https://www.cnblogs.com/MouseDong/p/11134039.html
1.简介
redis是以键值对存储数据的,所以对象又分为键对象和值对象,即存储一个key-value键值对会创建两个对象,键对象和值对象。键对象总是一个字符串对象,而值对象可以是五大对象中的任意一种。
在Redis中,每个对象都是存储在RedisObject中(Redis自己实现的包装类数据结构),下面逐一分析
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
// ...
} robj;
2.String——Int、SDS
字符串string的底层是 通过SDS(简单动态字符串)和直接存储 实现的(SDS是Redis在C的基础上自定义实现的一种数据结构),String有三种编码方式:int(整数型,直接以RedisObject存储)、raw(大于等于32位,转换为sds进行存储)、embstr(小于32位,同上)
int编码
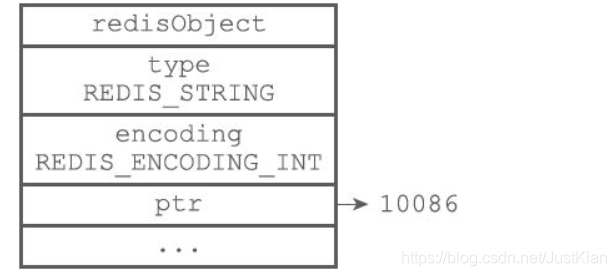
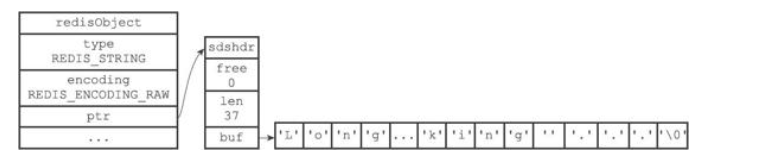
raw 编码
字符串对象总结:
- 在Redis中,存储long、double类型的浮点数是先转换为字符串SDS再进行存储的。
- raw与embstr编码效果是相同的,不同在于内存分配与释放,raw两次,embstr一次。
- embstr内存块连续,能更好的利用缓存在来的优势
- int编码和embstr编码如果做追加字符串等操作,满足条件下会被转换为raw编码;
- embstr编码的对象是只读的,一旦修改会先转码到raw。
3.List——ZipList、Linkedlist
List的编码可以是ziplis(压缩列表——可类比数组,压缩列表的内存块是连续的,并分配内存的次数一次即可)t和linkedlist(双向链表)之一。可以用于消息队列类型场景,入队出队方便。
4.Hash——ZipList、HashTable
Redis hash 特别适用于存储对象。哈希对象的编码可以是ziplist和hashtable之一。
(1)ziplist编码
ziplist编码的哈希对象底层实现是压缩列表
(2)hashtable编码
hashtable编码的哈希对象底层实现是字典,哈希对象中的每个key-value对都使用一个字典键值对来保存。字典键值对即是,字典的键和值都是字符串对象,字典的键保存key-value的key,字典的值保存key-value的value。
5.Set——IntSet、HashSet
集合对象的编码可以是intset和hashtable之一。从名称就可以知道,IntSet即为整数类集合对象。
(1)intset编码
intset编码的集合对象底层实现是整数集合,所有元素都保存在整数集合中。IntSet底层实现是有序集合(类比于有序数组),所以其查找时间复杂度为O(log n),但规模小的情况下与HashTable的O(1)没有太大差别。 可能这时你会发问,set不是无序的吗,怎么IntSet是有序的,其实set的最主要作用是无重复集合,有序无序它并不关心,所以Redis在实现时,规模小的情况下为了节约内存,所以采取了时间换空间的策略。
