文章地址:https://www.aclweb.org/anthology/N16-1027.pdf
文章标题:Supertagging with LSTMs(超标注LSTMs)NNACL2016
模型和超标签代码:https://bitbucket.org/ashish_vaswani/lstm_supertagger
概念补充:序列标注是自然语言处理领域中历史最悠久的研究课题之一,包括词性标注(Part of speech tagging)和CCG超标注(Combinatory Categorial Grammar supertagging,组合范畴语法超标注)。CCG超标注是许多自然语言处理任务的前序步骤,例如组块(chunking)和句法解析(parsing)。CCG超标注可定义为:给定一个由词构成的序列,要求给序列中的每个词赋予一个CCG超标签。
(参考文献:[1]REKIA KADARI. 基于深度学习模型的CCG超标注[D].哈尔滨工业大学,2018.)
Abstract
在本文中,我们介绍了CCG超标记和解析的最新性能。我们的模型的绝对增益比现有方法高出1.5%。我们分析了几种神经模型的性能,证明了前馈结构在词性标注上可以与双向LSTMs竞争,而对完整句子进行编码的模型对于超标记中长距离句法信息的编码是必要的。
一、Introduction
单词的形态同构标签通常用于各种NLP应用。因此,词性标注和超标注受到了社会的广泛关注。组合范畴语法是一种词典化的语法形式主义,广泛用于句法和语义分析。Supertagging(克拉克,2002;班加罗尔和乔希,2010)分配复杂的语法标签的词,以支持快速和准确的解析。与从Penn Treebank的45个POS标签中选择一个相比,从1200多个CCG标签中选择一个正确的单词来消除歧义是很困难的(Marcus et al., 1993)。除了CCG超标记的大标签空间外,正确地标记一个单词还取决于句子中任意远的句法现象(Hockenmaier and Steedman, 2007)。这是因为超标签编码了关于一个单词在句子中的用法的高度特定的语法信息(例如,参数的类型和位置)。
在本文中,我们证明了双向长短时记忆递归神经网络(Bi-LSTMs) (Graves, 2013;Zaremba等人,2014),可以使用整个句子的信息,是一个自然和强大的CCG超标签架构。除了Bi-LSTM,我们还创建了一个简单但新颖的模型,其性能比之前使用手工特性的最先进的RNN模型(Xu et al., 2015)高出1.5%。与此同时(Lewis et al., 2016)还为Bi-LSTM引入了一种不同的超标记训练方法。我们对各种LSTM体系结构的质量进行了详细的分析,包括前向、后向和双向的,这有助于了解Bi-LSTM利用丰富的语句上下文来执行超标记的能力。我们还表明,基线前馈神经网络(NN)体系结构显著优于之前的前馈神经网络基线,其特征略少,比RNN模型具有更好的准确性(Xu et al., 2015)。
最近,Bi-LSTMs在一个更简单的序列标记任务中实现了高准确性:词性标记(Wang et al., 2015;(Ling et al., 2015)在Penn treebank,与当前的模型有小的改进。然而,与(Wang et al., 2015)相比,我们使用基于局部上下文训练的前馈神经网络模型实现了较强的准确性,表明该任务不需要Bi-LSTMs。我们强大的前馈神经网络基线显示了前馈神经网络在某些任务中的能力。
我们的主要贡献是引入一个新的Bi-LSTM模型在CCG supertagging达到最先进的,在两个CCG supertagging和解析,并详细分析的结果,包括Bi-LSTMs比较和简单的前馈神经网络模型supertagging词类,这表明Bi-LSTMs可能不是必要的额外复杂性的词类,当前上下文比supertagging更大程度上满足。
