1. 词嵌入
词的表示:字典,然后one-shot vector
缺点:把词与词间的关联没有体现出来,比如学到orange juice,但不能泛化出apple juice

词嵌入
用特征来表示单词:比如性别特征,Man得分-1, wonman得分1,apple则没有该明显特征,得分为0.00(趋于0)
如果选择300个特征,这样一个词就可以用一个300维的向量来表示。
根据这个,当学到orange juice后,因为apple和orange的向量值类似,就可以容易地得到apple juice

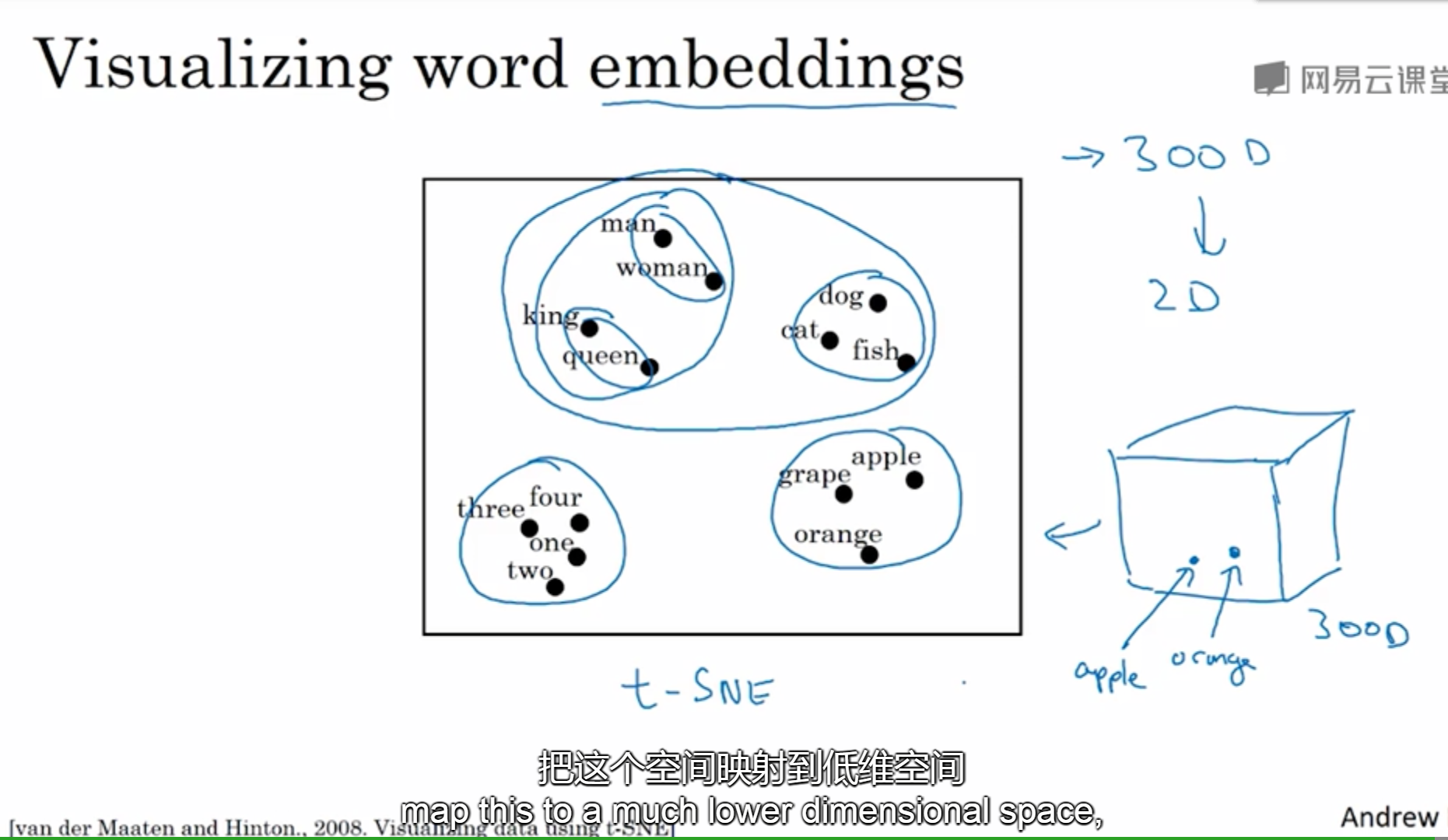
可视化词嵌入
t-SNE算法可以把300维的空间映射到二维。嵌入这个词的意义:想象一个300维的空间,每个词就像是嵌入其中的一个点
2. 使用词嵌入
迁移学习

