**
向量
**
1.向量是R中最为基本的类型
2.一个向量中元素的类型必须相同,包括:数值型、逻辑型、字符型、复值型
mode() ——对象的类型
length() ——对象的长度(指元素个数)
NA —— 缺失值(not availabel)
NaN ——表示不是数字的值(not a number)
a=“statistic”;b=TRUE;c=1i
mode(a);mode(b);mode(c )
[1] “character”
[1] “logical”
[1] “complex”
length(a);length(b);length(c )
[1] 1
[1] 1
[1] 1
z=c(‘zx’,‘df’)
length(z)
[1] 2
sqrt(-2)
[1] NaN
Warning message:
In sqrt(-2) : 产生了NaNs
向量的建立
建立数值向量的函数
seq() ——若向量(序列)具有较为简单的规律
rep() —— 若向量(序列)具有较为复杂的规律
sequence()—— 若向量(序列)为整数序列
c() —— 若向量(序列)没有什么规律
seq(1,10,by=0.5) # =seq(from=1,to=10,by=0.5)
[1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5
[15] 8.0 8.5 9.0 9.5 10.0
seq(1,10,length=21) # = seq(1,10,length.out=21)
[1] 1.00 1.45 1.90 2.35 2.80 3.25 3.70 4.15 4.60 5.05 5.50 5.95
[13] 6.40 6.85 7.30 7.75 8.20 8.65 9.10 9.55 10.00
rep(2:5,2) # = rep(2:5, times=2)
[1] 2 3 4 5 2 3 4 5
rep(2:5, c(1,2,3,4))
[1] 2 3 3 4 4 4 5 5 5 5
rep(1:3, times = 4, each = 2)
[1] 1 1 2 2 3 3 1 1 2 2 3 3 1 1 2 2 3 3 1 1 2 2 3 3
sequence(5)
[1] 1 2 3 4 5
sequence(2:5)
[1] 1 2 1 2 3 1 2 3 4 1 2 3 4 5
向量计算
数值向量
5 + c(4,7,17)
[1] 9 12 22
5 * c(4,7,17)
[1] 20 35 85
c(-1,3,-17) + c(4,7,17)
[1] 3 10 0
c(2,4,5)^2
[1] 4 16 25
sqrt(c(2,4,25))
[1] 1.414214 2.000000 5.000000
mean(c(2,4,9))
[1] 5
var(c(2,4,9))
[1] 13
逻辑向量
x <- c(10.4, 5.6, 3.1, 6.4, 21.7)
x>13
[1] FALSE FALSE FALSE FALSE TRUE
逻辑向量可以在普通的运算中被使用,此时它被转化为数字向量, FALSE当做0, TRUE当做1
(x>13) + 1
[1] 1 1 1 1 2
因子向量
将字符向量转换成因子
levels — 表示因子的水平
a <- c(“green”, “blue”, “green”, “yellow”)
factor(a)
[1] green blue green yellow
Levels: blue green yellow
给因子a的水平命名
levels(a) <- c(“low”, “middle”, “high”)
a
[1] “green” “blue” “green” “yellow”
attr(,“levels”)
[1] “low” “middle” “high”
将数值型向量转换成因子
b <- c(1,2,3,1)
factor(b)
[1] 1 2 3 1
Levels: 1 2 3
将字符型因子转换成数值型因子
ff <- factor(c(“A”, “B”, “C”), labels=c(1,2,3))
ff
[1] 1 2 3
Levels: 1 2 3
将数值型因子转换为字符型因子
ff <- factor(1:3, labels=c (“A”, “B”, " C "))
ff
[1] A B C
Levels: A B C
gl(k, n, label, length)产生规则的因子序列
k — 水平数
n — 每个水平重复的次数
label — 指定每个水平因子的名称(可选)
length — 指定产生数据的个数(可选)
gl(2, 3, label=c (“Male”, “Female”),length=10)
[1] Male Male Male Female Female Female Male Male Male Female
Levels: Male Female
向量运算的循环法则
1:2+1:4
[1] 2 4 4 6
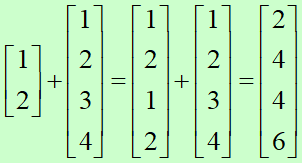
1:4+1:7
[1] 2 4 6 8 6 8 10
Warning message:
In 1:4 + 1:7 : 长的对象长度不是短的对象长度的整倍数

向量的下标与向量子集(元素)的提取
正的下标 —— 提取向量中对应的元素
负的下标 ——去掉向量中对应的元素
逻辑运算 —— 提取向量中元素的值满足条件的元素
注:R中向量的下标从1开始,这与通常的统计或数学软件一致
x <- c(42, 7, 64, 9)
x[1]
[1] 42
x[c(2,4)]
[1] 7 9
x[-2]
[1] 42 64 9
x > 10 #值大于10的元素逻辑值
[1] TRUE FALSE TRUE FALSE
x[x>10] #值大于10的元素
[1] 42 64
x[x<40&x>10]
numeric(0)
产生(0,1)上10个服从均匀分布的随机数
y <- runif(10, min=0, max=1)
y
[1] 0.6215151 0.8524313 0.5984349 0.5263928 0.2448307 0.5444761 0.5032350
[8] 0.8018147 0.7914064 0.7655385
sum(y<0.5) #值小于0.5的元素的个数
[1] 1
length(y[y<0.5]) #等价于上面
[1] 1
sum(y[y<0.5]) #值小于0.5的元素的值的和
[1] 0.2448307
sd(y[y<0.8]) #值小于0.8的元素构成的样本的标准差
[1] 0.1704212
后续:重要的数据结构——矩阵