二、Models And Training
我们使用前馈神经网络模型和双向LSTM (Bi-LSTM)模型。
2.1 Feed-Forward
无论是POS标签还是我们的基线超标签模型,我们都使用了具有两个隐层修正线性单元的前馈神经网络(Nair和Hinton, 2010)。对于超级标记,我们使用比Lewis和Steedman (2014a)稍小的集合,使用一个左右三个单词的带有后缀和大写特征的窗口作为中心单词。然而,与它们不同的是,我们在训练期间观察到的所有超标签类别上进行训练。

在词性标注中,在标注单词wi时,我们只考虑以wi为中心的5个单词窗口的特征。如果wi作为中心,则对于每一个wj,i-2 <= j <= i+2,我们添加wj的小写和一个字符串来编码wj的基本的“word shape”。这种计算通过替换所有序列中的大写字母A,小写字母a,数字9,其他的字符用*表示。最后,我们为wi添加了两个和三个字母的后缀和两个字母的前缀。
2.2 LSTM models
我们用两种Bi-LSTM模型进行了实验。我们训练了一个基本的Bi-LSTM,其中前向和后向Lstm接受输入单词wi并产生隐藏状态→hi和←hi。对于每一个位置,我们生产˜h:

使用超标签嵌入Dti和偏差bti计算输出超标签的非标准化可能性。最后的softmax层计算标准化超级标记的概率。
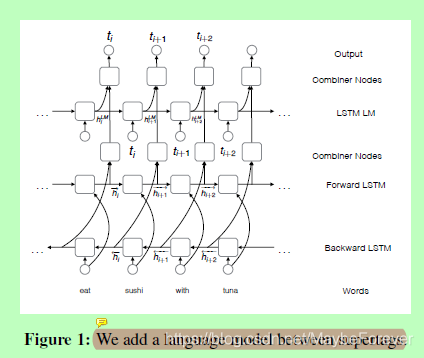
图一:我们在超标签之间添加了一个语言模型
尽管双向 LSTM 可以捕获单词之间的远距离交互,但每个输出标签都是独立预测的。为了显式建模超级标记交互,我们的下一个模型将两个模型(双 LSTM 和 LSTM 语言模型 (LM) 组合在超级标记上(图 1)。在位置 i,LM 接受一个输入超级标记 ti_1,生成隐藏状态 hLM i 和第二个组合器层,由矩阵 WLM 和 W _h 转换 _h i 和 hLM i 转换为类似于 _hi(公式 1)的组合器。输出超级标记概率计算与之前一样,用 hi 替换 @hi。我们将此模型称为双 LSTM_LM。对于我们所有的 LSTM 模型,我们只使用单词作为输入功能。
2.3 Training
我们训练我们的模型,以最大限度地对数可能性的数据与小批量梯度上升。模型的梯度使用反向传播计算(Chauvin和Rumelhart, 1995)。由于gold超标签在训练时可用,而不是在解码时可用,因此在gold超标签上训练的Bi-LSTM-LM可能无法从使用错误预测的超标签所造成的错误中恢复过来。这导致Bi-LSTM-Lm的性能略低于Bi-LSTM(表1中我们将使用黄金超标记的训练称为g-train)。
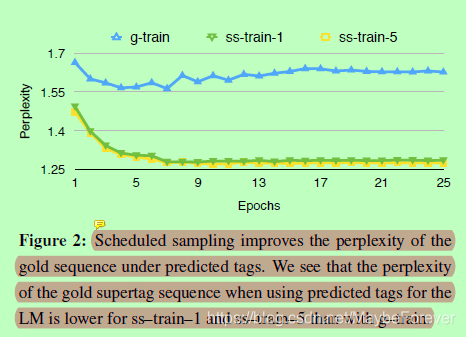
图二:计划采样可改善预测标记下的黄金序列的困惑。我们看到,在使用 LM 的预测标记时,黄金超级标记序列的困惑性低于 g_trains_train_1 和 ss_train_5。
(1)Scheduled sampling
以下(Bengio等人,2015年;Ranzato 等人,2015),对于每个输出令牌,具有一些概率 p,我们使用最有可能预测的超级标记 (arg maxtiP (ti = hi))从位置 i+1 的模型作为输入到位置 i 中的超级标记 LSTM LM 并使用概率为 1 = p 的黄金超级标记。我们将此培训表示为 ss_train_1。我们还尝试使用位置 i = 1 的输出分布中的 5 个最佳以前预测的超标记,并将它们作为位置 i 中的输入作为位矢量馈送到 LM。此外,我们使用它们的概率(在 5 个最佳标记上重新归一化),并在查找期间缩放输入超级标记嵌入及其重新规范化的概率。我们将此设置称为 ss_train_5。在这项工作中,我们使用反向 sigmoid 计划来计算 p,
