import urllib.request
# urlretrieve(网址,本地文件存储地址) 直接下载网页到本地
urllib.request.urlretrieve('https://baidu.com','C:/Users/Nicht_sehen/Desktop/1.html')
# urlcleanup() 清除缓存
urllib.request.urlcleanup()
# info() 得到当前页面信息
inf =urllib.request.urlopen("https://read.douban.com/provider/all")
print(inf.info())
# getcode() 输出当前状态码 200为正常状态码
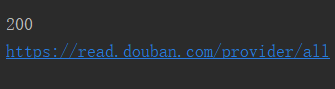
print(inf.getcode())
# geturl() 获取当前访问网页url
print(inf.geturl())
# 超时设置
ff = urllib.request.urlopen("https://read.douban.com/provider/all",timeout=1)
try:
print(ff.read())
except Exception as err:
print("异常")