以下为牛客网精选面试题,网上资料整理解答。
招银网络科技Java面经
一面
(1)java类加载过程?
当程序要使用某个类时,如果该类还未被加载到内存中,则系统会通过加载,连接,初始化三步来实现这个类进行初始化。
- 加载
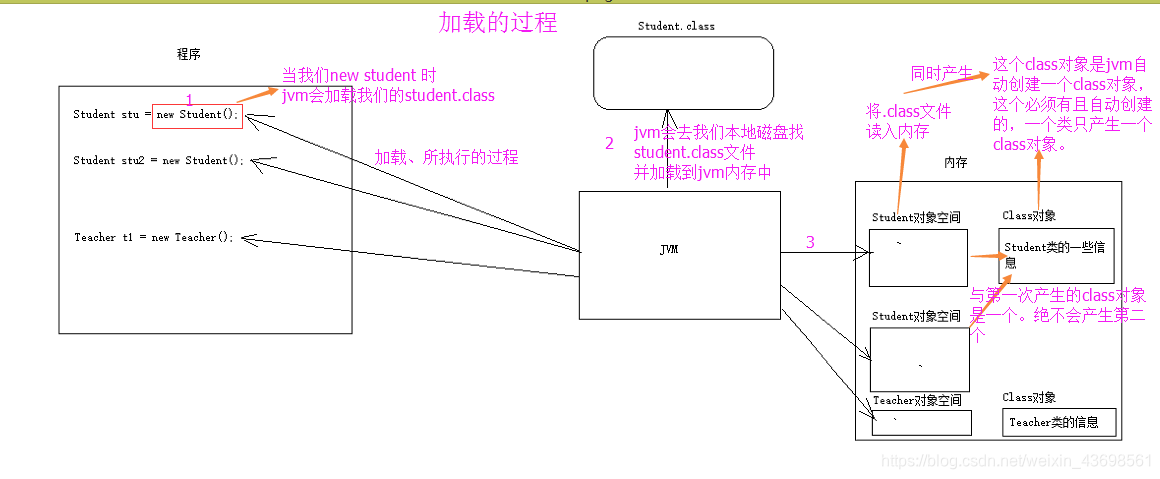
加载,是指Java虚拟机查找字节流(查找.class文件),并且根据字节流创建java.lang.Class对象的过程。这个过程,将类的.class文件中的二进制数据读入内存,放在运行时区域的方法区内。然后在堆中创建java.lang.Class对象,用来封装类在方法区的数据结构。
类加载阶段:
(1)Java虚拟机将.class文件读入内存,并为之创建一个Class对象。
(2)任何类被使用时系统都会为其创建一个且仅有一个Class对象。
(3)这个Class对象描述了这个类创建出来的对象的所有信息,比如有哪些构造方法,都有哪些成员方法,都有哪些成员变量等。
Student类加载过程图示:
- 链接
链接包括验证、准备以及解析三个阶段。
(1)验证阶段。主要的目的是确保被加载的类(.class文件的字节流)满足Java虚拟机规范,不会造成安全错误。
(2)准备阶段。负责为类的静态成员分配内存,并设置默认初始值。
(3)解析阶段。将类的二进制数据中的符号引用替换为直接引用。
说明:
符号引用。即一个字符串,但是这个字符串给出了一些能够唯一性识别一个方法,一个变量,一个类的相关信息。
直接引用。可以理解为一个内存地址,或者一个偏移量。比如类方法,类变量的直接引用是指向方法区的指针;而实例方法,实例变量的直接引用则是从实例的头指针开始算起到这个实例变量位置的偏移量。
举个例子来说,现在调用方法hello(),这个方法的地址是0xaabbccdd,那么hello就是符号引用,0xaabbccdd就是直接引用。
在解析阶段,虚拟机会把所有的类名,方法名,字段名这些符号引用替换为具体的内存地址或偏移量,也就是直接引用。 - 初始化
初始化,则是为标记为常量值的字段赋值的过程。换句话说,只对static修饰的变量或语句块进行初始化。
如果初始化一个类的时候,其父类尚未初始化,则优先初始化其父类。
如果同时包含多个静态变量和静态代码块,则按照自上而下的顺序依次执行。 - 小结
类加载过程只是一个类生命周期的一部分,在其前,有编译的过程,只有对源代码编译之后,才能获得能够被虚拟机加载的字节码文件;在其后还有具体的类使用过程,当使用完成之后,还会在方法区垃圾回收的过程中进行卸载(垃圾回收)。
(2)数据库索引怎么实现的?
1 B+树
用这个树的目的和红黑树差不多,也是为了尽量保持树的平衡,当然红黑树是二叉树,但B+树就不是二叉树了,节点下面可以有多个子节点,数据库开发商会设置子节点数的一个最大值,这个值不会太小,所以B+树一般来说比较矮胖,而红黑树就比较瘦高了。
关于B+树的插入,删除,会涉及到一些算法以保持树的平衡。ORACLE的默认索引就是这种结构的。
如果经常需要同时对两个字段进行AND查询,那么使用两个单独索引不如建立一个复合索引,因为两个单独索引通常数据库只能使用其中一个,而使用复合索引因为索引本身就对应到两个字段上的,效率会有很大提高。
2 散列索引
通过散列函数来定位的一种索引,不过很少有单独使用散列索引的,反而是散列文件组织用的比较多。
散列文件组织就是根据一个键通过散列计算把对应的记录都放到同一个槽中,这样的话相同的键值对应的记录就一定是放在同一个文件里了,也就减少了文件读取的次数,提高了效率。
散列索引是根据对应键的散列码来找到最终的索引项的技术,其实和B树就差不多了,也就是一种索引之上的二级辅助索引,我理解散列索引都是二级或更高级的稀疏索引,否则桶就太多了,效率也不会很高。
3 位图索引
位图索引是一种针对多个字段的简单查询设计一种特殊的索引,适用范围比较小,只适用于字段值固定并且值的种类很少的情况,比如性别,只能有男和女,或者级别,状态等等,并且只有在同时对多个这样的字段查询时才能体现出位图的优势。
位图的基本思想就是对每一个条件都用0或者1来表示,如有5条记录,性别分别是男,女,男,男,女,那么如果使用位图索引就会建立两个位图,对应男的10110和对应女的01001,这样做有什么好处呢,就是如果同时对多个这种类型的字段进行and或or查询时,可以使用按位与和按位或来直接得到结果了。
B+树最常用,性能也不差,用于范围查询和单值查询都可以。特别是范围查询,非得用B+树这种顺序的才可以了。
HASH的如果只是对单值查询的话速度会比B+树快一点,但是ORACLE好像不支持HASH索引,只支持HASH表空间。
位图的使用情况很局限,只有很少的情况才能用,一定要确定真正适合使用这种索引才用(值的类型很少并且需要复合查询),否则建立一大堆位图就一点意义都没有了。
(3)b树和b+树的区别?
