会议:ICASSP 2019
论文:END-TO-END STREAMING KEYWORD SPOTTING
作者:Raziel Alvarez, Hyun Jin Park, Google, Inc., United States
ABSTRACT
提出了一个关键词识别系统,除了用于特征生成的前端组件外,它完全包含在经过“端到端”训练的深度神经网络(DNN)模型中,用于预测音频流中关键词的存在。这项工作的主要贡献是,首先,一个有效的记忆神经网络拓扑,目的是更好地利用参数和相关的计算,在DNN的深度上保存以前的激活分布的记忆。第二个贡献是对DNN进行端到端的训练,生成关键字定位分数。该系统在检测质量、规模和计算量方面都明显优于以往的方法。
##一、 INTRODUCTION
随着发展,关键词查找已经成为一种生活方式,对于关键字识别系统而言, 既高质量又高效这一点很重要。
神经网络是最先进的关键词识别系统的核心,它们传统上由不同的子系统组成,例如一个典型的系统有三个主要部分组成:信号处理前端、声音编码器、单独的解码器。这些组件中,最后两个组件使用DNN以及各种各样的解码实现。它们包括传统的方法,利用HMM来面熟从DNN到“keyword”和“background”(即非关键字语音和噪声)类的声学特征[1,2,3,4,5]。该方法的更简单的衍生物执行时间积分计算,以验证声学模型的输出在目标关键字的正确序列中是高的,以便产生单个检测似然分数[6、7、8、9、10]。其他最新的系统利用了CTC训练的DNN——通常是递归神经网络(RNN)甚至依赖于波束搜索解码的序列到序列训练模型[12]。 最后一组系统最接近端到端系统,但是对于许多嵌入式应用程序而言,它们通常在计算上过于复杂。
但是,优化独立的组件会增加复杂性,并且与联合执行相比,其质量次优。由于额外的复杂性,部署也会受到影响,这使得优化资源(例如处理能力和内存消耗)变得更加困难。本文描述的系统通过将编码器和解码器组件都学习到单个深度神经网络中,共同优化以直接产生检测可能性得分,从而解决了这些问题。可以训练该系统来包含信号处理前端以及在[3,13]中,但是用等效质量的神经网络替换高度优化的快速傅立叶变换实现通常在计算上是昂贵的。但是,这是我们将来考虑探索的事情。总的来说,与[14]中描述的传统的非端到端基线系统相比,我们发现该系统在许多音频和语音条件下都可以提供最先进的质量。此外,与基线系统相比,拟议的系统将计算和大小缩减了五倍,从而大大降低了部署所需的资源。
本文的其余部分安排如下。 在第2节中,我们介绍了关键字搜寻系统的体系结构; 特别是这项工作的两个主要贡献:神经网络拓扑和端到端训练方法。 接下来,在第3节中,我们将描述实验设置,并在第4节中,我们将评估的结果与[14]的基线方法进行比较。 最后,我们在第5节中讨论了我们的发现。
END-TO-END SYSTEM
本文提出了一种新的端到端的关键词识别系统,通过将编码和解码部分都包含在一个单一的神经网络中,可以直接训练出流音频中关键词存在的估计值(即分数)。以下两部分介绍了所使用的高效记忆神经网络拓扑结构,以及训练端到端神经网络直接产生关键词识别分数的方法。
1、高效记忆神经网络拓扑


2、训练端到端神经网络的方法
我们端到端培训的目标是优化网络以产生可能的分数,并尽可能精确地做到这一点。这意味着在流式音频中关键字的最后一个it出现的地方获得高分,而不是在之前,尤其是之后(即,希望出现“尖刺”行为)。这一点这一点很重要,因为系统被绑定到一个由阈值(介于0和1之间)定义的操作点,该阈值用于在错误接受和错误拒绝之间取得平衡,平滑的似然曲线将增加触发点的可变性。此外,在关键字的真正结尾和分数达到阈值之间的任何时间,都将成为系统中的延迟(例如,“助手”将很慢地做出响应)——这是CTC培训RNN[20]的一个共同缺点,我们旨在避免。
- Label generation

- Training recipe
端到端训练使用一个简单的帧级交叉熵(CE)损失;训练方法使用异步随机梯度下降(ASGD)来生成单个神经网络,该神经网络可以馈入流输入特征并生成检测得分。
EXPERIMENTAL SETUP
为了确定该方法的有效性,我们将其与文献[14]中提出的一个已知的关键词识别系统进行了比较。本节介绍“结果”部分中使用的设置。
文献:T. Sainath and C. Parada, “Convolutional neural networks for
small-footprint keyword spotting.,” in Proceedings of Annual
Conference of the International Speech Communication Asso-
ciation (Interspeech), 2015, pp. 1478–1482.
1、 Front-end
两种设置使用相同的前端,在30ms流音频窗口中产生40维对数mel滤波器组能量,重叠时间为10ms。此外,可以使用给定的步长σ来请求序列。
2、Baseline model setup
基线系统(基线1850K)取自[14]。它由一个DNN训练来预测关键字中的子词目标。DNN的输入由一个序列组成,左C l=30帧,右C r=10帧,每个序列的步长为σ=3。该拓扑结构由一个1-D卷积层和92个滤波器(8x8形状和8x8跨距)组成,接着是3个完全连接层,每个层有512个节点和一个校正的线性单元激活。最终的softmax输出预测9个子字目标(“k”和“h”共享“Ok/Hey Google”检测标签),从2.2.1中描述的相同强制对齐过程获得。这导致基线DNN包含1.7M参数,并且每次推理执行1.8M乘累加操作(每30ms流音频)。通过首先平滑后验值,在前100帧相对于当前t的滑动窗口上平均后验值,计算出0到1之间的关键字定位得分;然后将得分定义为滑动窗口中平滑后验值的最大乘积,如最初在[7]中提出的那样。
3、End-to-end model setup
端到端系统(prefixE2E)使用图3所示的DNN拓扑,并且所有SVDF层的等级均为1。我们提供了3个不同大小的配置(中缀700K,318K和40K)的结果,每个配置代表大约数量参数的定义,以及分别对应于端到端和编码器解码器的2个训练配方变体(后缀1stage和2stage)
4、Dataset
所有实验的训练数据均包含100万个由匿名词“ Ok Google”和“ Hey Google”手工转录而成的语音,分布均匀。
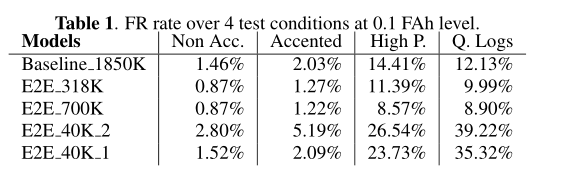
RESULTS
评估错误拒绝(FR)和错误接受(FA)权衡在几个不同的大小和计算复杂度的端到端模型。
CONCLUSION
提出了一个关键字识别系统,通过结合有效的拓扑结构和两种端到端训练,可以显著地优于以前的方法,同时大大降低了规模和计算成本。特别展示了它是如何超越[14]中的一个设置的性能的,该设置的模型要小5倍以上,甚至要接近40倍以上的模型的性能。我们的方法提供了更多的好处,除了前端和神经网络之外不需要任何东西来执行检测,因此更容易扩展到更新的关键字和/或使用新的训练数据进行微调。
