垃圾回收算法
前边简单的说明了一下如何判定对象是不是需要回收,该篇讨论一下常用的垃圾回收算法。但是只是讨论原理,并没有具体的代码实现,也就是说只是停留在理论层面,原因大概是首先这些算法其实并不难实现,其次这些算法只是一些基本的算法思想,每个虚拟机会在这些算法的思想上拓展自己的垃圾回收算法
标记清除
该算法其实分为两个过程,标记垃圾,然后清楚垃圾。
标记:标记过程其实就是前边说的两种标记算法。简单的理解一下:
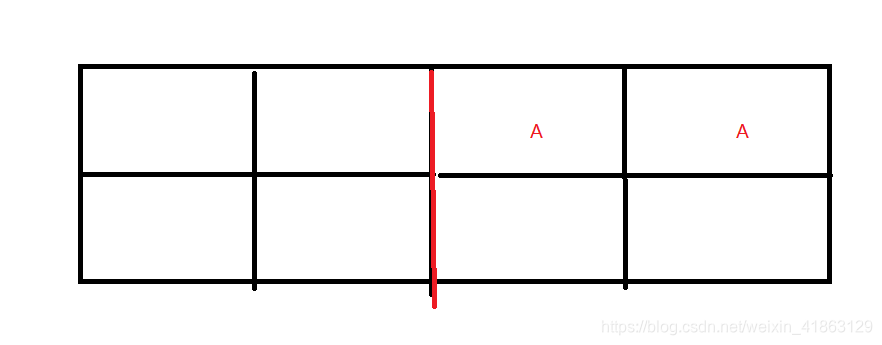
首先存活的对象被标记为A,即将被回收的对象被标记为B,其他区域是没有被使用的区域。
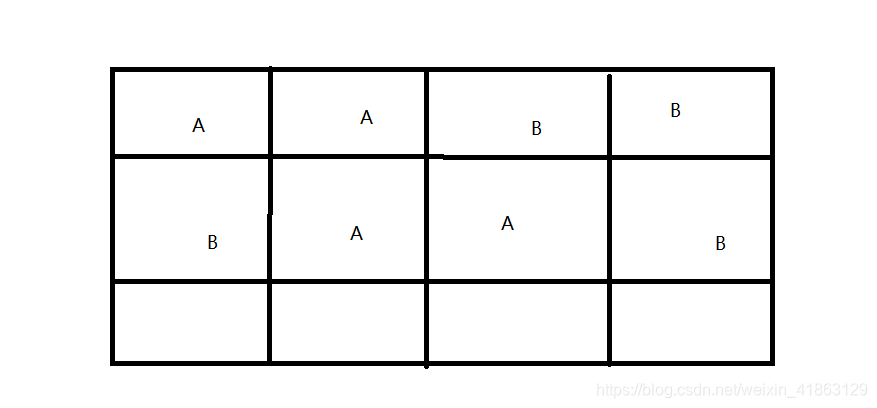
标记完成后,统一回收。
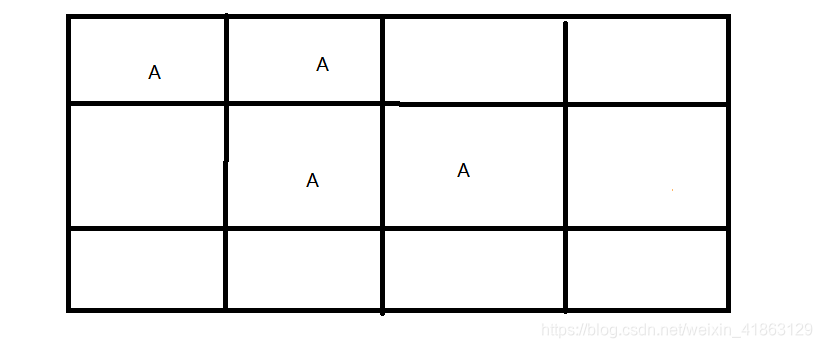 内存就会成为这个样子。
内存就会成为这个样子。
缺点:其实这个方法虽然简单好实现,但是存在很大的缺点,内存碎片化严重。内存的内碎片指的是这片内存还没有被分配出去,但是因为比较小,或者不合适,很难被利用起来。操作系统中在说的内存分配问题是其实有说到这个问题,有一种技术就是内存紧缩技术,因为所有的内存都是被一个链表串起来了,所以可以把空闲的内存被搬运到一起去,这样就实现了内存的紧缩。但是这个搬运的过程其实是很耗时间的,所以不是一个很合理的方案。
标记复制
其实标记复制算法,借鉴了内存紧缩技术。
基本实现:标记复制算法是把内存分为两个部分。
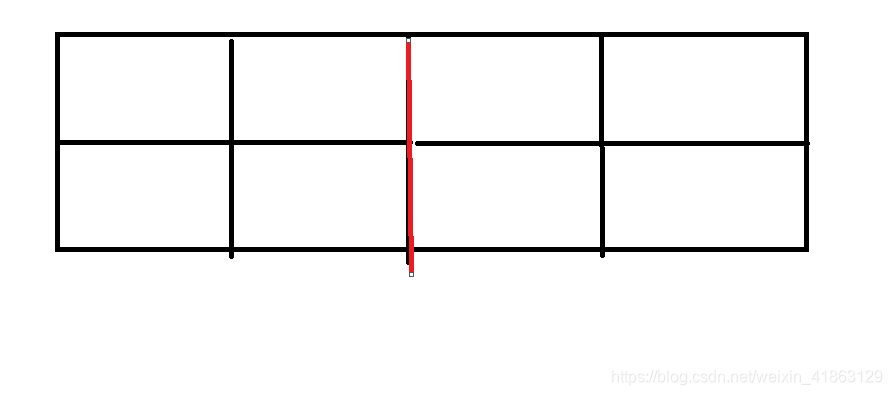 红线的左边和右边是两块独立的区域。对象在某一固定的时刻只会出现在一侧
红线的左边和右边是两块独立的区域。对象在某一固定的时刻只会出现在一侧
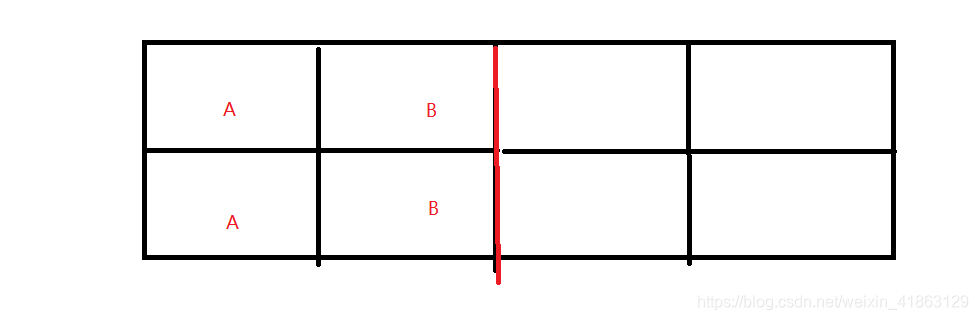 比如对象全在左侧,然后要回收B,首先把A给复制到右边,再把左边的内存全部回收。
比如对象全在左侧,然后要回收B,首先把A给复制到右边,再把左边的内存全部回收。