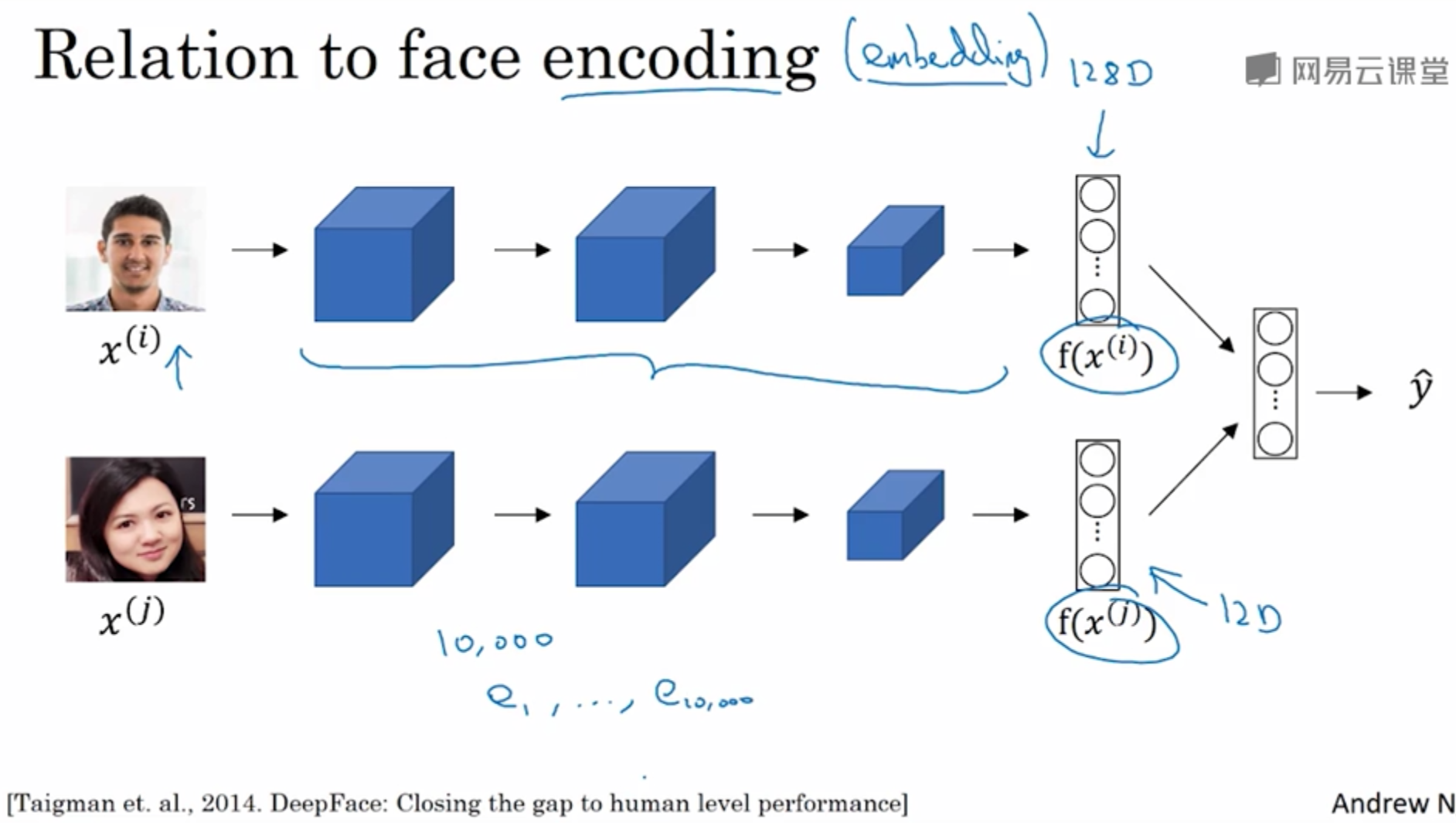
人脸识别编码与词嵌入
人脸面对的是海量数据,而词嵌入的数据是固定的
3. 词嵌入的特性
用于类比推理,比如知道man对woman,则可以推出king对queen。基本是通过比较两对向量的差值来判断

