令笔者对pandas印象最为深刻的一件事,就是在pandas中已经内置了很多数据导入导出方法,然而本人并不了解,在一次小项目的工作中曾手写了一个从excel表格导入数据到DataFrame的python脚本。这个糗事让笔者深感代码能力急需加强!
为了让那次教训刻骨铭心,也为了避免广大读者再走类似的弯路,本文主要介绍关于pandas的数据导入导出功能,理解起来非常简单。
pandas支持的导入导出数据格式多种多样,有csv,excel,sql,json,html,pickle等。
虽然支持众多数据格式,但各类数据格式导入导出的操作方法千篇一律,了解其中一个便能掌握全部,因而本文以数据分析中常见的csv格式为例,介绍pandas的数据导入导出功能。
1 从csv文件导入数据到pandas
例中,要读取的csv文件与代码程序在同一目录下:
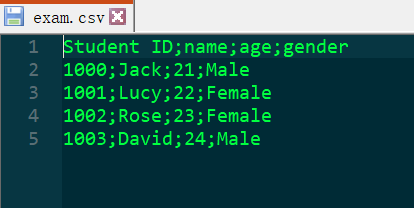
exam.csv文件内容如下:
程序将csv文件读入到data变量中:
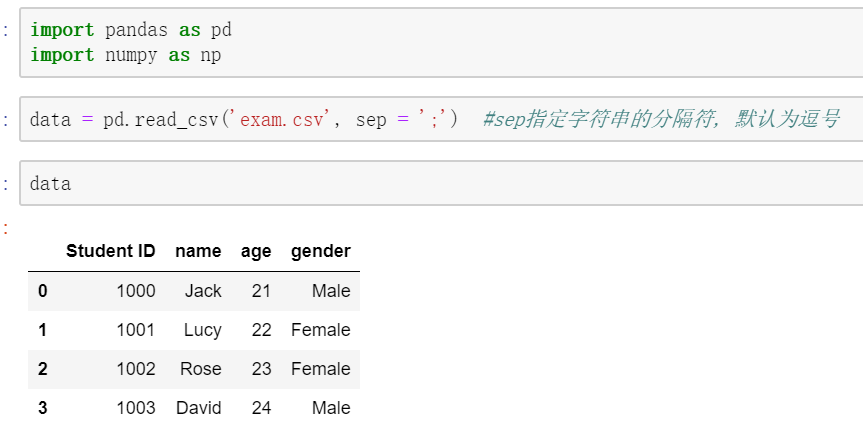
从中可以看到:pandas默认会将csv文件的第一行作为列名导入进来。
如果导入的数据文件中没有保存列名,则在导入时可以手动添加列名,示例如下:
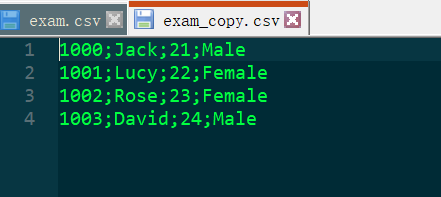
先复制一份上述csv文件,去掉原有列名部分,其余不变:
扫描二维码关注公众号,回复:
9061885 查看本文章

在读入数据时,指定列名:

2 导出数据到csv文件

为方便起见,我们将刚才读入的数据再次导出到同目录下的daochu.csv文件:

查看daochu.csv文件中的内容:
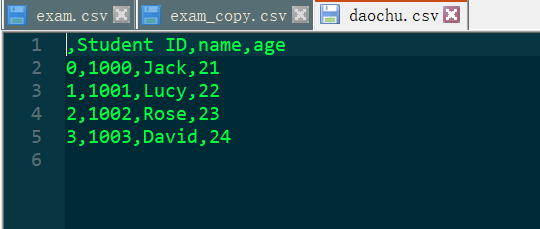
可以看到:导出时选择了三列数据,并且输出列名(header=True)与行索引(index=True),索引默认是“0,1,2,3”的形式。
导出csv文件函数的参数比较多,可以对导出后的文件内容进行多种设定,具体每一个参数的作用效果还要靠诸位亲自探索。