b树:
b树(balance tree)和b+树应用在数据库索引,可以认为是m叉的多路平衡查找树,但是从理论上讲,二叉树查找速度和比较次数都是最小的,为什么不用二叉树呢?
因为 要考虑磁盘IO的影响,它相对于内存来说是很慢的。数据库索引是存储在磁盘上的,当数据量大时,就不能把整个索引全部加载到内存了,只能逐一加载每一个磁盘页(对应索引树的节点)。所以我们要减少IO次数,对于树来说,IO次数就是树的高度,而“矮胖”就是b树的特征之一,它的每个节点最多包含m个孩子,m称为b树的阶,m的大小取决于磁盘页的大小。
█一个M阶的b树具有如下几个特征:
定义任意非叶子结点最多只有M个儿子,且M>2;
根结点的儿子数为[2, M];
除根结点以外的非叶子结点的儿子数为[M/2, M],向上取整;
非叶子结点的关键字个数=儿子数-1;
所有叶子结点位于同一层;
k个关键字把节点拆成k+1段,分别指向k+1个儿子,同时满足查找树的大小关系。
█有关b树的一些特性,注意与后面的b+树区分:
关键字集合分布在整颗树中;
任何一个关键字出现且只出现在一个结点中;
搜索有可能在非叶子结点结束;
其搜索性能等价于在关键字全集内做一次二分查找;
█如图是一个3阶b树,顺便讲一下查询元素5的过程:
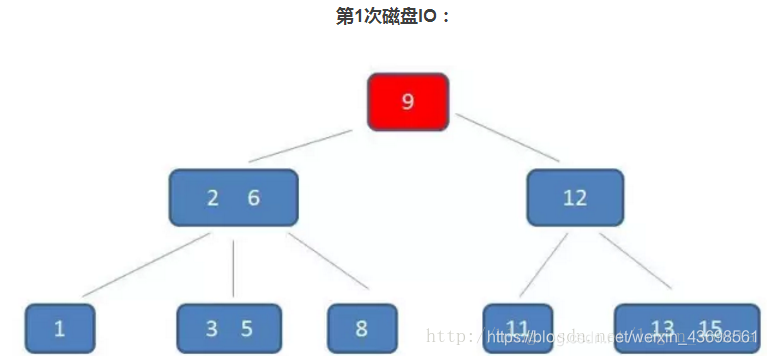
1,第一次磁盘IO,把9所在节点读到内存,把目标数5和9比较,小,找小于9对应的节点;
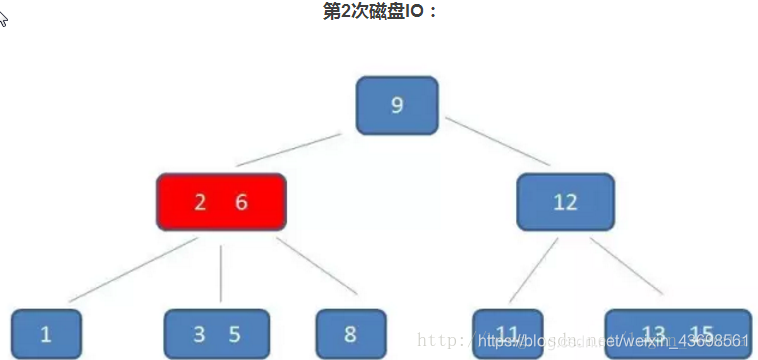
2,第二次磁盘IO,还是读节点到内存,在内存中把5依次和2、6比较,定位到2、6中间区域对应的节点;
3,第三次磁盘IO就不上图了,跟第二步一样,然后就找到了目标5。
可以看到,b树在查询时的比较次数并不比二叉树少,尤其是节点中的数非常多时,但是内存的比较速度非常快,耗时可以忽略,所以只要树的高度低,IO少,就可以提高查询性能,这是b树的优势之一。
b树的插入删除元素操作:
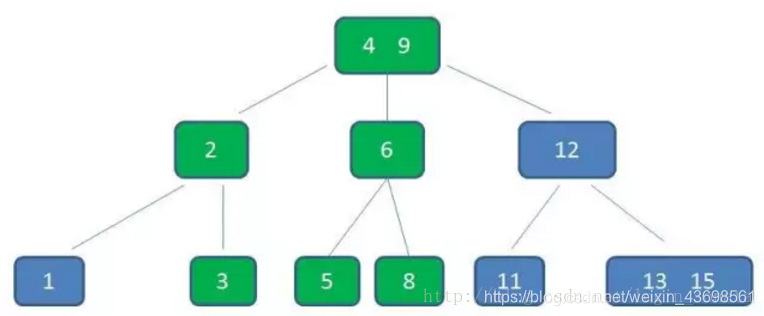
比如我们要在下图中插入元素4:
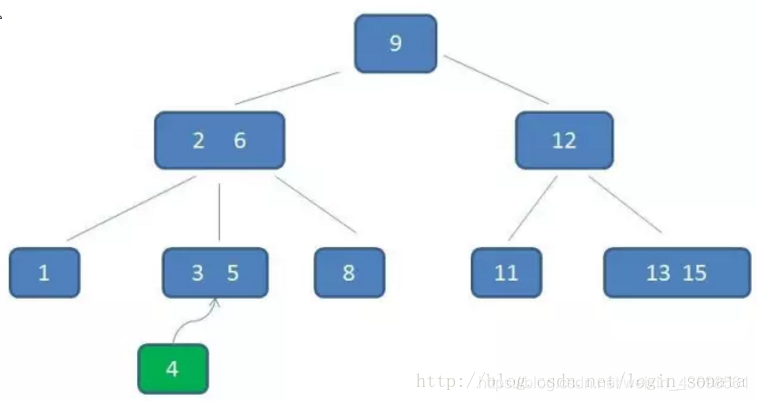
1,首先自顶向下查询找到4应该在的位置,即3、5之间;
