参考:
1.B站《机器学习-白板推导系列(十七)》https://www.bilibili.com/video/av34444816/
2.https://zhuanlan.zhihu.com/p/44042528 (中文译版)
https://createmomo.github.io/2017/09/12/CRF_Layer_on_the_Top_of_BiLSTM_1/ (原版)这里只放了第一章的链接
3.https://www.jianshu.com/p/55755fc649b1 (中文译版)
https://blog.echen.me/2012/01/03/introduction-to-conditional-random-fields/ (原版)
前言
在做命名实体识别的时候发现现在最流行最稳定的方法也就是使用BiLSTM+CRF模型来实现的了,但是由于CRF公式实在是看起来很劝退,一直也没有搞懂,这两天又看了很多大神写的文章,有了一点理解,但是还不是很透彻,还属于流在表面的理解,不过还是先记录下来把。
分类算法
监督学习的任务就是学习一个模型,应用这一模型,对给定的输入预测相应的输出。监督学习方法又可以分为生成方法和判别方法。所学习到的模型分别称为生成模型和判别模型。
生成模型是对联合概率分布进行建模P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:
,上次写到的朴素贝叶斯法和接下来要写到的隐马尔可夫模型都属于生成模型。
判别模型由数据直接学习条件概率分布P(Y|X)作为预测的模型,即判别模型。判别方法关心的是对给定的输入X,应该预测什么样的输出Y,典型的判别模型包括:k近邻法、感知机、决策树,以及后面要提到的最大熵马尔可夫模型和条件随机场。
HMM
HMM即为隐马尔可夫模型,还记得上次写的朴素贝叶斯模型,他的标签一般情况下是一个0/1值,一般用来进行二分类,比如说对垃圾邮件进行鉴别,其实只要把朴素贝叶斯的二值标签序列化,即每一个输入都会对应一个标签,即序列标注问题,,这个模型就变成了隐马尔可夫模型。 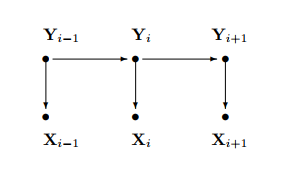
隐马尔可夫模型由三个元素确定,分别是初始状态概率向量
、状态转移概率矩阵A,和观测概率矩阵B组成。矩阵A决定了模型从一个状态转移到另一个状态,矩阵B从当前状态决定当前的观测值是多少。
状态转移概率矩阵A与初始状态概率向量
确定了隐藏的马尔科夫链,生成不可观测的状态序列。观测概率矩阵B确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列。
隐马尔可夫模型作了两个基本假设:
(1)齐次马尔可夫性假设:隐藏的马尔科夫链在任一时刻t的状态只依赖于前一时刻的状态。即
(2)观测独立性假设:假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关。即
隐马尔可夫模型的3个基本问题:
(1)概率计算问题。给定模型
和观测序列
,并己算在模型
下观测序列O出现的概率
。
(2)学习问题。已知观测序列
,估计模型
参数,使得在该模型下观测序列概率
最大。即用极大似然估计的方法估计参数。
(3)预测问题,也称为解码问题。已知模型
和观测序列
,求对给定观测序列条件概率
最大的状态序列
。即给定观测序列,求最有可能的对应的状态序列。
MEMM
HMM模型用到了两个比较强的假设,分别是齐次马尔可夫假设和观测独立性假设,这两个假设都属于比较强的假设,方便了建模计算的同时也丢掉了一些信息,并且HMM属于生成模型,是对联合概率分布进行的建模,而对于我们的序列标注问题,其实要求的是条件概率,所以用判别模型更好,于是就有了MEMM,最大熵马尔可夫模型,它打破了观测独立性假设(更加合理),并且属于判别式模型。
最大熵马尔科夫模型利用判别式模型的特点,直接对每一个时刻的状态建立一个分类器,然后将所有的分类器的概率值连乘起来。为了实现是对整个序列进行的分类,在每个时刻t时,它的特征不仅来自当前观测值
,而且还来自前一状态值
。
MEMM由于最大熵模型在每一个时刻,针对不同的前一状态进行归一化操作,这种局部的归一化操作会导致标注偏置问题:
MEMM存在标注偏置问题,即MEMM倾向于选择拥有更少转移的状态(具体见下图)。归根结底的原因就是MEMM的局部归一化问题,不能获得全局最优解。

