计算机的缓存模型
解决问题
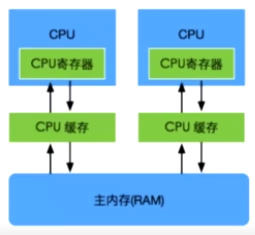
cpu缓存是为了减少处理器访问内存所需平均时间的部件。
在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。
其容量远小于内存,但交换速度却比内存快得多。
步骤
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。
如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
原理
缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。
这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。
有效利用这种局部性,缓存可以达到极高的命中率。
java(线程)内存模型

java 线程内存模型跟cpu缓存模型非常相似,是基于cpu缓存模型来建立的,
并且java线程内存模型是标准化的,屏蔽掉了底层不同计算机的区别。
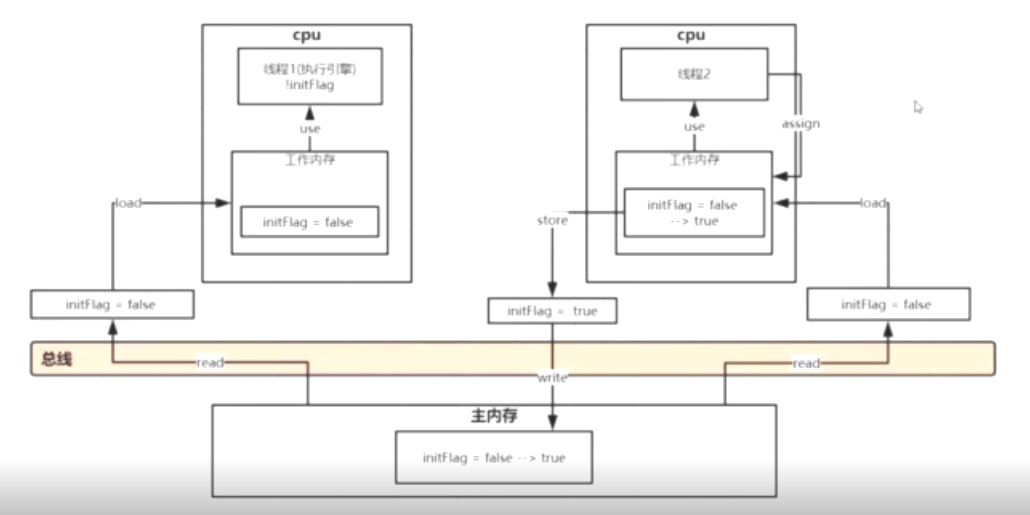
需要注意的是,线程i是直接和他的工作内存进行通信的 工作内存在初始化的时候,将主内存的各个共享变量加载到工作内存。
各种常用的原子操作
+ lock(锁定):作用于主内存,它把一个变量标记为一条线程独占状态;
+ read(读取):作用于主内存,它把变量值从主内存传送到线程的工作内存中,以便随后的load动作使用;
+ load(载入):作用于工作内存,它把read操作的值放入工作内存中的变量副本中;
+ use(使用):作用于工作内存,它把工作内存中的值传递给执行引擎,每当虚拟机遇到一个需要使用这个变量的指令时候,将会执行这个动作;
+ assign(赋值):作用于工作内存,它把从执行引擎获取的值赋值给工作内存中的变量,每当虚拟机遇到一个给变量赋值的指令时候,执行该操作;
+ store(存储):作用于工作内存,它把工作内存中的一个变量传送给主内存中,以备随后的write操作使用;
+ write(写入):作用于主内存,它把store传送值放到主内存中的变量中。
+ unlock(解锁):作用于主内存,它将一个处于锁定状态的变量释放出来,释放后的变量才能够被其他线程锁定;下面是一个典型的volalite的执行过程
