Hadoop-HA完全分布式系统搭建
为什么需要搭建HA版本
在hadoop1.x的架构中,是存在单点故障的,因为namenode节点只有一个,而namenode又是存储元数据的主节点,所以只要namenode宕机,不管有多少台datanode,将无法进行正常工作,除非namenode再次正常运行
1.x的架构如下:

2.xHA的架构如下;
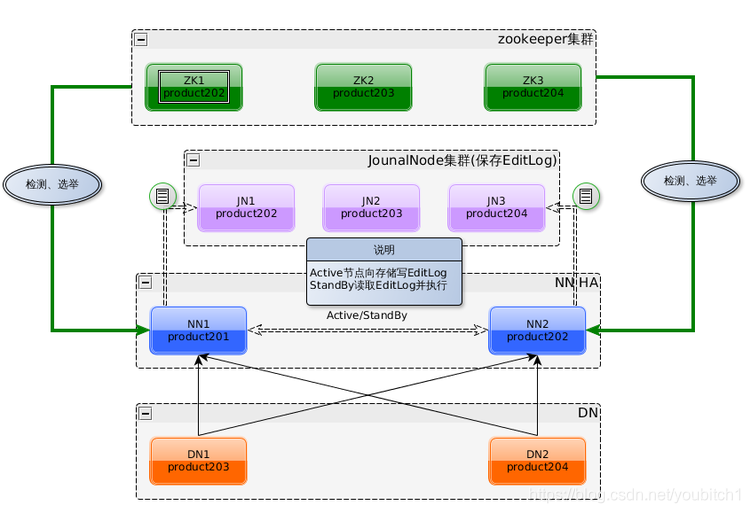
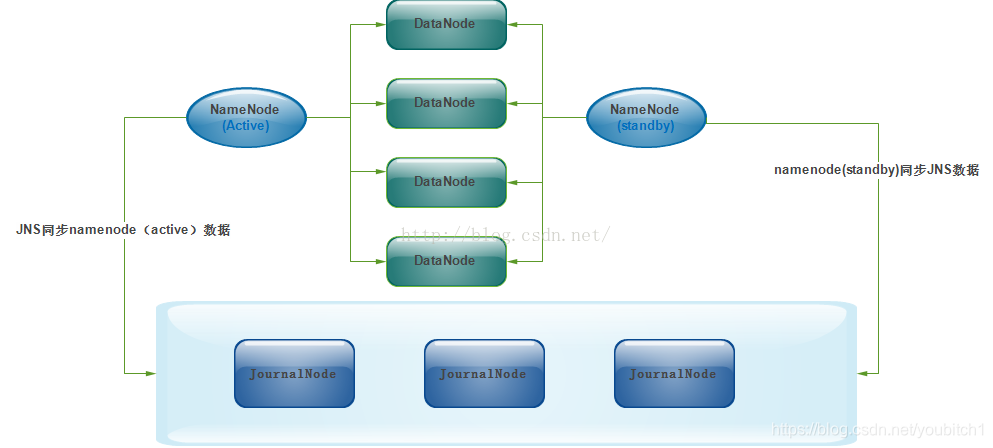
2.xHA的主备数据同步如下:
部署文档:
准备至少三台服务器
| 主机 | 作用 | 工具| 信息|
| — | — | — |
| centos7 | NameNode | 待补充 | hadoop p:seclover |
| centos7 | standby | 待补充 |
| centos7 | datanode | 待补充 |
修改主机名称
vi /etc/hostname
假如此时我有三台服务器,那么三台的主机名称分别为:
master,standby,slave
加入我此时有四台服务器,两台namenode,两台datanode
master,standby,slave1,slave2
更多的以此类推…
修改完后重启服务器
修改hosts文件
192.168.160.1 master #ip地址+主机名称
192.168.160.2 slave
192.168.160.3 standby
关闭所有的防火墙
systemctl status firewalld #查看防火墙状态
systemctl stop firewalld #关闭防火墙
systemctl disable firewalld #开机禁用
修改时区
把机器的时区统一
timedatectl set-timezone Asia/Shanghai
创建用户
创建
adduser username
设置密码
passwd username
设置免密登录
切换到新建的用户
su hadoop
一直回车即可
ssh-keygen –t rsa
有多少个节点就要copy多少节点
ssh-copy-id hostname
验证
ssh slave
退出
exit
如果忽略此步骤,后续节点通信的过程需要手动输入密码
所有的服务器都同上
安装注意事项:
不同节点的安装包目录要保持一致
提前给创建的用户操作服务安装目录的权限
chown -R username:username /目录 # 赋予安装目录权限
chown -R username:username /root/ #这个目录的权限一定要给,不然后续节点通过ssh通信可能会异常
建议:
/opt/software/...存放压缩包
/opt/modules/...存放安装包
所有节点安装JDK
解压安装包到 /opt/modules
在/etc/profile/文件追加
export JAVA_HOME="jdk安装路径"
export PATH=$JAVA_HOME/bin:$PATH
source /etc/profile #生效配置文件
java -version #验证配置是否生效
所有节点安装zookeeper
解压安装包到 /opt/modules
修改zookeeper配置文件
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改data 目录:
dataDir=/opt/modules/zookeeper-3.4.14/data
dataLogDir=/opt/modules/zookeeper-3.4.14/datalog
末尾追加server配置信息
server.1=master:2888:3888
server.2=standby:2888:3888
server.3=slave:2888:3888
ps:
2181表示客户端端口号
2888表示ZK节点内部通信端口号
3888表示ZK内部选举端口号
手动创建dataDir和dataLogDir文件夹
并在dataDir下创建myid文件,在master输入1
把zookeeper复制到其他的所有节点服务器
scp -r zk安装目录 hostname:目标目录
修改myid文件,standby的话就输入2
echo 1 >/data/myid
slave输入3
以此类推…
至此把所有节点启动测试即可
zkServer.sh start
zkServer.sh status
jps
如果正常运行则如下:一个leader节点,两个follower节点
Mode: follower
Mode: leader
Mode: follower
所有节点安装配置hadoop
解压安装包到 /opt/modules
修改以下三个文件中的jdk目录
vi hadoop-env.sh
vi mapred-env.sh
vi yarn-env.sh
export JAVA_HOME=jdk安装目录
修改core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///opt/modules/hadoop-2.5.0/data/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>slave:2181</value>
</property>
修改 hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>standby:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>standby:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;standby:8485;slave:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/modules/hadoop-2.6.5/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/modules/hadoop-2.6.5/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/modules/hadoop-2.6.5/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改 yarn-site.xml
<configuration>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave</value>
</property>
</configuration>
修改slaves
master
standby
slave
把hadoop复制到其他所有环境
scp -r [hadoop安装目录] [hostname]:[目标目录]
注意:
在hadoop目录下手动
创建journal目录
创建hdfs/name和hdfs/data目录
启动环境:
启动zookeeper [如果之前启动过此步骤请忽略]
启动journalnode(主备数据数据异步线程)集群