我关于标注偏置问题的理解就是由于MEMM是局部归一化即每一次状态转移都要计算归一化概率,所以当一个状态拥有更少的转移状态的时候,他的概率相对就会大一些,MEMM更倾向于选择转移状态少的路径。
如上图,状态一永远更加倾向于转向状态二,而状态二总是倾向于保留在状态二,然而通过维特比算法解码可以得出:
P(1-> 1-> 1-> 1)= 0.4 x 0.45 x 0.5 = 0.09 ,
P(2->2->2->2)= 0.2 X 0.3 X 0.3 = 0.018,
P(1->2->1->2)= 0.6 X 0.2 X 0.5 = 0.06,
P(1->1->2->2)= 0.4 X 0.55 X 0.3 = 0.066
最佳路径是1->1->1->1,从状态2可能转移出去的概率包括1、2、3、4、5,概率在可能的状态上分散了,而状态1转移出去的可能状态仅仅为状态1和2,概率更加集中。正是由于局部归一化的影响,隐藏状态会倾向于转移到那些后续状态可能更少的状态上,以提高整体的后验概率,这就是标注偏置问题产生的根本原因。CRF解决了这个问题
CRF

从图的结构可以看出他把Y标签之间的箭头去掉了,变成了双向,其实也就是打破了HMM中的齐次马尔可夫假设。
在命名实体识别(NER)任务中我们可以知道,我们必须要建立一定的规则,否则标注出来的结果很容易出错,比如说B-PER后面不能加I-ORG,诸如此类,我们可以通过一定的规则来对标注后的序列进行打分,打分越高表示这个标注序列越靠谱。上面提到一个B-PER后接一个I-ORG就是一个特征函数,我们可以定义一个特征函数的集合,用这个特征函数集合来为一个标注序列打分,并据此选出最靠谱的标注序列。
定义特征函数:
特征函数就是一个接收4个参数的函数:
- 句子s
- i,表示句子s中的第i个单词
- ,表示要评分的标注序列给第i个单词标注的词性
-
,表示要评分的标注序列给第i-1个单词标注的词性
它的输出为1或0,给每一个特征函数 赋予一个权重 。现在只要有一个句子s,有一个标注序列,我们就可以用刚刚定义的特征函数集来对 进行评分。
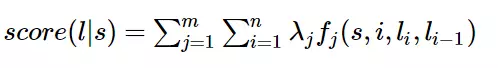
上式中有两个求和,里面的求和用来求句子中每个位置单词的特征值之和,外面的求和对每一个特征函数 求和。
对这个函数进行指数化和标准化,我们就可以得到标注序列的概率值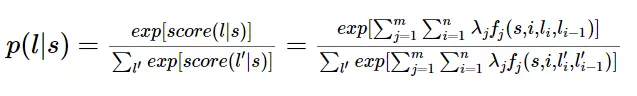
这里介绍的其实是条件随机场的简化形式表示,还有另外两种分别为参数化形式和矩阵形式,具体的可以参考李航的书,这里我只是方便自己理解。
条件随机场的概率计算问题可以像HMM一样引入前向-后向算法,学习算法有改进的迭代尺度法IIS,梯度下降法和拟牛顿法。预测算法用维特比算法。
Bi-LSTM-CRF中的CRF层
BiLSTM-CRF的模型结构如图:

他的输入是训练好的词嵌入向量,输出的是每个单词对应的预测的标签。
我们先看一下BiLSTM层输出的是什么:

BiLSTM层的输入表示该单词对应各个类别的分数。如W0,BiLSTM节点的输出是1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) and 0.05 (O)。这些分数将会是CRF层的输入。
其实可以看出来,假如没有CRF层,我们照样也可以标注出来,我们选LSTM层输出的每个节点的最高分数,也可以做出正确的预测,但是有时候会出现问题,就是之前提到过的可能会出现B-PER后跟一个I-ORG这种问题,这时候就需要CRF层了。
预测错误的例子:

CRF层可以学习到句子的约束条件,就是之前提到的特征方程,这些约束可以在训练数据时被CRF层自动学习得到。
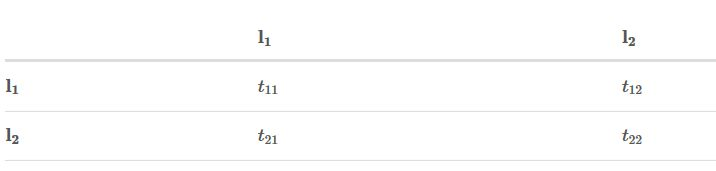
我们定义两个分数,一个是发射分数,发射分数来自于BILSTM的输出,由输入的字符预测到各个标签的分数,一个转移分数是从一个标签到下一个标签的分数
转移分数:可以看到下面这个表已经学习到了一些特征,比如说从B-PER到I-ORG的分数特别小。

定义损失函数:
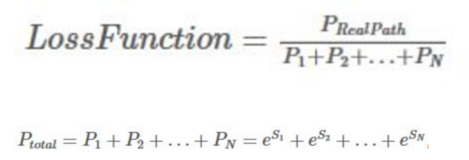
一个序列有十种可能的结果的话,那分母就是从P1+P10,如果第十条路径是真实路径,也就是说第十条是正确预测结果,那么第十条路径的分数应该是所有可能路径里得分最高的。
每个分数Si为Si = EmissionScore + TransitionScore,两个分数就是上面提到的分数。
我们现在把损失函数对数话,然后加上负号,可以推出:

前面两项很好求,就是真实路径的分数,我们现在只要求出:
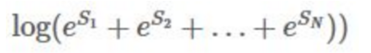
具体迭代过程参考https://zhuanlan.zhihu.com/p/44042528
最后得到结果:

我们最终得到了我们想要的目标,
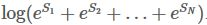
我们的句子中共有3个单词2个类别,所以共有8条路径。
预测过程:
STEP1:假设我们的句子由3个单词组成
,并且我们已经从训练过程中得到发射分数和转移分数,如下:

STEP2:
你将会看到两类变量:obs 和 previous。Previous存储了上一个步骤的最终结果,obs代表当前单词包含的信息(发射分数)。
Alpha0 是历史最佳的分数 ,alpha1 是最佳分数所对应的类别索引。这两类变量的详细信息待会会做说明。
首先看
,
,
首先观测第一个单词
,很显然,如果
,显然最佳预测结果是L2。
从
到
:
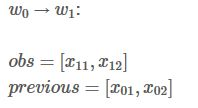

然后更新
的值:
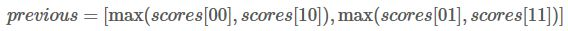
例如
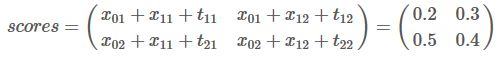

那么我们的
他的意思可以这样理解,第一列的0.2和0.5代表从
预测
属于L1的概率分别为0.2和0.5,分数最高的是0.5,即
为L2,
为L1的的得分最高。路径为L2->L1,同理L2->L2的分数为0.4。
本次迭代中,我们把最佳分数存到

最佳分数对应的类别索引存到
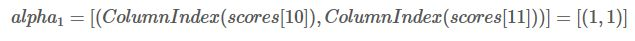
(1,1)其实就是代表0.5和0.4都是第(1)行,即L2。
接着

上面scores有错误,应该是0.5+x21+t11 等.
假如我们的结果为:

则:
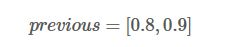
最佳路径为L1->L2,因为最高分出现在第一行第二列,即从L1->L2。
同时,每个类别对应的最大得分添加到alpha0 和 alpha1中:

从这两个数组可以预测出最佳路径,首先看(0.8,0.9)最大分数出现在第二列,即L2,对应的
为0,即前一个预测结果为L1,再看(0.5,0.4),已经知道
的预测是L1了,所以看对应0.5的索引值是1,即
的预测值是L2。
所以我们预测的最佳路径是L2->L1->L2
