中对象在内存中储存的布局可以分为三个部分:
对象头(Header),实例数据(Instance Data)和对齐填充(Padding)。
对象头(Header) 包含两部分的信息:第一部分用于存储对象自身的运行时数据,如HashCode,GCfen分代年龄,线程持有的锁,偏向线程ID,偏向时间戳等。这部分数据的长度在32位虚拟机和64位虚拟机上长度分别为32bit和64bit,官方称之为“Mark Word”。
由于目前基本都在使用64位JVM的mark word分布,此处不再对32位的结构进行详细说明:
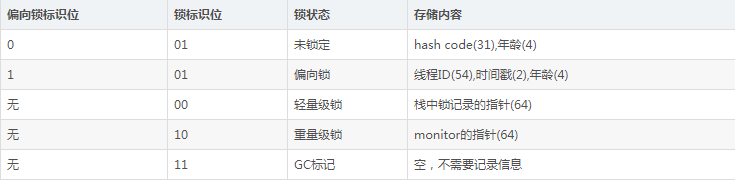
另一部分是类型指针,即对象指向它的类元程序的指针,虚拟机就是通过这个指针来判断这个对象是属于哪个类的实例。
实例数据(Instance Data) 实例数据部分是对象真正存储的有效信息,也是程序代码中所定义的各种类型的字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。这部分的存储顺序会受到虚拟机分配策略参数和字段在java源码中定义顺序的影响。
对齐填充(Padding) 不是必然存在,也没有特别的含义,仅仅起占位符的作用.
