项目背景:在之前的文章中,咱们练习了爬取虎扑的帖子【项目链接】,练习了使用selenium测试化工具获取论文信息【项目链接】,今天,就来实践免账号密码登录,获取推荐帖子。从本文中,你将能学到如何使用cookie免登录和具体分析过程;掌握了这个方法,其他项目也很容易上手了。
Python爬虫使用cookie免登录获取推荐
1. Cookie免登录-获取基础问题以及链接
老步骤,首先咱们先在浏览器中进入知乎,并登录,进入开发者模式。
知乎

咱们将这个cookie的值copy下来,作为免登录使用。
ok,接下来可以咱们先写一段免登录代码。
import requests
from bs4 import BeautifulSoup
import json
link="https://www.zhihu.com"
session = requests.session()
headers={
'cookie':'xxxxxxxxxxxxxxxxxx',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
}
re = session.get(url=link,headers=headers)
首先headers里面有两个,一个是cookie 它的值就是咱们上面copy下来的,另外一个是user-agent,它的作用是让你的这个爬虫看起来更像一个正常的浏览器。
此时可以输出返回值看看,是正常进入的主页。
接下来进行返回数据的解析


从上面两个图咱们可以分析出来,题目所处在div.Card TopstoryItem TopstoryItem-isRecommend 下的a标签
标题链接所处在div.Card TopstoryItem TopstoryItem-isRecommend下的a标签里的href属性
所以下面代码就是负责获取这两个数据的
soup = BeautifulSoup(re.text,"lxml")
infoimage = soup.find("img",class_="Avatar AppHeader-profileAvatar")
title = soup.find("div",class_="Card TopstoryItem TopstoryItem-isRecommend").find('a').text
titlelink = soup.find("div",class_="Card TopstoryItem TopstoryItem-isRecommend").find('a')['href']

这个title没有任何问题,但是后面的链接不是咱们想要的,因为无法直接点击就能在浏览器中打开。
咱们看一下完整的链接是什么样子
https://www.zhihu.com/question/30173526/answer/517853719
哦,这样的话只是少了前面这几个字符,咱们做字符连接操作就可以很容易的解决了。
headstring=“https://www.zhihu.com”
titlelink = headestring+titlelink

这样不就ok 了嘛。
没错,咱们第一步ok了。平常刷知乎的人都知道,他的问题不是像虎扑帖子那样有个页数,咱们通过地址栏修改部分参数就可以到达不同的页数,知乎是当你侧栏向下拖动到当前最后一个问题时,再向下拖动,就会自动加载几个问题。好,我们通过开发者模式来分析一下,侧栏向下拖动时,发生了什么。
2. 分析加载更多时发生了什么

首先咱们先点击红点右边的清除按钮清除所有请求过的内容,然后将ALL 切换成xhr。xhr类型即通过XMLHttpRequest方法发送的请求。
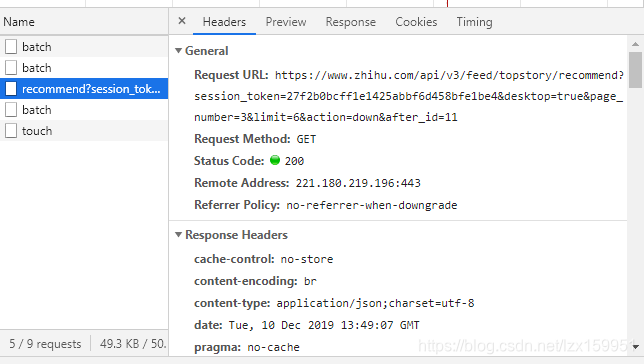
这是我侧栏向下滑到底后,再向下滑加载出来的。通过查看它们response返回结果,图中蓝色所返回的就是新加载的数据。

看样子是加载了六个。好了,咱们再看看这个请求连接的参数都是什么意思。【https://www.zhihu.com/api/v3/feed/topstory/recommend?session_token=27f2b0bcff1exxxxx&desktop=true&page_number=3&limit=6&action=down&after_id=11】
这里token的值部分用了xxx代替。

session_token:这个值是固定的,就好比你身份证号一样,记下来,以后都可以用的上。
desktop:这个值我也不知道有什么用,只见过它为true,没见过为false.
page_number:这个中文翻译就是页码的意思,虽然在底部没有明确的页码,但是每次向下请求时,加载出来的都算是一页。这里为3是因为这个值的初始值是2,向下刷新一次就成3了。
limit:这个参数是加载数据的数量,图片中它的值为6,说明这次加载了六条数据。
action:行为,向下请求更多,默认为down就行了。
after_id:这个值意思是请求一次后,请求的第一条数据的id是多少,也就是请求的第一个数据是总的第几个数据。因为首页默认加载是10条数据,所以向下一次请求后,第一条数据的id就是11.
ok了,这个咱们也分析完了,接下来就使用返回的数据,提取出我们需要的信息。
咱们需要问题的题目以及对应的回答的地址,地址格式如下:
https://www.zhihu.com/question/22378218/answer/767231136
因为数据太多,我就直接挑我们需要的几个数据截图给大家

