数据埋点
后台数据库和日志文件一般只能够满足常规的统计分析,对于具体的产品和项目来说,一般还要根据项目的目标和分析需求进行针对性地“数据埋点”工作。
所谓埋点,就是在额外的正常功能逻辑上添加针对性的统计逻辑,即期望的时间是否发生,发生后应该记录哪些信息,比如用户在当前页面是否用鼠标滚动页面、有关的页面区域是否曝光了、当前用户操作的时间是多少、停留时长多少,这些都需要前端工程师进行针对性地埋点才能满足有关的分析需求。
数据埋点工作一般由产品经理和分析师预先确定分析需求,然后由数据开发团队对接前端开发和后端开发来完成具体的埋点工作。
随着数据驱动产品理念和数据化运营等理念的日益深入,数据埋点已经深入产品的各个方面,变成产品开发中不可或缺的一环。数据埋点的技术也在飞速发展,也出现了一批专业的数据分析服务提供商(如国外的Mixpanle和国内的神策分析等),尽管这些公司提供了专门的SDK可以通用和简化数据埋点工作,但是很多时候再具体的产品和项目实践中,还是必须进行专门的前端埋点和后端埋点才可以满足数据分析和使用需求。
大白话埋点搜集数据架构
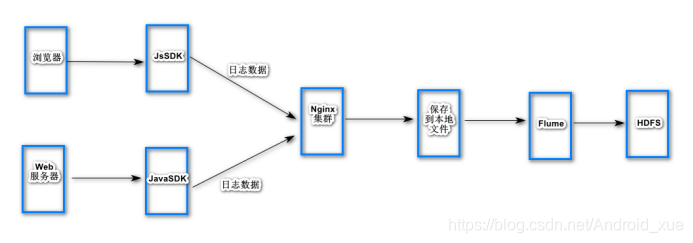
大数据工程师应该从哪里收集用户的访问数据呢?一般可以从两个地方可以取,一个是客户端,一个是服务端。
如果从服务器取数据,比如服务器每天在晚上8点到9点之间用户访问量非常多,而如果我们也从服务器获取这些数据,那么会造成服务器端压力更加的大了。
所以很多时候可以从客户端获取数据,客户端每一次访问url都会产生数据,每一次访问顺便就把这些数据发送给大数据服务器。那么这个怎么做到的呢?用户每次访问一个url,就会给他返回一堆html数据,而html中的js代码就可以帮我们实现发送数据的需求。所以我们只需写一段收集数据的js嵌套的html页面中即可。而这个js代码就称为js锚点程序也叫做js SDK。
这些数据最终肯定都会保存到HDFS分布式文件系统中,但js返回的数据也不可能直接就存到HDFS,因为jsSDK就不能写HDFS的客户端代码。况且,比如淘宝,并发量是非常之大的,在同一时间点会产生巨大的数据,所以我们需要一个可以接收高并发数据的服务器,这个时候,nginx就派上用场了,所以jsSDK把数据发送给nginx集群。nginx集群的数据存入到本地文件中。这个时候就引来一个问题,如何把本地数据搞到HDFS分布式文件系统上呢?,flume就可以做这样的事情(当然还有很多其他方法),Flume是一个分布式的海量日志采集和传输框架,nginx是个集群,数据分布在不同的节点,Flume可以实时的从网络协议、消息系统、文件系统采集日志,并传输到HDFS上。
当然不可能所有的日志数据都是通过jsSDK在客户端收集,比如支付日志,如果在客户端收集,就不会很安全了。所以必须要在web服务端收集了。就需要用到javaSDK了。javaSDK同样把数据发送给nginx集群。
Nginx集群搭建模式
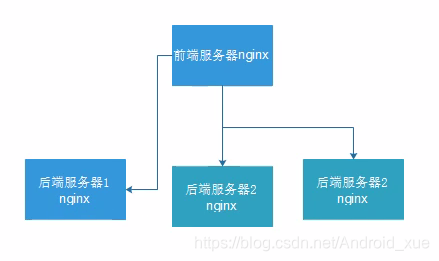
即一台前端nginx服务器接收日志数据,随机发送给三台后端nginx服务器,默认nginx每天生成一个日志文件(可以手动修改为每小时生成一个,具体根据业务需求)