注意:用t_SNE算法对点进行可视化转换后,两个向量并不一定总相等。t-SNE是非线性的转化
找到一个单词,使得相似度最大
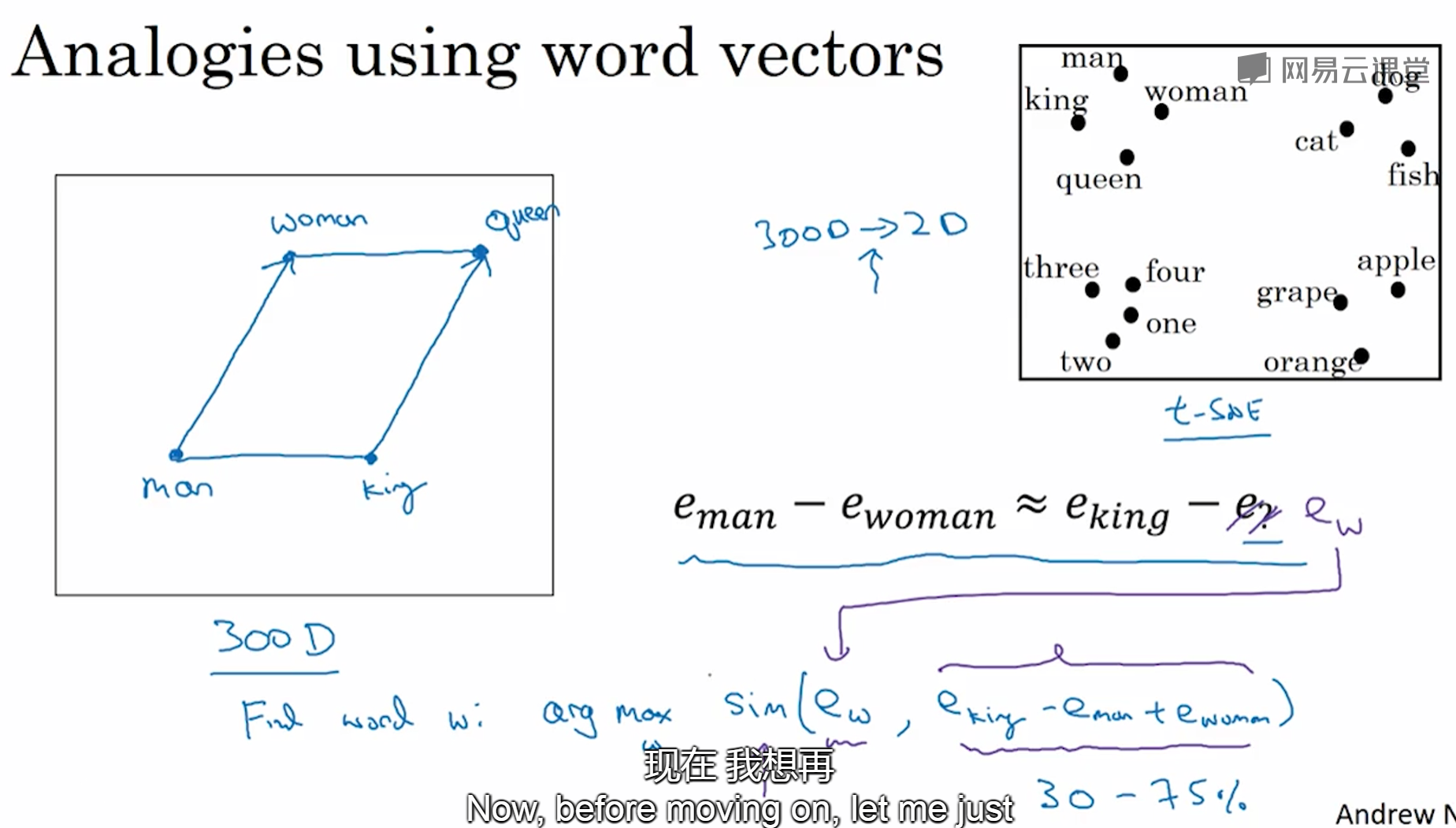
相似度函数:余弦函数
词嵌入可以学到很多种的类比关系