这样几乎解决了因为回收内存带了的内碎片问题。但是,缺点也是十分明显的,因为对象的复制不是一件容易的事情,这个很耗时间。
标记整理算法
这个就是我们说的内存紧缩技术,把垃圾回收了以后重新整理对象,把他们搬运到内存到一段内存连续的空间里面去,这样就解决了因为垃圾回收带了的内碎片问题。
分代收集
这个算法的提出是基于虚拟机把内存分为新生代很老年代,统计学表明新生代的对象大多数都是生命期很短,这时候对新生代采用标记复制,因为需要复制的对象很少;对于老年代,对象的存活率较高,就用标记整理或者标记清除。
垃圾回收器
前边说的都是回收的算法,下面讨论一下这些算法的实现。根据这些算法以及拓展,虚拟机设计者设计了不同的垃圾回收器来回收垃圾
Serial 搜集器
这个词是序列化的缩写,也是历史最悠久的搜集器。这是一个单线程的搜集器,单线程不是说它的工作线程只有一个,指的是一旦它启动了,所有的线程都要停止,等它搜集完了再继续。所以也经常被叫做“Stop the world".
缺点:显然,如果这个搜集器工作时间很长,那么用户会感受到明显的停顿。但是还好,现在的设计已经可以把这个停顿缩减到几十毫秒到一百毫秒之间。
ParNew 搜集器
这个搜集器没有太大的创新,就是一个多线程版的Serial。在单个CPU工作的情况下,由于线程切换的开销,性能其实还没有Serial好。
Parallel Scavenge 搜集器
这是一个应用了新生代的垃圾收集器,使用标记复制算法。它的关注点不是用户停顿,而是吞吐量。具体点就是说CPU运行业务代码的比例,比如CPU运行了100分钟,垃圾回收用了1分钟,那么吞吐量就是99%。它的关注点在于最大化利用CPU的时间。
Serial Old
使用在老年代的垃圾搜集器,也是一个单线程版本的,使用标记整理算法。
CMS搜集器
CMS:并发低停顿搜集器,使用标记清楚算法,关注点在于最小化停顿。
实现比较复杂。是一个多线程搜集器
G1搜集器
这是虚拟机垃圾搜集现在为止比较先进的搜集器,额,还没仔细研究,待补。
以上就说明了,内存自动管理的内存回收。其实内存的自动管理就两个部分,内存分配和内存回收,下一篇讨论内存分配的机制。