2,但是3阶b树的节点最多只能有2个元素,所以把3、4、5里面的中间元素4上移(中间元素上移是插入操作的关键);
3,上一层节点加入4之后也超载了,继续中间元素上移的操作,现在根节点变成了4、9;
4,还要满足查找树的性质,所以对元素进行调整以满足大小关系,始终维持多路平衡也是b树的优势,最后变成这样:
再比如我们要删除元素11:
1,自顶向下查询到11,删掉它;
2,然后不满足b树的条件了,因为元素12所在的节点只有一个孩子了,所以我们要“左旋”,元素12下来,元素13上去:
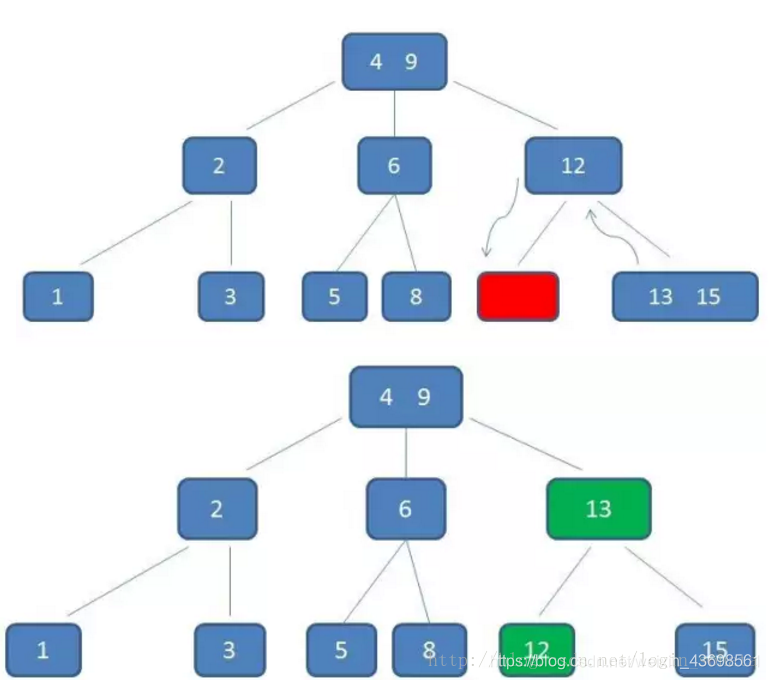
这时如果再删除15呢?很简单,当元素个数太少以至于不能再旋转时,12直接上去就行了。
b+树:
█b+树,是b树的一种变体,查询性能更好。m阶的b+树的特征:
有n棵子树的非叶子结点中含有n个关键字(b树是n-1个),这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点(b树是每个关键字都保存数据)。
所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
所有的非叶子结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
通常在b+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。
同一个数字会在不同节点中重复出现,根节点的最大元素就是b+树的最大元素。
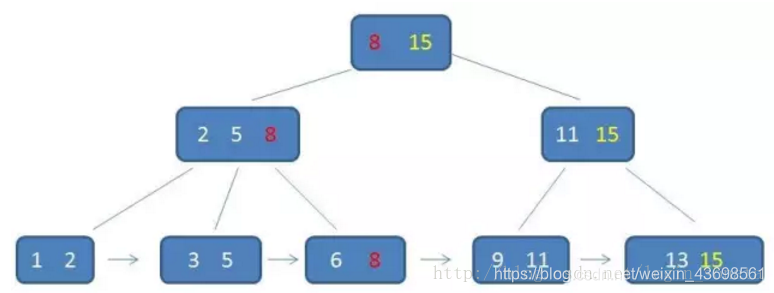
█b+树相比于b树的查询优势:
b+树的中间节点不保存数据,所以磁盘页能容纳更多节点元素,更“矮胖”;
b+树查询必须查找到叶子节点,b树只要匹配到即可不用管元素位置,因此b+树查找更稳定(并不慢);
对于范围查找来说,b+树只需遍历叶子节点链表即可,b树却需要重复地中序遍历,如下两图:
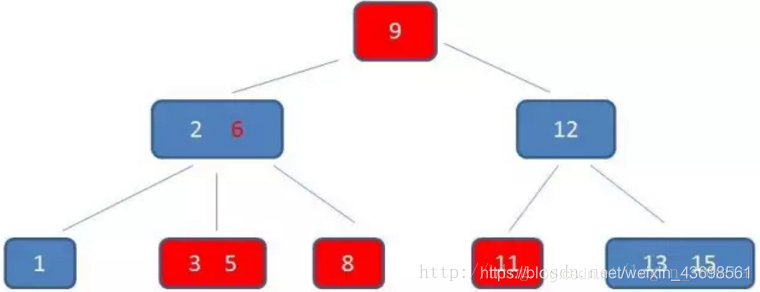

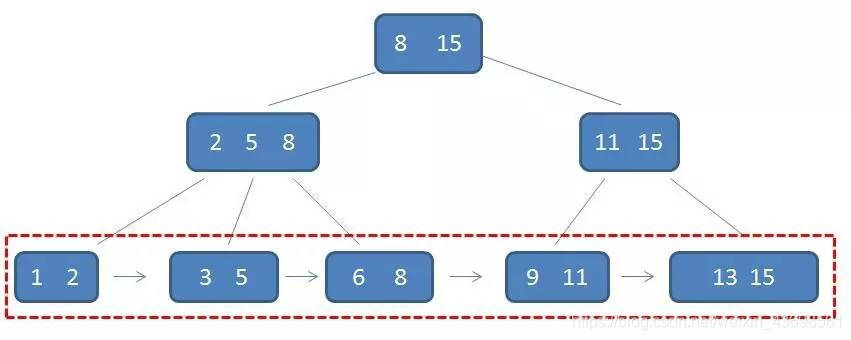
(3)画一个b+树?
