一,UNET
UNET可以称为医学图像语义分割的基石,而且经常作为baseline与其他模型对比。一般的器官分割,只要是正正常常,边界比较明显的,没什么特殊情况的,一般UNET就能做得很好。
UNET结构如下:

UNET特点:
1.UNET结构和FCN十分相似,但是两者之间区分很大的一个地方就是,跳接(skip connection)处UNET是使用连接方式,即UNET采用将特征在channel维度拼接在一起,形成更厚的特征。而FCN融合时使用的对应点相加,并不形成更厚的特征
2.UNET是一个网络概念,里面的参数是可以变的。一般的UNET会把输入图片经过5次下采样,每次使其分辨率减少一般,此阶段称为编码器阶段。然后也有经过5次上采样(采用反卷积或插值法),使特征图的分辨率增大一倍,此阶段称为解码器阶段。中间的skip connection阶段十分重要,本人试过把skip connection阶段去掉或者加上卷积层的话,UNET的效果会变得非常差。
二,UNET++
关于UNET++,我认为UNET++的作为已经在知乎上介绍得非常清楚了:https://zhuanlan.zhihu.com/p/44958351
UNET++结构如下:

三,Attention-UNET
Attention-UNET的结构如下:
在对 encoder 每个分辨率上的特征与 decoder 中对应特征进行拼接之前,使用了一个AGs,重新调整了encoder的输出特征。该模块生成一个门控信号,用来控制不同空间位置处特征的重要性,如下图中红色圆圈所示。

Attention Gate(AGs)的结构如下:
AGs由有2个输入,如下图所示,分别是g和xl。g是较低分辨率的输入,如上图的绿色箭头。g个xl进入AGs前,g会先被上采样到跟xl分辨率相同。然后g和xl都会经过卷积核为1x1步长为1的卷积操作。1x1的卷积首先有降维的作用(降低通道维度),然后能让通道特征跨维度融合。经过激活函数ReLu增加非线性性,ReLu后的1x1卷积后主要作用是降维,把通道数降为1,然后激活函数sigmoid负责把特征图里的值映射到0~1之间,这时就得到注意力特征图了,最后一步就是把这个注意力特征与原来的xl相乘。得到最后的特征图。综合而言就是使用拥有较高语义特征的特征图来指导当前特征图进行注意力的选择。

四,R2U-NET
在R2U-NET论文中,此网络被用于眼球血管分割和皮肤癌分割,肺部分割任务中。R2U-NET全称为基于UNET的循环残差神经网络。
R2U-NET的结构如下:

上图中,有圈的地方就是R2U-NET中的循环结构,R2U-NET就是在UNET中嵌入了这种循环结构的网络,该循环结构详细说明如下图:
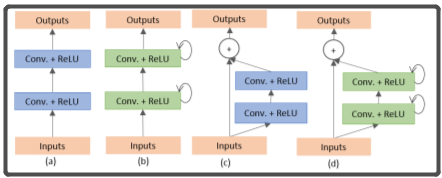
(a)为普通的两个conv模块,(b)为使用了循环卷积的模块,(c)为使用了残差卷积的模块,(d)是同时使用了残差卷积和循环卷积的模块
一个循环卷积模块其实就是t(t是可以自己设置的超参数)个普通的conv(conv+BN+ReLU)的堆叠,只不过,除了第一个conv的输入是x(输入图片)之外,后边的conv的输入是前一个conv的输出加上x作为输入。
五,CENET
CENET的结构如下:
CENET的编码器用的是resnet34。中间部分则由作者提供的DAC和RMP模块组成,DAC和RMP模块等下会有介绍。

下图中,左边的是DAC模块。可以看出作者的DAC模块很大程度地参考了inception模块,通过提供不同尺度的卷积核来获得多尺度的空间信息。感受野大的卷积操作可以为大目标提取和生成更抽象的特征,而小感受野的卷积对于小目标则更好。而右边的则是RMP模块,RMP模块由于是通过连接不同池化操作生产的特征图,由此RMP并无额外增加参数,在作者的文章中说,RMP主要用于获取上下文信息,但是我觉得这作用不打,因为医学图像的上下文信息个人认为不是十分的重要,而我在DRIVE数据集中,把RMP去掉确实影响不是十分大。


代码:
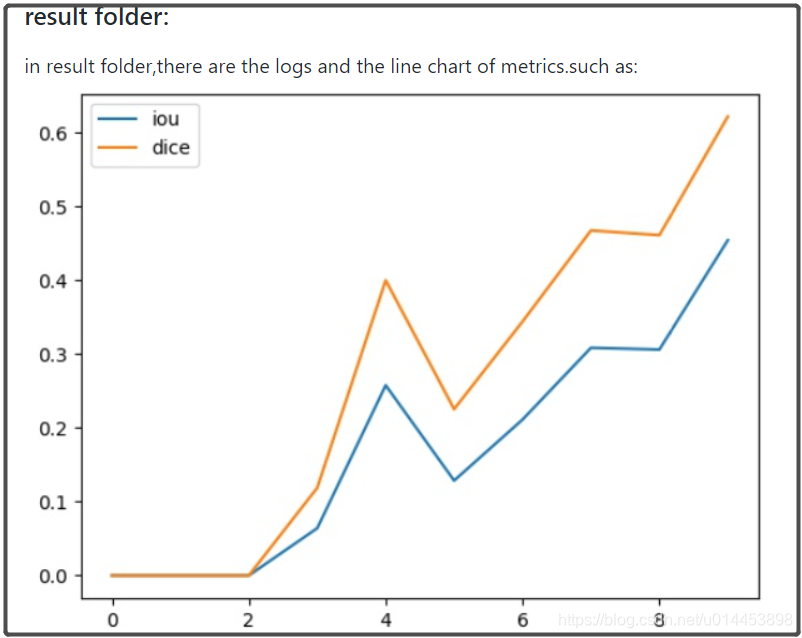
本人通过整合以上5个模型代码+FCN和SegNet,而且有7个数据集的链接,整合了一套用于基于UNET及其变体的医学图像代码。其中包括了指标可视化功能和预测结构可视化功能: