课程:http://www.auto-mooc.com/mooc/detail?mooc_id=F51511B0209FB73D81EAC260B63B2A21
课程笔记
资料库:待更新
11.4 CNN结构特征
CNN的架构主要包括卷积层、池化层(汇聚层)和全连接层,它需要较少的参数就可以从图像中识别出图形特征。


RGB图像输入是3层的二维。前向传播包括两个步骤。第一步是计算中间值 Z:首先将前一层的输入数据与张量 W(包含滤波器)进行卷积,然后将运算后的结果加上偏差 b 。第二步是将中间值 Z 输入到非线性激活函数中(使用g表示该激活函数)。
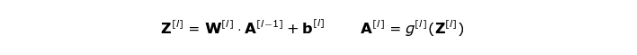


多个卷积核单独计算:


卷积层的反向传播(Convolutional Layer Backpropagation)
不需要为反向传播而烦恼——因为深度学习框架已经为做好了,但是我觉得有必要弄明白它背后发生的事情。就像在密集连接的神经网络中一样,我们的目标是计算导数,然后在梯度下降的过程中,用这些导数去更新我们的参数值。(2月11的文章已经详细提到了反向传播,用到链式法则)


Pooling层在CNN的结构中起到降低维度;Dropout按照一定的概率丢弃神经元,以防止过拟合。本单元通过实例的代码来讲解。



keep=1:

keep=0.5

keep=0.2

CNN结构:输入——>几个【几个(卷积+RELU)——>池化—>丢弃】——>几个【全连接——>RELU——>丢弃】——>全连接暑促


多层小卷积核 比 单层大卷积核的优点:1、参数变少 ;2、多层可以引入非线性。
示例:图像识别数字
首先调用数据,
mnist = input_data.read_data_sets("./dataset/", one_hot=True)
#None不定,根据读取的数据填充;图像是28x28,所以是784;最后分类是0~9个数字,所以是10.
x = tf.placeholder(tf.float32, [None, 784])# 输入的图像
y = tf.placeholder(tf.float32, [None, 10])#图像的数字0-9
进行reshape,调整图片
#参数为-1,根据其他参数的维度自动计算,batch size输入图片数量,-1代表自动;28x28表示图片大小;1表示灰度,3表示RGB;
image_input = tf.reshape(x, [-1,28,28,1])
卷积核,strides=[1,1,1,1],第一个是步长(是否跳过一些图像不处理),第二个第三个是宽度与高度上有没有要跳过 ;第四个是跳过一些通道不处理。
#卷积层;共有12个卷积核;每个卷积核大小为5*5;灰度图,所以通道数为1;卷积核初始值随机
filters = 12
filter_variable = tf.Variable(tf.truncated_normal([5,5,1,filters],stddev=0.1))
conv = tf.nn.conv2d(image_input, filter_variable,strides=[1,1,1,1], padding='SAME') #输出为28*28*12
relu =tf.nn.relu(conv)# 引入RELU非线性
池化
#池化层,downsampling为14*14*12
pool =tf.nn.max_pool(relu, ksize=[1,2,2,1],strides=[1,2,2,1], padding='SAME')
三维数据降为一维
#池化层结果输出给全连接层,全连接层不接受三维数据,so需要将三维数据降为一维
pool_flatten = tf.reshape(pool, [-1,14*14*filters])
flatten = 14*14*filters
全连接
#全连接层大小
fc = 1000
#全连接层
#全连接,参数为两层的节点数的乘积
w = tf.Variable(tf.truncated_normal([flatten, fc]))
#偏置,大小为全连接层的大小
b = tf.Variable(tf.zeros([fc]))
hidden2 = tf.nn.relu(tf.matmul(pool_flatten, w) + b)
采用softmax()输出
#输出层大小为10;全连接层与输出层
w1 = tf.Variable(tf.zeros([fc, 10]))
b1 = tf.Variable(tf.zeros([10]))
output = tf.nn.softmax(tf.matmul(hidden2, w1) + b1)
训练与反向传播
#训练,改进参数
loss = -tf.reduce_sum(y * tf.log(output))
train_step = tf.train.AdamOptimizer(0.0005).minimize(loss)
#argmax返回最大的值的下标,如果相等,说明预测的种类是正确的
correct = tf.equal(tf.argmax(output, 1), tf.argmax(y, 1))
#预测正确的比率
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
GTSRB结构



目标检测:分类——分类&定位——目标检测——分割

如何检测目标?
答:将“一定大小的小块”放入模型进行分类并打分,选取得分最高的区域。

R-CNN:Region小块
RCNN算法分为4个步骤
- 候选区域生成: 一张图像生成1K~2K个候选区域region of interest ROI提取
- 特征提取: 对每个候选区域,使用深度卷积网络提取特征 (CNN)
- 类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类
- 位置精修: 使用回归器精细修正候选框位置

感兴趣区域生成(Region Proposal )
1.滑动窗口
2.Selective Search
3.RPN网络 (Region Proposal Network)

RCNN的主要缺点有:
检测速度慢:每一个ROI都需要在CNN网络中进行一次前向传播。
训练速度慢:RCNN需要fine-tuning一个SVM分类器,在这之后还要训练一个bounding-box的归回模型。
训练过程耗时耗内存:每一个ROI和Feature都需要在训练的过程中存在电脑的内存中,很容易就产生数百G的存储消耗。
R-CNN 需要对各个ROI进行CNN,速度慢,于是提出了Fast R-CNN
Fast R-CNN

Fast R-CNN将输入图像先进行CNN,提取特征,然后共享特征。解决了RCNN需要大量处理CNN的问题。


Faster R-CNN 解决了Fast R-CNN候选框挑选浪费资源的问题,采用了RPN网络。
Google公开的训练集


非极大值抑制
在测试过程完成到之后,获得2000×20维矩阵表示每个建议框是某个物体类别的得分情况,此时会遇到下图所示情况**,同一个车辆目标会被多个建议框包围**,这时需要非极大值抑制操作去除得分较低的候选框以减少重叠框。

交并比 IoU (intersection over union):它定义了两个bounding box的重叠度,如下图所示



参考:R-CNN论文详解:https://blog.csdn.net/WoPawn/article/details/52133338
paper链接:Rich feature hierarchies for accurate object detection and semantic segmentation
辅助参考:https://zhuanlan.zhihu.com/p/23006190
动手实验:
参考项目:https://github.com/asensioatgithub/RCNN,后续测试并记录相关信息