一个m阶的B+树具有如下几个特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
 B+树中的卫星数据(Satellite Information):
B+树中的卫星数据(Satellite Information):
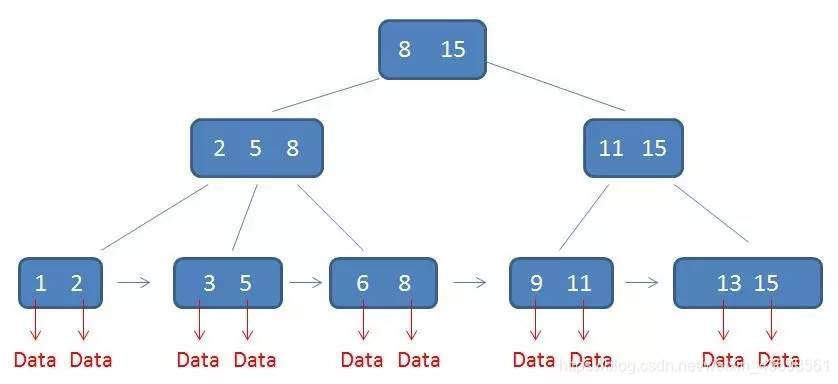
需要补充的是,在数据库的聚集索引(Clustered Index)中,叶子节点直接包含卫星数据。在非聚集索引(NonClustered Index)中,叶子节点带有指向卫星数据的指针。
B+树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
(4)讲一下你知道的java.util.concurrent包下的类?
1.Callable
Callable与Runnable类似,理解Callable可以从比较其与Runnable的区别开始:
1)从使用上:实现的Callable的类需要实现call()方法,此方法有返回对象V;而Runnable的子类需要实现run()方法,但没有返回值;
2)如果直接调用Callable的子类的call()方法,代码是同步顺序执行的;而Runnable的子类是线程,是代码异步执行。
3)将Callable子类submit()给线程池去运行,那么在时间上几个Callable的子类的执行是异步的。
即:如果一个Callable执行需要5s,那么直接调用Callable.call(),执行3次需要15s;
而将Callable子类交个线程执行3次,在池可用的情况下,只需要5s。这就是基本的将任务拆分异步执行的做法。
4)callable与future的组合用法:
(什么是Future?Future 表示异步计算的结果。其用于获取线程池执行callable后的结果,这个结果封装为Future类。详细可以参看Future的API,有示例。)
一种就像上面所说,对一个大任务进行分制处理;
另一种就是对一个任务的多种实现方法共同执行,任何一个返回计算结果,则其他的任务就没有执行的必要。选取耗时最少的结果执行。
2.Semaphore
一个计数信号量,主要用于控制多线程对共同资源库访问的限制。
典型的实例:1)公共厕所的蹲位……,10人等待5个蹲位的测试,满员后就只能出一个进一个。
2)地下车位,要有空余才能放行
3)共享文件IO数等
与线程池的区别:线程池是控制线程的数量,信号量是控制共享资源的并发访问量。
实例:Semaphore avialable = new Semaphore(int x,boolean y);
x:可用资源数;y:公平竞争或非公平竞争(公平竞争会导致排队,等待最久的线程先获取资源)
用法:在获取工作资源前,用Semaphore.acquire()获取资源,如果资源不可用则阻塞,直到获取资源;操作完后,用Semaphore.release()归还资源
代码示例:(具体管理资源池的示例,可以参考API的示例)
public class SemaphoreTest {
private static final int NUMBER = 5; //限制资源访问数
private static final Semaphore avialable = new Semaphore(NUMBER,true);
public static void main(String[] args) {
ExecutorService pool = Executors.newCachedThreadPool();
Runnable r = new Runnable(){
public void run(){
try {
avialable.acquire(); //此方法阻塞
Thread.sleep(10*1000);
System.out.println(getNow()+"--"+Thread.currentThread().getName()+"--执行完毕");
avialable.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
System.out.println(avialable.availablePermits());
for(int i=0;i<10;i++){
pool.execute(r);
}
System.out.println(avialable.availablePermits());
pool.shutdown();
}
public static String getNow(){
SimpleDateFormat sdf = new SimpleDateFormat("mm:ss");
return sdf.format(new Date());
}
}
3.ReentrantLock与Condition
1.ReentrantLock:可重入互斥锁。使用上与synchronized关键字对比理解:
1.1)synchronized示例:
synchronized(object){
//do process to object
}
1.2)ReentrantLock示例:(api)
private final ReentrantLock lock = new ReentrantLock();
public void m() {
lock.lock(); // block until condition holds
try {
// ... method body
} finally {
lock.unlock()
}
}
由1.1)和1.2)的示例很好理解,ReetantLock也就是一个锁,线程执行某段代码时,需要争用此类实例的锁,用完后要显示的释放此锁。
至于具体区别,后面在说……
2.Condition:此类是同步的条件对象,每个Condition实例绑定到一个ReetrantLock中,以便争用同一个锁的多线程之间可以通过Condition的状态来获取通知。
注意:使用Condition前,首先要获得ReentantLock,当条件不满足线程1等待时,ReentrantLock会被释放,以能让其他线程争用,其他线程获得reentrantLock,然后满足条件,唤醒线程1继续执行。
这与wait()方法是一样的,调用wait()的代码块要被包含在synchronized块中,而当线程r1调用了objectA.wait()方法后,同步对象的锁会释放,以能让其他线程争用;其他线程获取同步对象锁,完成任务,调用objectA.notify(),让r1继续执行。代码示例如下。
代码示例1(调用condition.await();会释放lock锁):
public class ConditionTest {
private static final ReentrantLock lock = new ReentrantLock(true);
//从锁中创建一个绑定条件
private static final Condition condition = lock.newCondition();
private static int count = 1;
public static void main(String[] args) {
Runnable r1 = new Runnable(){
public void run(){
lock.lock();
try{
while(count<=5){
System.out.println(Thread.currentThread().getName()+"--"+count++);
Thread.sleep(1000);
}
condition.signal(); //线程r1释放条件信号,以唤醒r2中处于await的代码继续执行。
} catch (InterruptedException e) {
e.printStackTrace();
}finally{
lock.unlock();
}
}
};
Runnable r2 = new Runnable(){
public void run(){
lock.lock();
try{
if(count<=5){
System.out.println("----$$$---");
condition.await(); //但调用await()后,lock锁会被释放,让线程r1能获取到,与Object.wait()方法一样
System.out.println("----------");
}
while(count<=10){
System.out.println(Thread.currentThread().getName()+"--"+count++);
Thread.sleep(1000);
}
} catch (InterruptedException e) {
e.printStackTrace();
}finally{
lock.unlock();
}
}
};
new Thread(r2).start(); //让r2先执行,先获得lock锁,但条件不满足,让r2等待await。
try {
Thread.sleep(100); //这里休眠主要是用于测试r2.await()会释放lock锁,被r1获取
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(r1).start();
}
}
代码示例2(此例子来自于Condition的API):

public class ConditionMain {
public static void main(String[] args) {
final BoundleBuffer buf = new ConditionMain().new BoundleBuffer();
new Thread(new Runnable(){
public void run() {
for(int i=0;i<1000;i++){
try {
buf.put(i);
System.out.println("入值:"+i);
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
new Thread(new Runnable(){
public void run() {
for(int i=0;i<1000;i++){
try {
int x = buf.take();
System.out.println("出值:"+x);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
}
public class BoundleBuffer {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Integer[] items = new Integer[10];
int putptr, takeptr, count;
public void put(int x) throws InterruptedException {
System .out.println("put wait lock");
lock.lock();
System .out.println("put get lock");
try {
while (count == items.length){
System.out.println("buffer full, please wait");
notFull.await();
}
items[putptr] = x;
if (++putptr == items.length)
putptr = 0;
++count;
notEmpty.signal();
} finally {
lock.unlock();
}
}
public int take() throws InterruptedException {
System .out.println("take wait lock");
lock.lock();
System .out.println("take get lock");
try {
while (count == 0){
System.out.println("no elements, please wait");
notEmpty.await();
}
int x = items[takeptr];
if (++takeptr == items.length)
takeptr = 0;
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}
}
4.BlockingQueue
简单介绍。这是一个阻塞的队列超类接口,concurrent包下很多架构都基于这个队列。BlockingQueue是一个接口,此接口的实现类有:ArrayBlockingQueue, DelayQueue, LinkedBlockingDeque, LinkedBlockingQueue, PriorityBlockingQueue, SynchronousQueue 。每个类的具体使用可以参考API。
这些实现类都遵从共同的接口定义(一目了然,具体参考api):
抛出异常 特殊值 阻塞 超时
插入 add(e) offer(e) put(e) offer(e, time, unit)
移除 remove() poll() take() poll(time, unit)
检查 element() peek() 不可用 不可用
5.CompletionService
1.CompletionService是一个接口,用来保存一组异步求解的任务结果集。api的解释是:将新生产的异步任务与已完成的任务结果集分离开来。
2.CompletionService依赖于一个特定的Executor来执行任务。实际就是此接口需要多线程处理一个共同的任务,这些多线程由一个指定的线程池来管理。CompletionService的实现类ExecutorCompletionService。
3.api的官方代码示例参考ExecutorCompletionService类的api(一个通用分制概念的函数)。
4.使用示例:如有时我们需要一次插入大批量数据,那么可能我们需要将1w条数据分开插,异步执行。如果某个异步任务失败那么我们还要重插,那可以用CompletionService来实现。下面是简单代码:
(代码中1w条数据分成10份,每次插1000条,如果成功则返回true,如果失败则返回false。那么忽略数据库的东西,我们假设插1w条数据需10s,插1k条数据需1s,那么下面的代码分制后,插入10条数据需要2s。为什么是2s呢?因为我们开的线程池是8线程,10个异步任务就有两个需要等待池资源,所以是2s,如果将下面的8改为10,则只需要1s。)
public class CompletionServiceTest {
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(8); //需要2s,如果将8改成10,则只需要1s
CompletionService<Boolean> cs = new ExecutorCompletionService<Boolean>(pool);
Callable<Boolean> task = new Callable<Boolean>(){
public Boolean call(){
try {
Thread.sleep(1000);
System.out.println("插入1000条数据完成");
} catch (InterruptedException e) {
e.printStackTrace();
}
return true;
};
};
System.out.println(getNow()+"--开始插入数据");
for(int i=0;i<10;i++){
cs.submit(task);
}
for(int i=0;i<10;i++){
try {
//ExecutorCompletionService.take()方法是阻塞的,如果当前没有完成的任务则阻塞
System.out.println(cs.take().get());
//实际使用时,take()方法获取的结果可用于处理,如果插入失败,则可以进行重试或记录等操作
} catch (InterruptedException|ExecutionException e) {
e.printStackTrace();
}
}
System.out.println(getNow()+"--插入数据完成");
pool.shutdown();
}
public static String getNow(){
SimpleDateFormat sdf = new SimpleDateFormat("mm:ss");
return sdf.format(new Date());
}
}
5.CompletionService与Callable+Future的对比:
在上面的Callable中说过,Callable+Future能实现任务的分治,但是有个问题就是:不知道call()什么时候完成,需要人为控制等待。
而jdk通过CompetionService已经将此麻烦简化,通过CompletionService将异步任务完成的与未完成的区分开来(正如api的描述),我们只用去取即可。
CompletionService有什么好处呢?
如上所说:1)将已完成的任务和未完成的任务分开了,无需开发者操心;2)隐藏了Future类,简化了代码的使用。真想点个赞!
6.CountDownLatch
1.CountDownLatch:api解释:一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。个人理解是CountDownLatch让可以让一组线程同时执行,然后在这组线程全部执行完前,可以让另一个线程等待。
就好像跑步比赛,10个选手依次就位,哨声响才同时出发;所有选手都通过终点,才能公布成绩。那么CountDownLatch就可以控制10个选手同时出发,和公布成绩的时间。
CountDownLatch 是一个通用同步工具,它有很多用途。将计数 1 初始化的 CountDownLatch 用作一个简单的开/关锁存器,或入口:在通过调用 countDown() 的线程打开入口前,所有调用 await 的线程都一直在入口处等待。用 N 初始化的 CountDownLatch 可以使一个线程在 N 个线程完成某项操作之前一直等待,或者使其在某项操作完成 N 次之前一直等待。
CountDownLatch startSignal = new CountDownLatch(1);
CountDownLatch doneSignal = new CountDownLatch(N);
代码示例可参考api的示例。(重要)
2.代码示例:
参考链接中的示例:http://blog.csdn.net/xsl1990/article/details/18564097
个人示例:
public class CountDownLatchTest {
private static SimpleDateFormat sdf = new SimpleDateFormat("mm:ss");
public static void main(String[] args) {
final CountDownLatch start = new CountDownLatch(1); //用一个信号控制一组线程的开始,初始化为1
final CountDownLatch end = new CountDownLatch(10); //要等待N个线程的结束,初始化为N,这里是10
Runnable r = new Runnable(){
public void run(){
try {
start.await(); //阻塞,这样start.countDown()到0,所有阻塞在start.await()处的线程一起执行
Thread.sleep((long) (Math.random()*10000));
System.out.println(getNow()+"--"+Thread.currentThread().getName()+"--执行完成");
end.countDown();//非阻塞,每个线程执行完,让end--,这样10个线程执行完end倒数到0,主线程的end.await()就可以继续执行
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
for(int i=0;i<10;i++){
new Thread(r).start(); //虽然开始了10个线程,但所有线程都阻塞在start.await()处
}
System.out.println(getNow()+"--线程全部启动完毕,休眠3s再让10个线程一起执行");
try {
Thread.sleep(3*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getNow()+"--开始");
start.countDown(); //start初始值为1,countDown()变成0,触发10个线程一起执行
try {
end.await(); //阻塞,等10个线程都执行完了才继续往下。
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getNow()+"--10个线程都执行完了,主线程继续往下执行!");
}
private static String getNow(){
return sdf.format(new Date());
}
}
7.CyclicBarrier
1.一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点。也就是说,这一组线程的执行分几个节点,每个节点往下执行,都需等待其他线程,这就需要这种等待具有循环性。CyclicBarrier在这样的情况下就很有用。
2.CyclicBarrier与CountDownLacth的区别:
1)CountDownLacth用于一个线程与一组线程之间的相互等待。常用的就是一个主线程与一组分治线程之间的等待:主线程发号令,一组线程同时执行;一组线程依次执行完,再唤醒主线程继续执行;
CyclicBarrier用于一组线程执行时,每个线程执行有多个节点,每个节点的处理需要相互等待。如:对5个文件进行处理,按行将各个文件数字挑出来合并成一行,排序,并输出到另一个文件,那每次处理都需要等待5个线程读入下一行。(api示例可供参考)
2)CountDownLacth的处理机制是:初始化一个值N(相当于一组线程有N个),每个线程调用一次countDown(),那么cdLatch减1,等所有线程都调用过countDown(),那么cdLatch值达到0,那么线程从await()处接着玩下执行。
CyclicBarrier的处理机制是:初始化一个值N(相当于一组线程有N个),每个线程调用一次await(),那么barrier加1,等所有线程都调用过await(),那么barrier值达到初始值N,所有线程接着往下执行,并将barrier值重置为0,再次循环下一个屏障;
3)由2)可以知道,CountDownLatch只可以使用一次,而CyclicBarrier是可以循环使用的。
3.个人用于理解的示例:
public class CyclicBarrierTest {
private static final CyclicBarrier barrier = new CyclicBarrier(5,
new Runnable(){
public void run(){ //每次线程到达屏障点,此方法都会执行
System.out.println("\n--------barrier action--------\n");
}
});
public static void main(String[] args) {
for(int i=0;i<5;i++){
new Thread(new CyclicBarrierTest().new Worker()).start();
}
}
class Worker implements Runnable{
public void run(){
try {
System.out.println(Thread.currentThread().getName()+"--第一阶段");
Thread.sleep(getRl());
barrier.await(); //每一次await()都会阻塞,等5个线程都执行到这一步(相当于barrier++操作,加到初始化值5),才继续往下执行
System.out.println(Thread.currentThread().getName()+"--第二阶段");
Thread.sleep(getRl());
barrier.await(); //每一次5个线程都到达共同的屏障节点,会执行barrier初始化参数中定义的Runnable.run()
System.out.println(Thread.currentThread().getName()+"--第三阶段");
Thread.sleep(getRl());
barrier.await();
System.out.println(Thread.currentThread().getName()+"--第四阶段");
Thread.sleep(getRl());
barrier.await();
System.out.println(Thread.currentThread().getName()+"--第五阶段");
Thread.sleep(getRl());
barrier.await();
System.out.println(Thread.currentThread().getName()+"--结束");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
}
public static long getRl(){
return Math.round(10000);
}
}
4.参考api的示例。
api的示例自己看,就是加深印象。
但是api中有一点描述:如果屏障操作在执行时不依赖于正挂起的线程,则线程组中的任何线程在获得释放时都能执行该操作。为方便此操作,每次调用 await() 都将返回能到达屏障处的线程的索引。然后,您可以选择哪个线程应该执行屏障操作,例如:
if (barrier.await() == 0) {
<span style="white-space:pre"> </span> // log the completion of this iteration
}
就是说,barrier.await()还会返回一个int值。这个返回值到底是什么呢?不是返回的线程的索引,返回的是:N-进入等待线程数,如5个线程,5线程都进入等待,那返回值就是0(具体可以参看源码)。那么barrier.await()==0也可以看做是一个N线程都达到公共屏障的信号,然后在此条件下处理原本需要放在Runnable参数中的逻辑。不用担心多线程会多次执行此逻辑,N个线程只有一个线程barrier.await()==0。
8.Exchanger
1.Exchanger可以在对中对元素进行配对和交换的线程的同步点。api上不是太好理解,个人理解说白了就是两个线程交换各自使用的指定内存数据。
2.场景:
api中有示例,两个线程A、B,各自有一个数据类型相同的变量a、b,A线程往a中填数据(生产),B线程从b中取数据(消费)。具体如何让a、b在内存发生关联,就由Exchanger完成。
api中说:Exchanger 可能被视为 SynchronousQueue 的双向形式。怎么理解呢?传统的SynchronousQueue存取需要同步,就是A放入需要等待B取出,B取出需要等待A放入,在时间上要同步进行。而Exchanger在B取出的时候,A是同步在放入的。即:1)A放入a,a满,然后与B交换内存,那A就可以操作b(b空),而B可以操作a;2)等b被A存满,a被B用完,再交换;3)那A又填充a,B又消费b,依次循环。两个内存在一定程度上是同时被操作的,在时间上不需要同步。
再理解就是:如果生产需要5s,消费需要5s。SynchronousQueue一次存取需要10s,而Exchanger只需要5s。4.注意事项:
目前只知道Exchanger只能发生在两个线程之间。但实际上Exchanger的源码是有多个插槽(Slot),交换是通过线程ID的hash值来定位的。目前还没搞懂?待后续。
如果一组线程aGroup操作a内存,一组线程bGroup操作b内存,如何交换?能不能交换?
3.代码示例:
public class ExchangerTest {
private SimpleDateFormat sdf = new SimpleDateFormat("mm:ss");
private static Exchanger<Queue<Integer>> changer = new Exchanger<Queue<Integer>>();
public static void main(String[] args) {
new Thread(new ExchangerTest().new ProducerLoop()).start();
new Thread(new ExchangerTest().new ConsumerLoop()).start();
}
class ProducerLoop implements Runnable{
private Queue<Integer> pBuffer = new LinkedBlockingQueue<Integer>();
private final int maxnum = 10;
@Override
public void run() {
try{
for(;;){
Thread.sleep(500);
pBuffer.offer((int) Math.round(Math.random()*100));
if(pBuffer.size() == maxnum){
System.out.println(getNow()+"--producer交换前");
pBuffer = changer.exchange(pBuffer);
System.out.println(getNow()+"--producer交换后");
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
class ConsumerLoop implements Runnable{
private Queue<Integer> cBuffer = new LinkedBlockingQueue<Integer>();
@Override
public void run() {
try{
for(;;){
if(cBuffer.size() == 0){
System.out.println("\n"+getNow()+"--consumer交换前");
cBuffer = changer.exchange(cBuffer);
System.out.println(getNow()+"--consumer交换后");
}
System.out.print(cBuffer.poll()+" ");
Thread.sleep(500);
}
}catch(Exception e){
e.printStackTrace();
}
}
}
private String getNow(){
return sdf.format(new Date());
}
}
4.注意事项:
目前只知道Exchanger只能发生在两个线程之间。但实际上Exchanger的源码是有多个插槽(Slot),交换是通过线程ID的hash值来定位的。目前还没搞懂?待后续。
如果一组线程aGroup操作a内存,一组线程bGroup操作b内存,如何交换?能不能交换?
9.Phaser
Phaser是jdk1.7的新特性。其功能类似CyclicBarrier和CountDownLatch,但其功能更灵活,更强大,支持动态调整需要控制的线程数。不重复了。参考链接:
http://whitesock.iteye.com/blog/1135457
(5)treemap了解吗?
存储结构
分析一个数据类型最好的办法就是看它的内部存储结构,通过分析存储的数据结构,我们可以更清楚的看到它的实现原理和方法,从而更好的去使用,因为特定的数据结构只有用在特定的场景下,才会发挥它最大的作用。
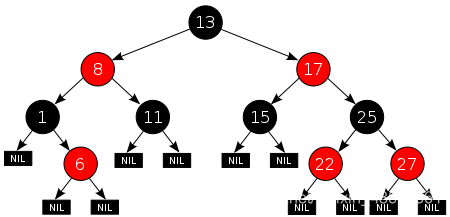
TreeMap内部使用的数据结构为红黑树(Red-Black tree),关于红黑树,这里简单介绍一下,红黑树属于二叉排序树,但是在二叉排序树的基础上,又增加了一些规则,比如定义节点的着色等,这样就不会出现一些极端的情况,比如,整个树出现了偏离,变为了单分支结构的树,这样,整个树的高度就是n,n为全部的节点数。在这样的节点分部情况下,查找一个节点所需的时间复杂度为O(n),为了避免这样的情况,聪明的人类又发明了另一种树形结构,叫做平衡二叉树,平衡二叉树查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn)。红黑树就是平衡二叉树的一种实现方式。红黑树定义了一些规则,保证树的高度维持在logn。
1、每个结点要么是红的要么是黑的。
2、根结点是黑的。
3、每个叶结点(叶结点即指树尾端NIL指针或NULL结点)都是黑的。
4、如果一个结点是红的,那么它的两个儿子都是黑的。
5、对于任意结点而言,其到叶结点树尾端NIL指针的每条路径都包含相同数目的黑结点。
规则
1、基于红黑树(Red-Black tree)的数据结构实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
2、不允许插入为Null的key
3、可以插入值为Null的Value
4、若Key重复,则后面插入的直接覆盖原来的Value
5、非线程安全
6、根据key排序,key必须实现Comparable接口,可自定义比较器实现排序。
7、TreeMap使用的数据结构决定了他的插入操作变的比较复杂,需要维护一个红黑树,所以TreeMap不适合用在频繁修改的场景,如果不需要实现有序性,则建议使用HashMap,存取效率要高一些。
类继承关系
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
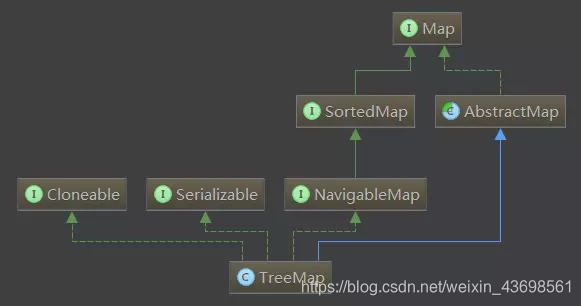
1.Map 接口: 定义将键值映射到值的对象,Map规定不能包含重复的键值,每个键最多可以映射一个值,这个接口是用来替换Dictionary类。
2.AbstractMap 类: 提供了一个Map骨架的实现,尽量减少了实现Map接口所需要的工作量
3.SortedMap 接口: 定义按照key排序的Map结构,规定key-value是根据键key值的自然排序进行排序的,或者根据构造key-value时设定的构造器进行排序。
4.NavigableMap 接口: 是SortedMap接口的子接口,在其基础上扩展了针对搜索目标返回最近匹配项的导航方法,例如方法lowEntry、floorEntry、ceilingEntry等,如果不存在这样的键,则返回null
5.Cloneable 接口: 实现了该接口的类可以显示的调用Object.clone()方法,合法的对该类实例进行字段复制,如果没有实现Cloneable接口的实例上调用Obejct.clone()方法,会抛出CloneNotSupportException异常。正常情况下,实现了Cloneable接口的类会以公共方法重写Object.clone()
6.Serializable 接口: 实现了该接口标示了类可以被序列化和反序列化,具体的 查询序列化详解
SortedMap接口
public interface SortedMap<K,V> extends Map<K,V> {
Comparator<? super K> comparator(); //用来返回这个map用的比较器,或者null
SortedMap<K,V> subMap(K fromKey, K toKey); //返回部分map满足key大于等于fromKey,小于toKey
SortedMap<K,V> headMap(K toKey); //返回部分map满足key小于toKey
SortedMap<K,V> tailMap(K fromKey); //返回部分map满足key大于等于fromKey
K firstKey(); //返回第一个key(最小的key)
K lastKey(); //返回最后一个key(最大的key)
Set keySet();
Collection values();
Set<Map.Entry<K, V>> entrySet();
}
TreeMap接口
Entry<K, V> ceilingEntry(K key) //返回键不小于key的最小键值对entry
K ceilingKey(K key)//返回键不小于key的最小键
void clear()//清空TreeMapObjectclone()//克隆TreeMap
Comparator<? super K> comparator()//比较器
boolean containsKey(Object key)//是否包含键为key的键值对
NavigableSet descendingKeySet()//获取降序排列key的Set集合
NavigableMap<K, V> descendingMap()//获取降序排列的Map
Set<Entry<K, V>> entrySet()//获取键值对entry的Set集合
Entry<K, V> firstEntry()//第一个entry
K firstKey()//第一个key
Entry<K, V> floorEntry(K key)//获取不大于key的最大键值对
K floorKey(K key)//获取不大于key的最大Key
V get(Object key)//获取键为key的值value
NavigableMap<K, V> headMap(K to, boolean inclusive)//获取从第一个节点开始到to的子Map, inclusive表示是否包含to节点
SortedMap<K, V> headMap(K toExclusive)//获取从第一个节点开始到to的子Map, 不包括toExclusive
Entry<K, V> higherEntry(K key)//获取键大于key的最小键值对
K higherKey(K key)//获取键大于key的最小键
boolean isEmpty()//判空
Set keySet()//获取key的Set集合
Entry<K, V> lastEntry()//最后一个键值对
K lastKey()//最后一个键
Entry<K, V> lowerEntry(K key)//键小于key的最大键值对
K lowerKey(K key)//键小于key的最大键值对
NavigableSet navigableKeySet()//返回key的Set集合
Entry<K, V> pollFirstEntry()//获取第一个节点,并删除
Entry<K, V> pollLastEntry()//获取最后一个节点并删除
V put(K key, V value)//插入一个节点
V remove(Object key)//删除键为key的节点
int size()//Map大小
SortedMap<K, V> subMap(K fromInclusive, K toExclusive)//获取从fromInclusive到toExclusive子Map,前闭后开
NavigableMap<K, V> subMap(K from, boolean fromInclusive, K to, boolean toInclusive)
NavigableMap<K, V> tailMap(K from, boolean inclusive)//获取从from开始到最后的子Map,inclusive标志是否包含from
SortedMap<K, V> tailMap(K fromInclusive)
(6)使用数组实现一个队列,写java代码
public class ArrayQueue <T>
{
private T[] queue;//队列数组
private int head=0;//头下标
private int tail=0;//尾下标
private int count=0;//元素个数
public ArrayQueue()
{
queue=(T[])new Object[10];
this.head=0;//头下标为零
this.tail=0;
this.count=0;
}
public ArrayQueue(int size)
{
queue=(T[])new Object[size];
this.head=0;
this.tail=0;
this.count=0;
}
//入队
public boolean inQueue(T t)
{
if(count==queue.length)
return false;
queue[tail++%(queue.length)]=t;//如果不为空就放入下一个
count++;
return true;
}
//出队
public T outQueue()
{
if(count==0)//如果是空的那就不能再出栈了
return null;
count--;
return queue[head++%(queue.length)];
}
//查队头
public T showHead()
{
if(count==0) return null;
return queue[head];
}
//判满
public boolean isFull()
{
return count==queue.length;
}
//判空
public boolean isEmpty()
{
return count==0;
}
}
二面(项目相关)
hr面
看成绩单
保研还是考研
对工作最看重哪些方面
面过哪些公司,有什么offer