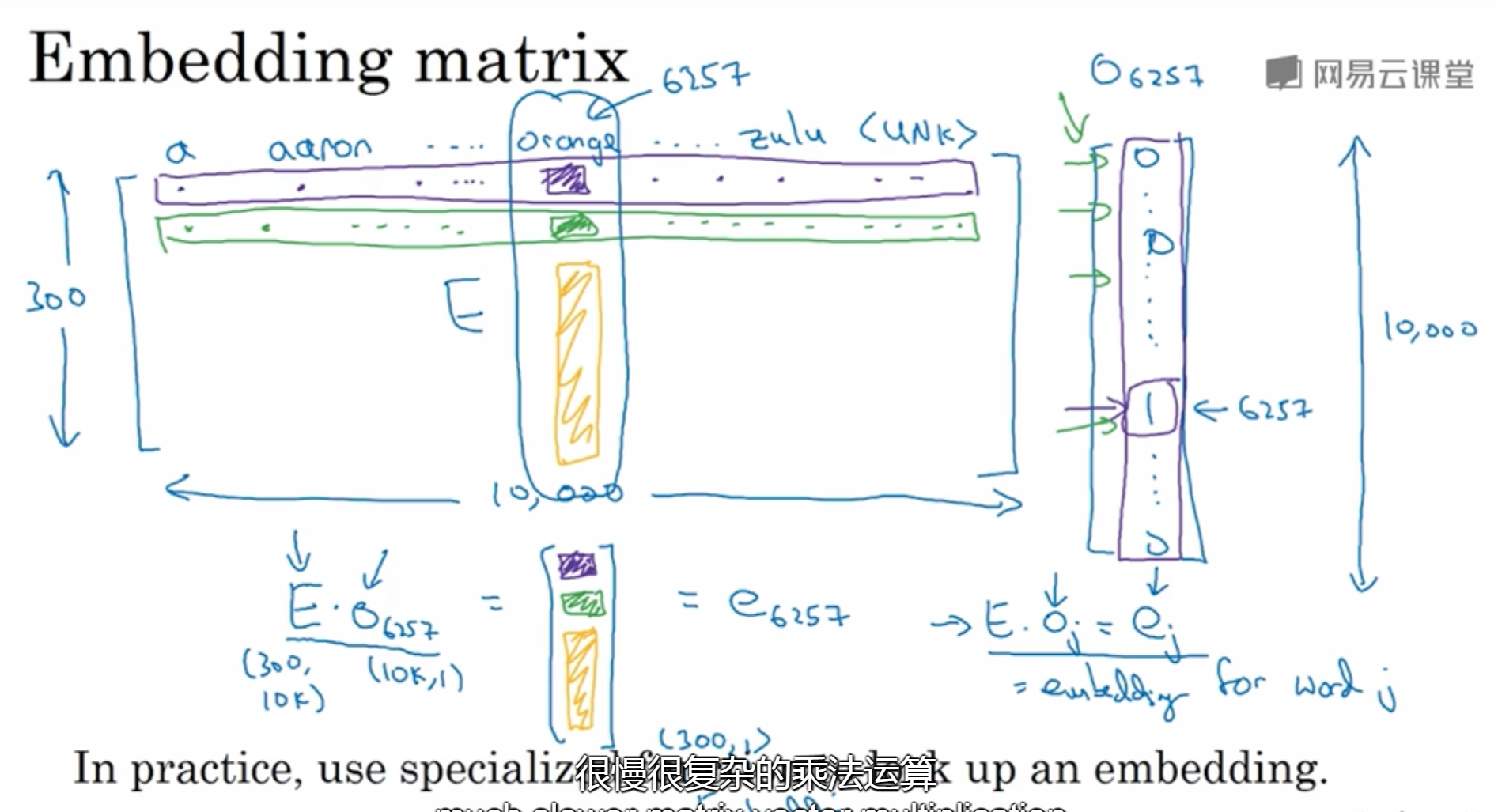
4. 嵌入矩阵
词嵌入实际是学习嵌入矩阵。把这个矩阵与单词的one-shot向量相乘,就可以得到词的特征向量,也就是对应的一列特征。因为很多值为0,计算代价大,所以实际上会直接用函数来选取一列
5. 学习词嵌入
通过解决学习问题来完成词嵌入的学习
自然语言模型:
学习这句话的最后一个词是什么:
把每个词用one-shot表示,然后乘以词嵌入矩阵E,得到各自的特征表示向量
把这些向量输入NN
再输入一个softmax层,从1000个可能的词中找出最合适的
为什么可以学习词嵌入?因为在训练集中会发现apple juice, orange juice等等,那么为了比较好地适应训练集,也就是要让apple orange的特征相似
在学习中,一般采用固定历史窗口,也就是每次就只看前4个词

可以采用其他的上下文(也就是不一定适用前4个)

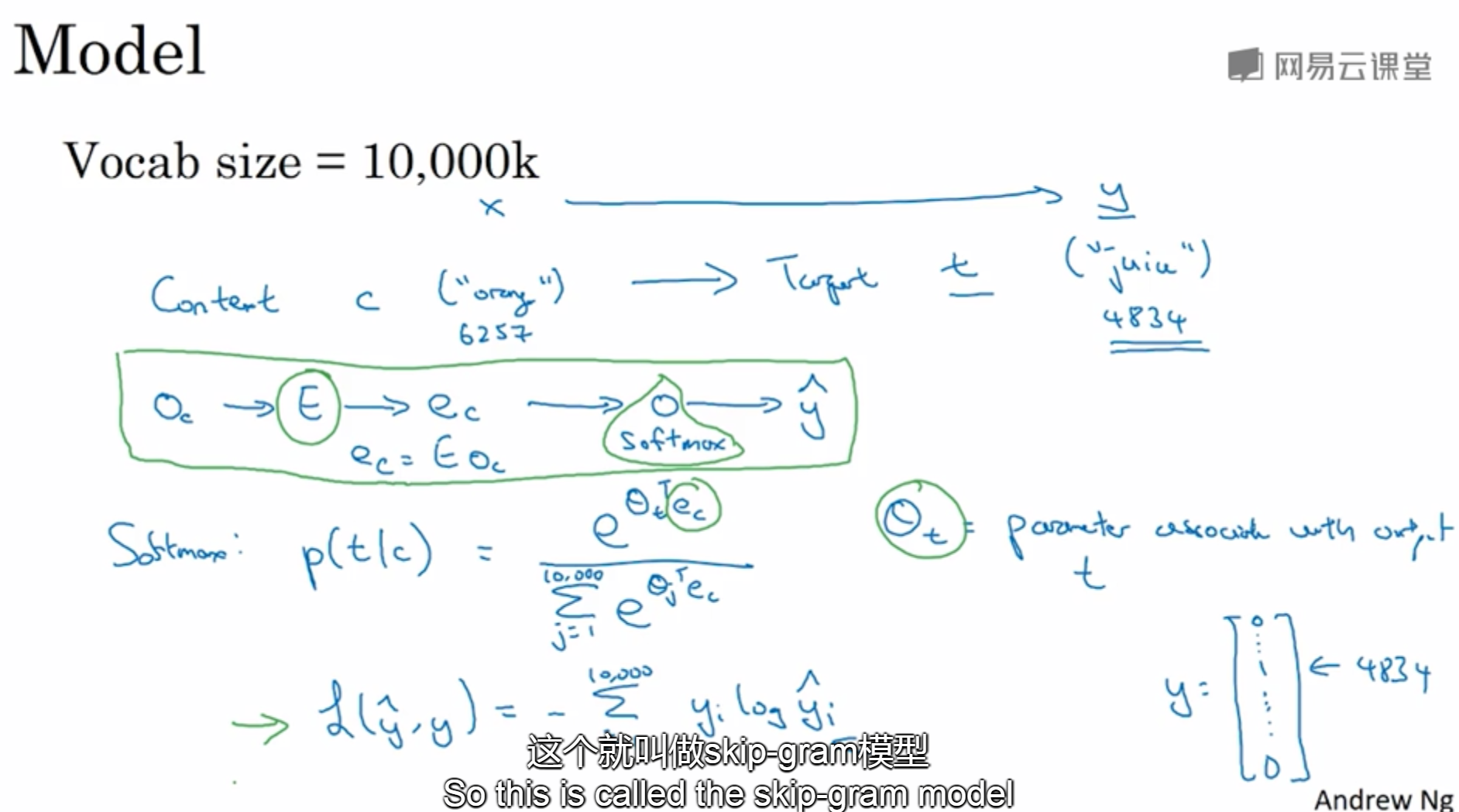
6. Word2Vec算法
学习问题:选择一个context词,然后预测在一定词距可能出现的target词

skip-gram model
学习c->t的一个映射关系,theta t是一个和输出t相关的参数
两个问题:
1.分母的计算量大:采用分级的softmax分类器,把频率高的放上面,低的放下面。不一下子计算出属于哪一类,第一个告诉属于前5000还是后5000,第二个分类器告诉属于前2500还是后2500
2. 如何选择context:如果在词表中均匀选择,那很可能对对应的target是a, the, of之类的词,因此要频繁地更新ec,而apple, juice, durian之类的词就比较少出现???

6. 负采样方法
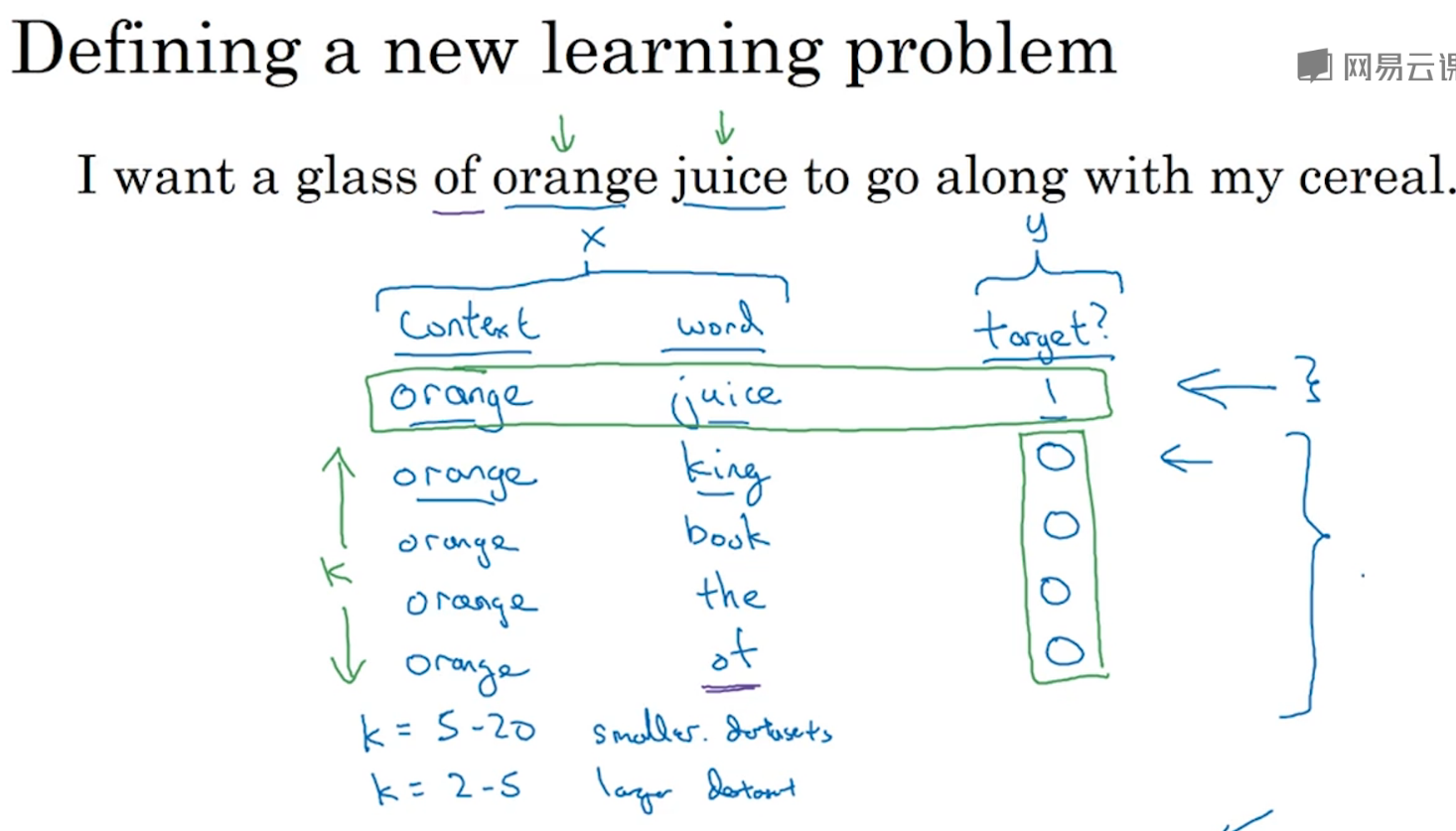
定义一个新的问题:
给定一对词,判断它们是否是context-target关系,如果是则为1(正采样,在一个文本中同时出现),否则为0(负采样)
构建训练集的方法:
一个正采样(选择一个context,然后在一定词距内再选择一个词),k个负采样(与正采样相同的context,然后从字典中随机选取k个词,并把结果target标记为0)
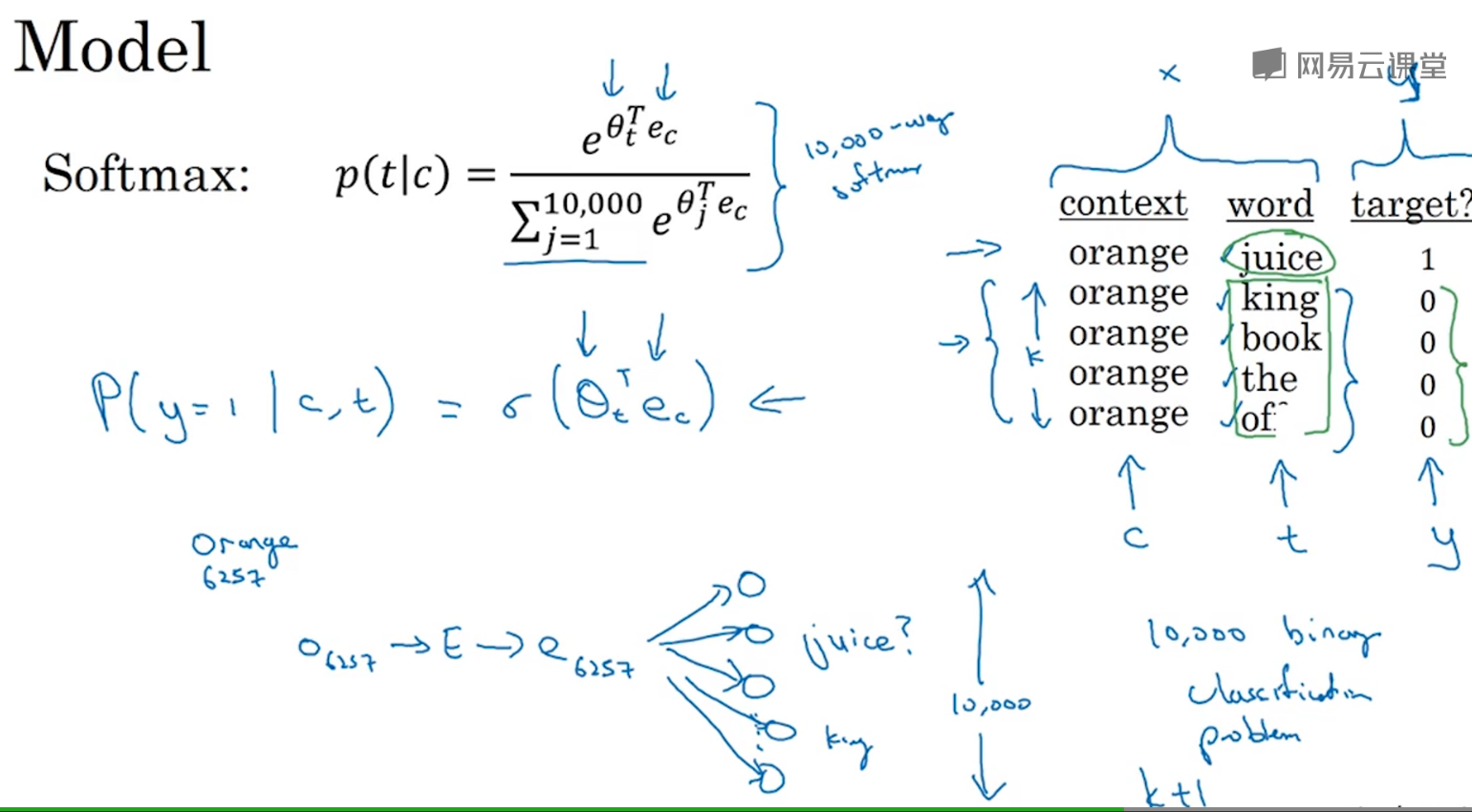
学习问题:
根据输入的x,判断输出的y
数据集越大,k越小
如果负采样中的值与正采样的一样呢,也是记为0吗?
模型
原来的word2vec算法中,softmax的计算代价很大,需要对1000个(词典大小)词进行计算,但是通过负采样,只需要判断k+1个

