主查询 子查询
概念集中于SELECT语句
之前我们所学习的所有,都是SELECT作为独立的一句 是主干,是爸爸
后面跟着几个儿子比如ON WHERE HAVING GROUP BY 这称为主查询 以SELECT为主干的
但是有没有想过 我们如果SELECT完以后的结果 再次进行SELECT 筛选 应该怎么写呢?
嵌套着写嘛?
对了!
被嵌套的儿子SELECT就是 子查询
概念中 SELECT在其他语句 比如HAVING WHERE ON等里面时 就是子查询
注意子查询要加(),增加代码可读性
扯了那么多 我们看案例:
1️⃣阮菜鸡入职了 有工资了 数据库登记了菜鸡的信息:
请运行下面的代码:
USE data1;
INSERT INTO `employees` (
`employee_id`,
`first_name`,
`last_name`,
`email`,
`phone_number`,
`job_id`,
`salary`,
`commission_pct`,
`manager_id`,
`department_id`,
`hiredate`
)
VALUES
(
2333,
'菜鸡',
'阮',
'SKING',
'233.233.233',
'AD_PRES',
6000.00,
NULL,
NULL,
90,
'2016-03-03 00:00:00'
) ;
2️⃣然后 阮菜鸡悄咪咪的 在公司数据库 拿到了公司的工资表如下:
USE data1;
SELECT
`salary` AS 工资,
CONCAT_WS('-', `last_name`, `first_name`) AS 名字
FROM
employees
ORDER BY 工资

现在问题来了 这么多人 我咋知道谁工资比我高呢?
3️⃣我可以查到我的工资:

加一句
WHERE `last_name` = '阮';
就行了 可以看到是 6000
4️⃣于是 我可以这么找到比我工资高的大佬们:
USE data1;
SELECT
`salary` AS 工资,
CONCAT_WS('-', `last_name`, `first_name`) AS 名字
FROM
employees
WHERE `salary` >= 6000
ORDER BY 工资 DESC;
但是哪一天我工资涨了 我还得查 太累了
另外 我的十几个小伙伴(名字已经列成表了)都等着我 帮忙他们查工资
我岂不是得一个个去对?
5️⃣其实不用:)
你把6000这个数字替换成他们的工资变量就好了嘛
那工资变量是查出来的啊? 本身没有的
那就把查询语句丢进去咯!
USE data1;
SELECT
`salary` AS 工资,
CONCAT_WS('-', `last_name`, `first_name`) AS 名字
FROM
employees
WHERE `salary` >= (SELECT `salary` FROM employees WHERE `last_name` = '阮')
ORDER BY 工资 DESC;

注意:
1️⃣必须有括号
2️⃣SELECT 出来的结果 要什么就写什么 别写多了 没法WHERE比较
比如你这么写:
WHERE `salary` >= (SELECT `salary`,`phone_number` FROM employees WHERE `last_name` = '阮')
加了phone_number,那么WHERE也不知道你想判断什么了
我们给这个套路 丢 SELECT查询语句进去 的套路 就叫做子查询
纲举目张——子查询的分类
我们查工资的案例,有两个特点,
1是 SELECT 子查询语句 放在了WHERE语句后面
2是 子查询的结果只是一个值,也即是标量,一行一列的
那么 我们可以把子查询这么分类:
| 按位置分类 | 子查询结果支持 |
|---|---|
| WHERE HAVING语句后面 | 1️⃣标量子查询 2️⃣列子查询 3️⃣行子查询 |
| SELECT语句后面 | 标量子查询 |
| FROM 语句后面 | 表子查询 |
| EXISTS语句后面 | 表子查询 |
我们还可以这么分类:对于子查询的结果
| 按查询结果分类 | 含义 |
|---|---|
| 标量子查询 | 一行一列 |
| 行子查询 | 一行多列 |
| 列子查询 | 多行一列 |
| 表子查询 | 多行多列 |
你只需要大致有个印象 每种都会说一下的 当然我们按照第一种分类方式学
其中 WHERE语句为重点 因为常用
WHERE语句后的 子查询
巩固之前学的 标量子查询的知识,用一个新案例来说说:
阮菜鸡想知道 自己所在的 No.90 部门 工资福利在公司中的地位如何
那么也就是 有 最高 最低工资还有平均工资 三个参数
对其他部门进行查询 比较 输出结果
我们先来看最低工资 其他的加几个词就出来了
1️⃣得到自己所在部门的最低工资
2️⃣得到所有公司部门的最低工资
3️⃣where限定 哪些部门的最低工资 > 自己No.90最低工资
第1️⃣步:得到自己所在部门的最低工资 简单 直接SELECT出来

USE data1;
SELECT
MIN(`salary`) 最低工资,
`department_id` 部门编号
FROM
employees
WHERE `department_id` = 90;
》》》》等一下:)我不会就是那个“最低工资”的那个人吧2333QAQ
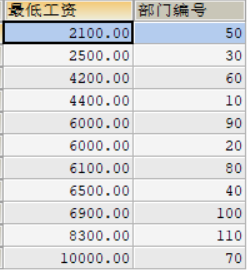
第2️⃣步:用到了GROUP BY分组查询 easy
USE data1;
SELECT
MIN(`salary`) 最低工资,
`department_id` 部门编号
FROM
employees
WHERE `department_id` IS NOT NULL
GROUP BY `department_id`
ORDER BY 最低工资;
还记得GROUP BY是怎么执行的吗?
你可以理解为
先轮询所有的员工 ,然后不满足 (分组前筛选条件)
WHERE `department_id` IS NOT NULL
条件 就排除
再 以部门编号进行分组
每一组中 我找MIN 最低工资
最后 输出
如果我想要 找到最低工资后 再加条件 比如最低工资大于6000的部门查询
那么再用HAVING(分组后筛选条件)
第3️⃣步:子查询 以第一步的位子查询结果 第2️⃣步为主体:
我们先用6000 也就是第一步查到的结果 写成这样
USE data1;
SELECT
MIN(`salary`) 最低工资,
`department_id` 部门编号
FROM
employees
WHERE `department_id` IS NOT NULL
GROUP BY `department_id`
HAVING MIN(`salary`) > 6000
ORDER BY 最低工资;
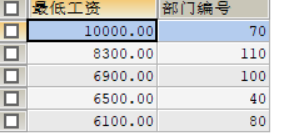
然后 变量放进去 子查询启动:
USE data1;
SELECT
MIN(`salary`) 最低工资,
`department_id` 部门编号
FROM
employees
WHERE `department_id` IS NOT NULL
GROUP BY `department_id`
HAVING MIN(`salary`) > (
SELECT
MIN(`salary`)
FROM
employees
WHERE `department_id` = 90
)
ORDER BY 最低工资 DESC;
当然 我们再加些拓展 我们用平均工资为考量:
USE data1;
SELECT
AVG(`salary`) 平均工资,
MIN(`salary`) 最低工资,
MAX(`salary`) 最高工资,
`department_id` 部门编号
FROM
employees
WHERE `department_id` IS NOT NULL
GROUP BY `department_id`
HAVING AVG(`salary`) > (
SELECT
AVG(`salary`)
FROM
employees
WHERE `department_id` = 90
)
ORDER BY 平均工资 DESC;
结果:

喵喵喵??? 没有报错 没结果??
我们把大于号改成小于等于 看看

哦 原来我们部门这么厉害我拉低了部门的平均工资
至此 WHERE 的标量子查询就结束了 因为是值之间的比较 算是简单的 后面就是行 列 表子查询了 敬请期待
下一站:数据库学习之MySQL (十八)—— 子查询 WHERE 列子查询