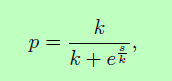
其中s为epoch数,k为调优的超参数。在图2中,我们可以看到,对于开发集,使用计划抽样的训练提高了使用预测超标记时gold超标记序列的复杂性,这表明可以更好地从错误超标记的条件设置中恢复。对于ss-train和g-train,我们使用gold supertags作为输出层,并训练模型以最大化数据的日志可能性。
2.4 Architectures
我们的前馈模型在第一隐层使用2048整流单元,在第二隐层使用50和128整流单元,分别用于词性标注和超标注,并使用64维的输入嵌入。
我们基于LSTM的模型使用了512个隐藏状态。我们使用NPLM工具包将BLLIP语料库(Charniak等人,2000年)和《华尔街日报》Penn Treebank的02-21版连接起来,用7-gram前馈神经语言模型对单词嵌入进行预训练。
2.5 Decoding
我们执行贪婪解码。对于每个位置 i,我们从输出分布中选择最可能的超级标记。对于使用 g_train 和 ss_train_1 训练的双 LSTM_LM 模型,我们从输出分布中馈送最有可能的超标记作为 LM 输入在下一个位置。我们使用光束搜索(大小 12)解码双 LSTM_LMs,这些人员使用 g_train 和 ss_train_1 进行训练。对于使用 ss_train_5 训练的双 LSTM,我们执行类似于训练的贪婪解码,从位置 i = 1 的输出超级标记分布中馈送 k-最佳超级标记,作为位置 i 中的 LM 的输入,以及重新标准化的概率。我们不对 ss_train_5 执行波束解码,因为以前的 k-best 输入已经通过网络捕获不同的路径。
三、Data
对于超标记,我们使用CCGbank的标准分割进行了实验。与以前的工作不同,没有为LSTM模型提取特征,也没有对罕见的类别进行阈值处理。单词小写,数字用@代替。
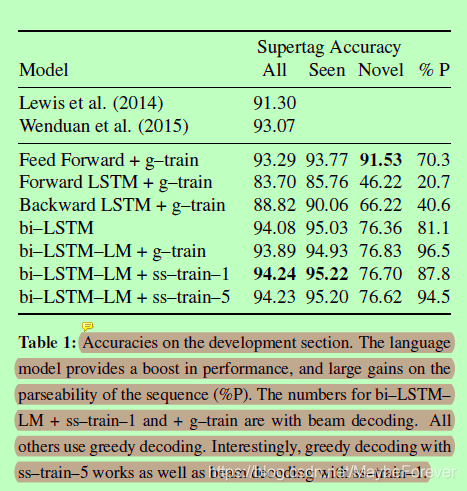
表一:开发部分的精度。语言模型提高了性能,并极大地提高了序列 (%P) 的可解析性。双_LSTM_ LM = ss_train_1 和 + g_train 的数字具有光束解码。所有其他使用贪婪解码。有趣的是,使用 ss_train_5 进行贪婪解码以及使用 ss_train_1 进行光束解码。
CCGbank的培训包含1284个词汇类别(Dev中的394个)。类别分布有很长的尾巴,只有三分之一的类别的频率计数为 10(现有文献使用的阈值)。以下(Lewis and Steedman, 2014b),我们允许该模型预测一个单词的所有类别,而不仅仅是那些在训练数据中观察到该单词同时出现的类别。表1的第三列给出了这些看不见的(word,cat)对的准确性。
四、Results
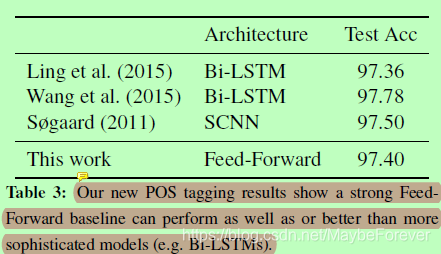
表三:我们新的POS标记结果表明,一个强大的前向基线可以执行得和更复杂的模型(如Bi-LSTMs)一样好或更好。
表3给出了我们的前馈式POS标记结果。我们在开发集上实现了97.28%,在测试上实现了97.4%。虽然略低于最先进水平,但我们使用bi-LSTMs处理现有的工作,并且我们的模型更简单,训练起来更快。
表1显示了在为模型提供额外上下文时性能的稳步提高。前向和后向模型所提供的信息可能在句子中是任意遥远的,但只是在一个特定的方向上。这产生的结果弱于前馈模型,可以看到在一个小窗口内的两个方向。真正的收益是通过双向LSTM实现的,它整合了整个句子的知识。我们增加了一个语言模型并进行了修改训练,进一步提高了成绩。我们最后的模型(Bi-LSTM-LM+ss-train-1模型,带有波束解码)的测试精度为94.5%,比最先进水平高1.5%。
