MSCNN
基于MSCNN的人群密度估计:
网络结构
网上已经有很多介绍mscnn网络结构的文章了,我就不再赘述。只说一下网络中Multi-Scale Blob结构的实现,在keras中实现很简单,看看源码就很容易理解了。论文中分了两种msb结构,一种是正常的,一个块中包含4个卷积层,卷积核大小分别是(9,7,5,3);还有一个称为mini msb块,包含3个卷积层,卷积核的大小为(7,5,3)。MSCNN的网络模型的代码主要参考了https://www.jianshu.com/p/29a213f22b40,特此感谢!在输出层千万不能使用relu,否则会导致预测的输出全部为0,而且损失值还在一直下降!在最后的输出层我试过relu(sigmoid(x))、relu(tanth(x))、sigmoid(x)、tanth(x),最终还是tanth(x)靠谱!
def MSB(filter_num):
def f(x):
params = {
'strides': 1,
'activation': 'relu',
'padding': 'same',
'kernel_regularizer': l2(5e-4)
}
x1 = Conv2D(filters=filter_num, kernel_size=(9, 9), **params)(x)
x2 = Conv2D(filters=filter_num, kernel_size=(7, 7), **params)(x)
x3 = Conv2D(filters=filter_num, kernel_size=(5, 5), **params)(x)
x4 = Conv2D(filters=filter_num, kernel_size=(3, 3), **params)(x)
x = concatenate([x1, x2, x3, x4])
x = BatchNormalization()(x)
return x
return f
def MSB_mini(filter_num):
def f(x):
params = {
'strides': 1,
'activation': 'relu',
'padding': 'same',
'kernel_regularizer': l2(5e-4)
}
x2 = Conv2D(filters=filter_num, kernel_size=(7, 7), **params)(x)
x3 = Conv2D(filters=filter_num, kernel_size=(5, 5), **params)(x)
x4 = Conv2D(filters=filter_num, kernel_size=(3, 3), **params)(x)
x = concatenate([x2, x3, x4])
x = BatchNormalization()(x)
x = Activation('relu')(x)
return x
return f
然后在主干网将这两种块有机的结合起来
def MSCNN(input_shape):
input_tensor = Input(shape=input_shape)
# block1
x = Conv2D(filters=64, kernel_size=(9, 9), strides=1, padding='same', activation='relu')(input_tensor)
# block2
x = MSB(4*16)(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
# block3
x = MSB(4*32)(x)
x = MSB(4*32)(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = MSB_mini(3*64)(x)
x = MSB_mini(3*64)(x)
# x = MSB(4*64)(x)
x = Conv2D(1000, (1, 1), activation='relu', kernel_regularizer=l2(5e-4))(x)
x = Conv2D(1, (1, 1), activation='tanh')(x)
model = Model(inputs=input_tensor, outputs=x)
return model
关于损失函数
- 论文中直接使用了mse作为损失函数,我就不写公式了,体现在代码中就一行。keras支持多种损失函数,具体请参加官方文档。这里想多啰嗦一句,keras对用户很友好,封装了很多API,极大的减少了代码量而且结构清晰,但是这样对于初学者来说,在享受便捷的同时却缺少了对细节的理解,不利于成长!如果想对深度学习有更深入的理解,而不是仅成为一个名副其实的“调包侠”,还是乖乖的先使用tf的原生API来写比较好,对于理解模型和公式都有好处!(在实际中的一点感悟,还请莫笑)
model.compile(optimizer=Adam(lr=3e-4), loss='mse')
- 另一种损失函数
在使用MSE作为损失函数的时候,只考虑了像素误差,而忽略了估计密度图和真实密度图之间的全局和局部的相关性。中科院提出的DS Net中使用了多尺度密度水平一致性损失。给出的公式如下:
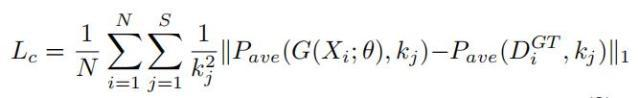
其中 s 是用于一致性检查的尺度级别数,P 是平均池化操作, 为平均池化的指定输出大小。在论文中作者采用三个尺度级别,每个输出尺寸分别为 1×1、2×2 和 4×4。输出大小为 1×1 的第一个尺度级别捕获密度水平的全局特征,而其他两个尺度级别表示图像块的局部密度水平。MSE的损失函数如下:
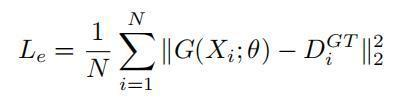
则总的损失函数为上式两个损失的加权求和
其中 取100或1000
这篇论文没有给出源码,我自己写了实现,不过我的最终效果同直接使用mse区别不大,也可能是因为我没有使用论文中的DS Net的原因。
def get_avgpoolLoss(y_true, y_pred, k):
loss = KTF.mean((abs(AveragePooling2D(pool_size=(k, k), strides=(1, 1))(y_true) -
AveragePooling2D(pool_size=(k, k), strides=(1, 1))(y_pred)))) / k
return loss
def denseloss(y_true, y_pred, e=1000):
Le = KTF.mean(KTF.square(y_pred-y_true), axis=-1)
Lc = get_avgpoolLoss(y_true, y_pred, 1)
Lc += get_avgpoolLoss(y_true, y_pred, 2)
Lc += get_avgpoolLoss(y_true, y_pred, 4)
shp = KTF.get_variable_shape(y_pred)
Lc = Lc / (shp[1] * shp[2])
return Le + e * Lc
使用的时候,直接将损失函数的名称改为denseloss即可
model.compile(optimizer=Adam(lr=3e-4), loss=denseloss)
网络训练
将数据生成器写好后,直接训练即可。数据的生成请参看 数据集制作和数据生成器
def get_callbacks():
early_stopping = EarlyStopping(monitor='val_loss', patience=20)
reduce_lr = ReduceLROnPlateau(monitor='loss', factor=0.1, patience=5, min_lr=1e-7, verbose=True)
models_path = os.path.join(ROOT_DIR, 'models')
if not os.path.exists(models_path):
os.mkdir(models_path)
model_checkpoint = ModelCheckpoint(os.path.join(models_path, 'mscnn_model_weights.h5'), monitor='val_loss',
verbose=True, save_best_only=True, save_weights_only=True)
callbacks = [early_stopping, reduce_lr, model_checkpoint, TensorBoard(log_dir='../tensorlog')]
return callbacks
model.fit_generator(CrowDataset().gen_train(batch_size, 224),
steps_per_epoch=CrowDataset().get_train_num() // batch_size,
validation_data=CrowDataset().gen_valid(batch_size, 224),
validation_steps=CrowDataset().get_valid_num() // batch_size,
epochs=int(args_['epochs']),
callbacks=callbacks)
预测与输出
由于本项目将所有大于100人的图片都输出100人,所以在输出的时候 第一步使用密度等级网络将图片分成3类,然后仅仅将输出的标签为1的图片送入mscnn再进行人数预测,最终给出所有图片中包含的人数。在我1080ti的显卡下,每秒输出20到30张。
# 密度等级分类模型
dense_net = DenseLevelNet(VGG_Model, Dense_Model)
dense_model = dense_net.model()
dense_model.load_weights(Dense_Model, by_name=True)
# 具体人数分类模型
crow_model = MSCNN((224, 224, 3))
crow_model.load_weights(Mscnn_Model)
for img_name in tqdm(images):
try:
img = imopen(img_name)
img = np.expand_dims(img, axis=0)
dense_prob = dense_model.predict(img)
dense_level = np.argmax(dense_prob, axis=1)
dense_level = dense_level[0]
if dense_level == 0:
crow_count = 0
elif dense_level == 2:
crow_count = 100
else:
dmap = crow_model.predict(img)
dmap = np.squeeze(dmap, axis=-1)
crow_count = int(np.sum(dmap))
res.append([os.path.split(img_name)[1], crow_count])
except Exception as e:
print(img_name)
res.append([os.path.split(img_name)[1], -1])