1.在master节点启动
hadoop/sbin/hadoop-daemons.sh start journalnode
2.在所有节点验证:
jps
JournalNode #如果有此进程则代表成功
3.如果有某个节点未发现该进程,请在当前节点hadoop/sbin
目录下重新执行该命令
格式化zkfc,在zookeeper中生成ha节点
1.在master节点执行:[切勿copy,请手动输入以下命令]
hadoop/bin/hdfs zkfc –formatZK
zkfc是什么? ZooKeeperFailoverController
它是什么?是Hadoop中通过ZK实现FC功能的一个实用工具
主要作用:作为一个ZK集群的客户端,用来监控NN的状态信息
谁会用它?每个运行NN的节点必须要运行一个zkfc
格式化hdfs
1.在master节点执行:[切勿copy,请手动输入以下命令]
hadoop namenode –format
启动namenode
1.在master节点启动namenode,启动active状态
hadoop/sbin/hadoop-daemon.sh start namenode
启动备用节点standby
1.在standby节点执行
同步master数据
hadoop/bin/hdfs namenode -bootstrapStandby
2.启动备份节点
hadoop-daemon.sh start namenode
启动datanode
1.在master节点执行
hadoop/sbin/hadoop-daemons.sh start datanode
2.jps进行验证,如果包含NameNode进程则代表成功
启动yarn
1.在slave节点执行
hadoop/sbin/start-yarn.sh
启动zkfc
1.在master节点执行
hadoop/sbin/hadoop-daemons.sh start zkfc
以上如果全部启动后,请最后进行一次检验
master节点执行 jps,正常返回如下:
3914 DFSZKFailoverController
3557 DataNode
4081 NameNode
2552 QuorumPeerMain
3357 JournalNode
3669 NodeManager
5716 Jps
standby节点执行 jps,正常返回如下:
3719 NameNode
3129 DataNode
6543 Jps
2460 QuorumPeerMain
3451 DFSZKFailoverController
3241 NodeManager
3025 JournalNode
slave节点执行jps,正常返回如下
19346 QuorumPeerMain
24324 JournalNode
26789 Jps
24086 DataNode
24632 NodeManager
24524 ResourceManager
验证
打开chrome浏览器
输入:master:50070
输入:standby:50070
查看两个节点的状态

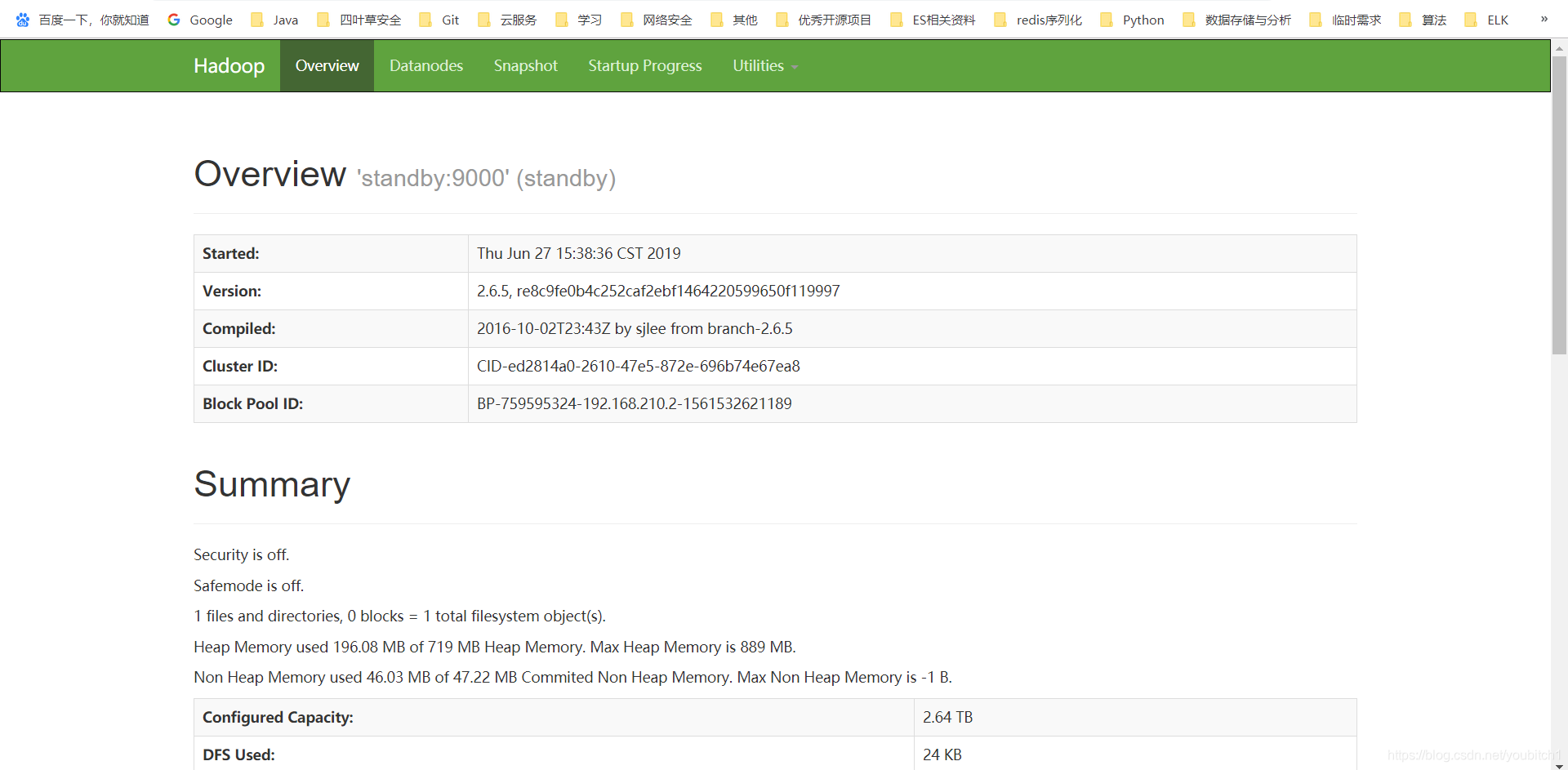
打开ssh,手动停止master节点的namenode,模拟宕机
hadoop-daemon.sh stop namenode
再次打开界面后,master页面无法访问,standby节点变为active状态,代表ha搭建成功
再次手动启动master节点namenode后,页面可以访问,但仍是standby状态,
直到standby节点挂掉后,才会切换为active状态