上图数据是在data 下的target下的question
从解析json的角度代码是
text = jsons['data'][0]['target']['question']['title']
url1 = jsons['data'][0]['target']['question']['url']
好了,题目有了,部分url也有了,但是这个url跟咱们目标地址不太一样,只有question/xxxxx 咱们还缺少answer/xxxx。没关系,这些数据肯定都有,咱们再找找。

果然,在data下target下我们发现一个url,这个地址后面就包含着咱们需要的数据。
获取这个url的代码是:
url2 = jsons['data'][0]['target']['url']
好了,数据都找到了,剩下的就是拼拼凑凑了。这里还需要介绍两个咱们需要用到了方法。
str.find(str, beg=0, end=len(string))
str – 指定检索的字符串
beg – 开始索引,默认为0。
end – 结束索引,默认为字符串的长度。
str.replace(old, new, max)
old – 将被替换的子字符串。
new – 新字符串,用于替换old子字符串。
max – 可选字符串, 替换不超过 max 次
好了,看看咱们进行处理的代码:
# text = jsons['data'][0]['target']['question']['title']
# url1 = jsons['data'][0]['target']['question']['url']
# url2 = jsons['data'][0]['target']['url']
# url1 = url1[url1.find("/questions"):]
# url2 = url2[url2.find("/answers"):]
# url = "https://www.zhihu.com"+url1+url2
# url = url.replace("questions","question").replace("answers","answer")
对了,这里还有一个就是截取字符串的小tip,举个例子
str = "123456"
str1 = str[3:]
printf(str1)
输出为:456
也就是从左边0开始数,数到3,也就是上面的数字4,:代表之后所有,获取4以及后面所有的字符。
这只是获取到了一条数据,那我想批量获取怎么办呢,咱们可以将它写入到for循环中,将after_id和page_number参数化。
for i in range(2,5):
num=i
num2=11+(i-2)*6
link2 = "https://www.zhihu.com/api/v3/feed/topstory/recommend?session_token=70f706886fdfd5be1685cca0686e0e2f&desktop=true&page_number="+str(num)+"&limit=6&action=down&after_id="+str(num2)
re = session.get(url=link2,headers=headers)
jsons = json.loads(re.text)
for j in range(len(jsons['data'])):
try:
text = jsons['data'][j]['target']['question']['title']
except:
continue
url1 = jsons['data'][j]['target']['question']['url']
url2 = jsons['data'][j]['target']['url']
url1 = url1[url1.find("/questions"):]
url2 = url2[url2.find("/answers"):]
url = "https://www.zhihu.com"+url1+url2
url = url.replace("questions","question").replace("answers","answer")
print(text,url,end="\n")
这里我加入的一个try-except ,原因是我在测试的时候发现,有时候会出报找不到question的错误,但是我看了返回值确实存在。由于没有找到原因,我就使用这个异常捕捉,出现异常时,就使用continue 跳到下一个新的循环。
这个项目后面可以完善的地方还有很多,我在这里给几个思路:
1、使用多线程提高速度
2、尝试将获取的数据存储起来,excel或者Mongodb数据库
好了,项目到此结束了,有什么问题欢迎一起讨论。下面放出完整的项目代码:
import requests
from bs4 import BeautifulSoup
import json
import time
link="https://www.zhihu.com"
session = requests.session()
headers={
'cookie':'xxxx',
}
re = session.get(url=link,headers=headers)
soup = BeautifulSoup(re.text,"lxml")
infoimage = soup.find("img",class_="Avatar AppHeader-profileAvatar")
title = soup.find("div",class_="Card TopstoryItem TopstoryItem-isRecommend").find('a').text
titlelink = soup.find("div",class_="Card TopstoryItem TopstoryItem-isRecommend").find('a')['href']
print(title,"https://www.zhihu.com"+titlelink)
#上面代码读者可以自行完善,我只是获取了其中一条数据。
for i in range(2,5):
num=i
num2=11+(i-2)*6
link2 = "https://www.zhihu.com/api/v3/feed/topstory/recommend?session_token=xxxxxxxf&desktop=true&page_number="+str(num)+"&limit=6&action=down&after_id="+str(num2)
re = session.get(url=link2,headers=headers)
jsons = json.loads(re.text)
for j in range(len(jsons['data'])):
try:
text = jsons['data'][j]['target']['question']['title']
except:
continue
url1 = jsons['data'][j]['target']['question']['url']
url2 = jsons['data'][j]['target']['url']
url1 = url1[url1.find("/questions"):]
url2 = url2[url2.find("/answers"):]
url = "https://www.zhihu.com"+url1+url2
url = url.replace("questions","question").replace("answers","answer")
print(text,url,end="\n")