4.1 Parsing
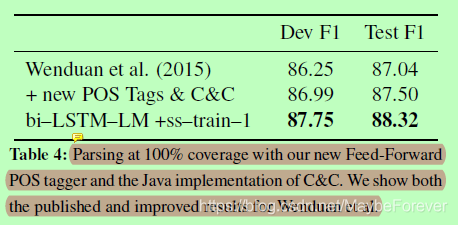
表四:使用我们的新前向POS标记器和C&C的Java实现进行100%覆盖率的解析。我们展示了Wenduan等人发表的和改进的结果。
本文的主要目的是演示双 LSTM 如何从单向或正向方法捕获新的和不同的信息。这种优势也转化为解析的收益。表 4 介绍了两者(Xu 等人,2015 年)和我们的双 LSTM_LM_s_train_1 的新最先进的解析结果。这些结果是使用我们的语音部分标记(表 3)和 C&C 解析器的 Java 实现(Clark 等人,2015 年)实现的(Clark 和 Curran,2007 年)。
4.2 Error Analysis
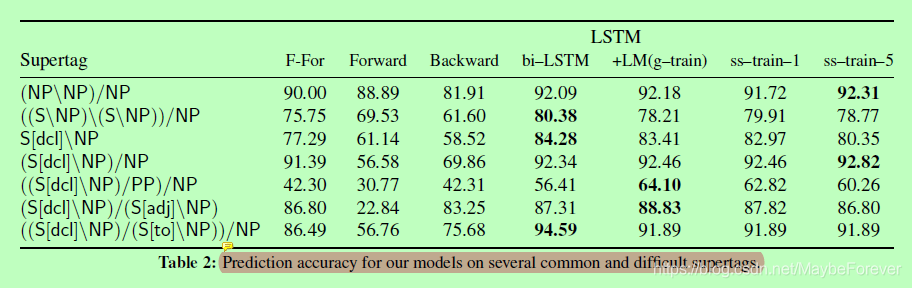
表二:我们的模型在几个常见和困难的超标签上的预测精度。
我们的分析表明,一个词之后的信息比之前的信息信息更加丰富。表 2 比较了我们的模型恢复常见和语法有趣的超级标记的恢复情况。特别是,前进和后退模型,激发了双向方法的需求。
前两行显示介词短语附件决策(名词和动词附加类别分别位于第一行和第二行)。在这里,正向模型优于后向模型,大概是因为知道要修改的单词和介词,比观察介词短语的对象(向后模型可用的信息)更重要。
相反,在大多数剩余类别中,向后模型优于前向模型。(di-)传递动词(第 4 和 5 行)要求了解句子中的未来参数(例如,用相对子句分隔)。由于英语有严格的 SVO 字顺序,因此主题的存在比存在(在)直接对象更可预测。因此,向后模型通常与"进给"模型相媲美也就不足为奇了。
如果正向或向后模型缺少的信息是本地的,则双向模型应执行与"进给-前进"模型相同的操作,而不是以较大幅度超出它。这意味着选择超级标记需要一些远程信息。
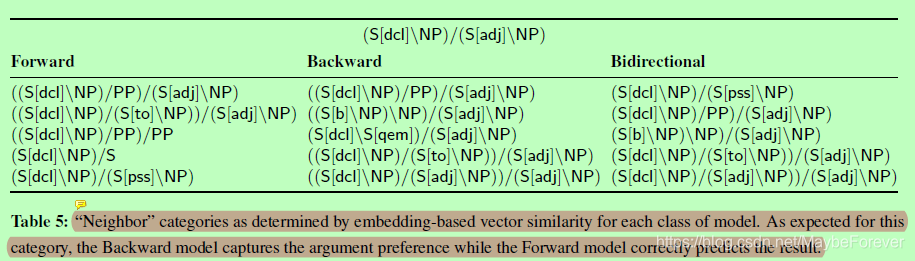
表五:"Neighbor"类别,由每个模型类的基于嵌入的矢量相似性确定。正如此类别的预期,向后模型捕获参数首选项,而前进模型正确预测结果。
(1)Embeddings
此外,我们还可以通过根据所学的嵌入调查类别的最近邻居来可视化模型捕获的信息。表 5 显示了"前进"、后退和双向模型下的(S_dcl_NP)/(S_adj_NP)的最近邻类别。
我们看到,正向模型学习与查询类别的内部结构,但参数列表几乎是随机的。相反,落后模型主要基于最后参数进行分类,也许只是因为英语文本的可预测 SVO 性质而共享主题参数的相似性。但是,由于缺少正向上下文,模型错误地将类别与不太常见的第一个参数(例如 S_qem]) 相关联。最后,双向嵌入似乎可以干净地捕获正向和向后模型的强度。
(2)Consistency and Internal Structure
由于超级标记结构高度结构化,因此 CCG 组合器必须允许其在句子中的共发生。如果不显式编码此,语言模型会显著增加导致有效分析的预测序列的百分比(表 2 的最后一列)。
(3)Sparsity
我们的方法的一个考虑是,我们不门槛罕见的类别或使用任何标签字典;我们的模型呈现与CCG类别的全部空间,尽管长尾。这并没有损害性能,模型学会了成功地使用几个类别,这些类别超出了传统阈值的频繁类别集。此外,双向模型至少正确使用的类别总数远远高于其他型号(394 中的 270 vs. 220),尽管大量未使用的类别 (120) 表明仍然存在巨大的改进空间。
五、Conclusions and Future Work
由于具有语言模型的Bi-LSTM 在决策时对整个句子进行编码,因此我们在超级标记和分析方面表现出了巨大的收益。今后的工作将研究改善稀有类别的性能。