多处理器环境下,缓存不一致问题的两种解决方法
总线加锁(早期,性能低):cpu从主内存读取数据到高速缓存,会在总线对这个数据加锁,这样其他的cpu就没法去读或者去写这个数据,
直到这个cpu使用完数据释放锁后,其他cpu才能进行读取。
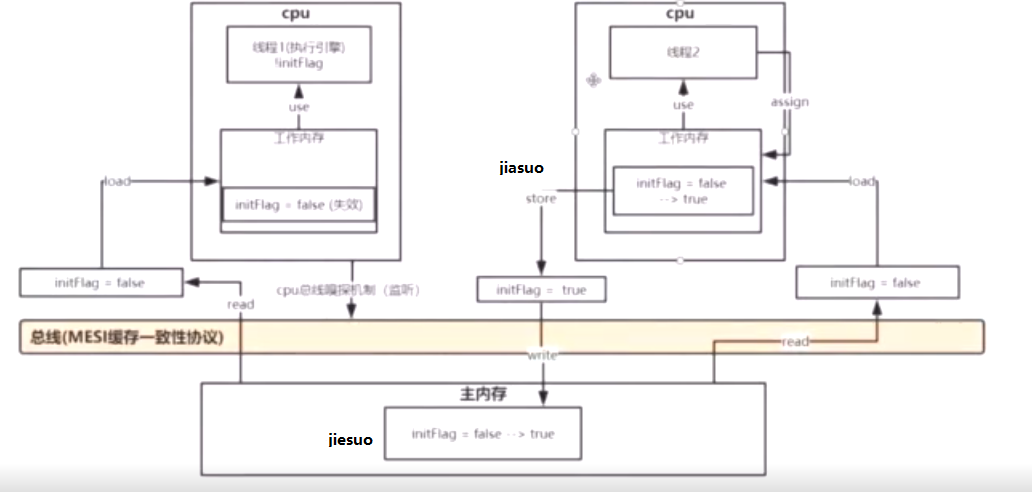
MESI缓存一致性协议:多个cpu从主内存读取同一个数据到各自的高速缓存,当其中某个cpu修改了缓存里的数据的时候,
该数据会马上同步到主内存,其他cpu会通过总线嗅探机制(jian ting)感知数据的变化,
从而设置自己的缓存里的数据为失效状态。
JMM解决缓存不一致:volatile底层实现原理
底层主要通过汇编lock前缀指令,它会锁定这块内存区域的缓存并写回到主内存
IA-32架构软件开发手册对lock指令的解释:
1.会将当前处理器缓存行的数据立即写回到系统内存。
2.这个写回内存的操作会引起在其他cpu里面缓存了该内存地址的数据无效。
如果在lock指令执行的时候,有其他的读操作,或者写操作,会出现不一致,又如何解决?
加上一把非常细力度的锁
就是说:volatile 是轻量级的锁,它不会引起线程上下文的切换和调度。
足够轻量,只是锁住一条内存赋值指令。
volatile的特点
volatile可以保证可见性,但是不能保证原子性
可见性:对一个volatile的读,总是可以看到对这个变量最终的写.
(并非是修改了之后,会"通知"其他线程去取最新的数据,而是下一次有线程取这个数据的时候,
禁止他们从自己的线程缓存中取数据,直接到原始的内存去取最新值。)
原子性:volatile对单个读 / 写具有原子性(32 位 Long、Double),但是复合操作除外,例如i++ 。
具体来讲一个这样的场景:有两个线程一起做i++的操作,由于volatile的实现原理,
其中一个在执行lock指令的时候,会使得其他cpu里面缓存了该内存地址的数据失效。(但是其他的cpu可能已经做完了这个i++操作)
这样不就让其他cpu做的操作失效了嘛。 如何解决呢? 使用synchronize.
有序性:JVM 底层采用“内存屏障”来实现 volatile 语义,防止指令重排序。
指令重排是指在程序执行过程中, 为了性能考虑, 编译器和CPU可能会对指令重新排序.
“内存屏障”:简单理解:有lock之后,cpu就不会把后面的语句优化到前面;前面的语句优化到后面。