集合对象使用intset编码需要满足两个条件:一是所有元素都是整数值;二是元素个数小于等于512个;不满足任意一条都将使用hashtable编码。
(2)hashtable编码
hashtable编码的集合对象底层实现是字典,字典的每个键都是一个字符串对象,保存一个集合元素,不同的是字典的值都是NULL;可以参考java中的hashset结构。
6.Zset(有序集合)——ZipList、SkipList
有序集合的编码可以是ziplist和skiplist之一。
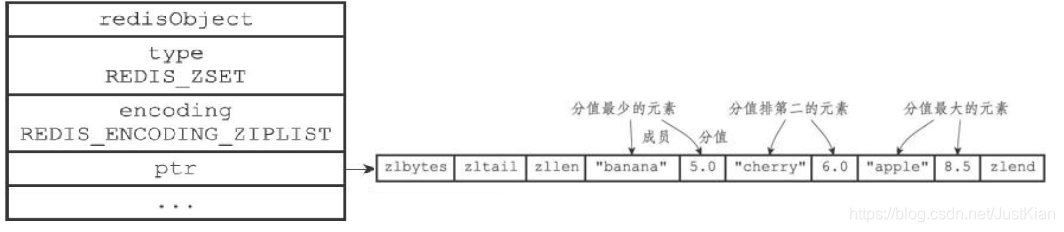
(1)ziplist编码
ziplist编码的有序集合对象底层实现是压缩列表,其结构与哈希对象类似,不同的是两个紧密相连的压缩列表节点,第一个保存元素的成员,第二个保存元素的分值,而且分值小的靠近表头,大的靠近表尾。
(2)skiplist编码
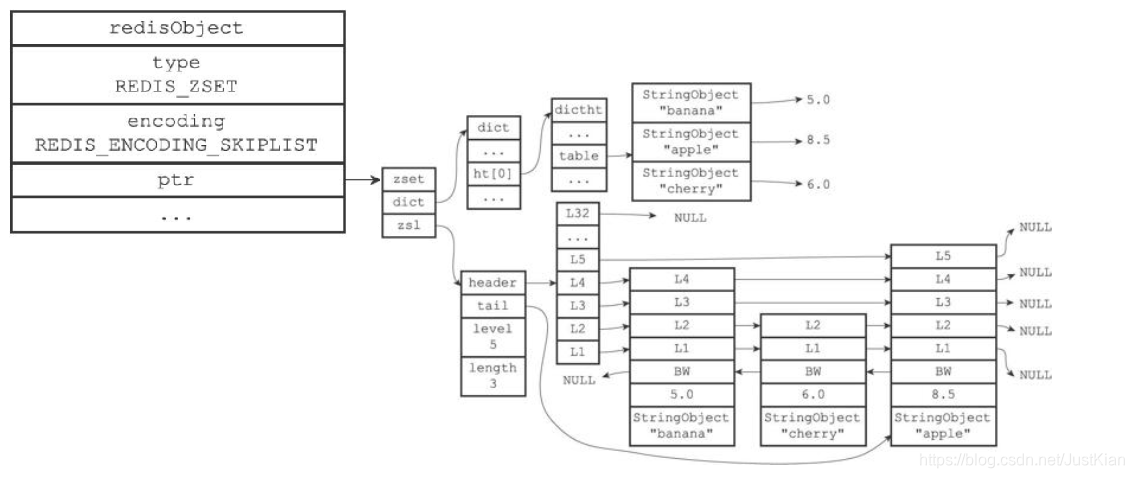
skiplist编码的有序集合对象底层实现是跳跃表+字典:
-
每个跳跃表节点都保存一个集合元素,并按分值从小到大排列;节点的object属性保存了元素的成员,score属性保存分值;
-
字典的每个键值对保存一个集合元素,字典的键保存元素的成员,字典的值保存分值。
为何skiplist编码要同时使用跳跃表和字典实现?
- 字典的作用:可以在O(1)时间复杂度内通过对象查找到分值,如zscore命令
- 跳表的作用:避免每次按分值区间查找(zrange)或者rank(zrank)的时候都要进行排序
- 跳跃表优点是有序,区间查找更快,但是查询具体某个分值复杂度为O(logn);字典查询分值复杂度为O(1) ,但是无序。所以结合两个的优点进行实现。
- 虽然采用两个结构但是集合的元素成员和分值是共享的,两种结构通过指针指向同一地址,不会浪费内存。
跳表就是有序链表的二分结构索引,类似于B+树
https://blog.csdn.net/sinat_30186009/article/details/84193800
7.总结
在Redis的五大数据对象中,string对象是唯一个可以被其他四种数据对象作为内嵌对象的;
列表(list)、哈希(hash)、集合(set)、有序集合(zset)底层实现都用到了压缩列表结构,并且使用压缩列表结构的条件都是在元素个数比较少、字节长度较短的情况下;
四种数据对象使用压缩列表的优点:
(1)节约内存,减少内存开销,Redis是内存型数据库,所以一定情况下减少内存开销是非常有必要的。
(2)减少内存碎片,压缩列表的内存块是连续的,并分配内存的次数一次即可。
(3)压缩列表的新增、删除、查找操作的平均时间复杂度是O(N),在N再一定的范围内,这个时间几乎是可以忽略的,并且N的上限值是可以配置的。
(4)四种数据对象都有两种编码结构,灵活性增加。