如何进行负采样:这个点还不是很懂,P(w)是怎么决定采样位置的?

5. GloVec算法
选择一对context-target,统计他们同在一个文本的次数

目标函数
f(xij):当xij为0时,取值为0,此外对于出现频率比较高的词this。。或低的词duration,可以让f(x)作为函数,进行调整
theta和e是对称,作用相同,所以可以求平均值

一个特征:很难根据一行的值来说明它的意义,因为可能会发生一些线性变换

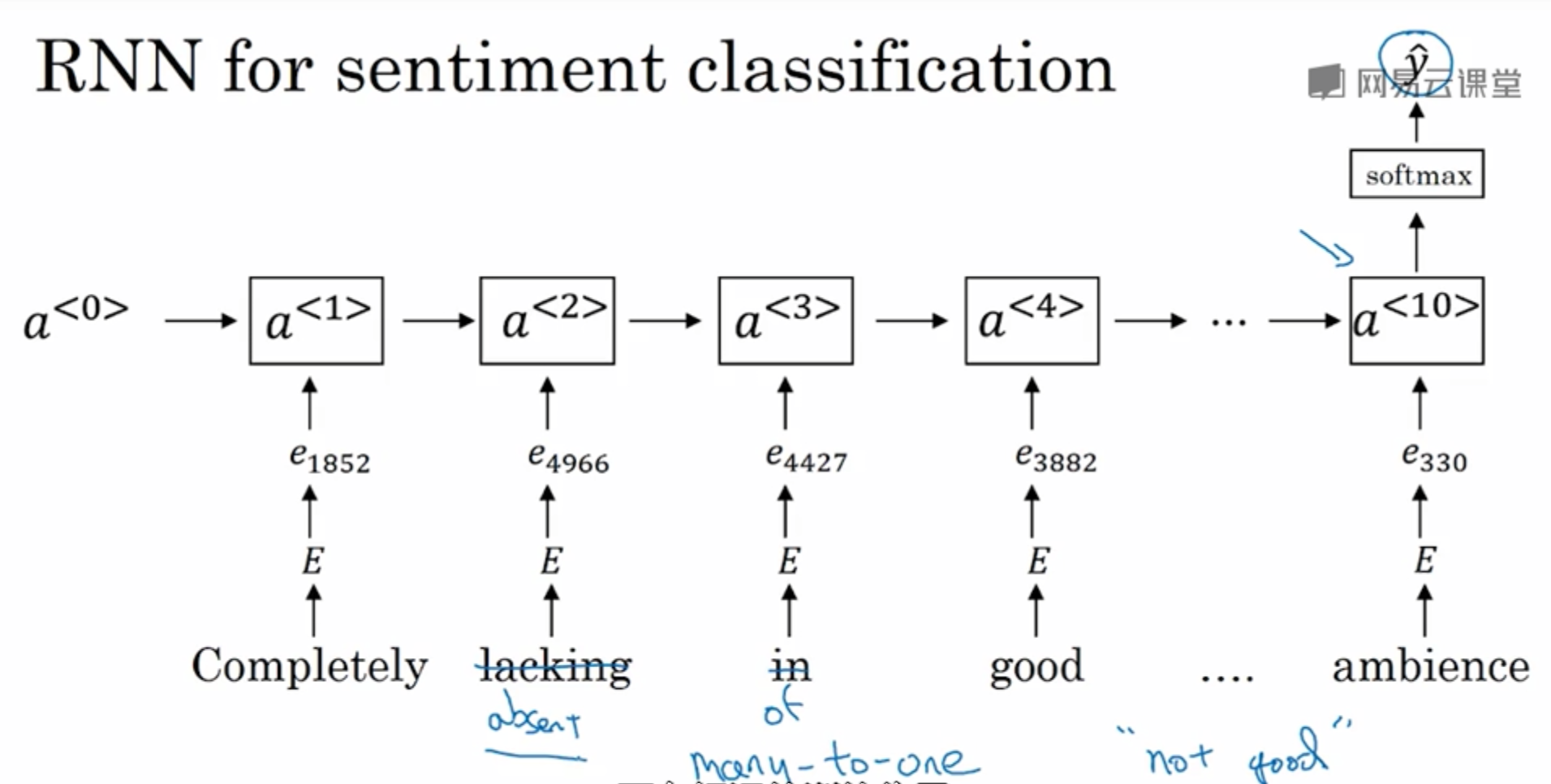
9. 情感分类
分类问题:根据一个文本进行打分

简单分类模型
缺点:没有考虑顺序,可能不好的由于很多good导致结果错误

RNN模型
考虑顺序,同时利用词嵌入可以进行泛化
10 消除偏见
深度学习开始起作用,做一些重要的社会决定,所以不应该有歧视

处理的方式:
1. 识别出有偏见的方向,将性别对立的词向量相减取平均。如图水平是歧视,垂直是没有歧视
2. neutralize中和,对于没有性别定义的词,应该消除偏差,简单的做法如图将它们水平移动到垂直轴上(doctor,babysitter)
3. equalize均衡,对于有性别区分的词,应该让它们的相似性高一些,比如把grandmother和grandfather移动到垂直轴两侧对称位置
