逻辑回归的整体步骤:
step1 :function set(即model)
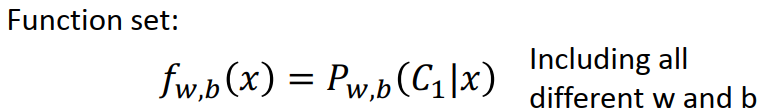
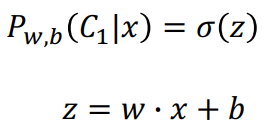
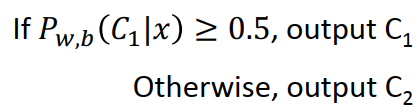
step2: goodness of function:

即评判function好坏的标准(也就是这组w,b好坏的标准)就是这组参数能否使似然函数最大。
用y_hat表示类别:
把原始问题转化成对偶问题: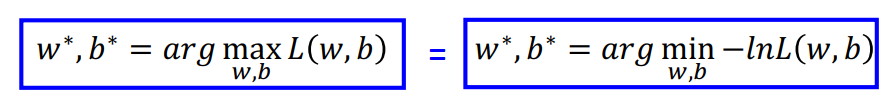

(ps: (1-f(x3))的原因是x3对应的类别是C2)

那么我们的评判标准就转化成:使这个交叉熵越小越好的一组参数,即我们的loss function变成了上面那个交叉熵形式。
step3: find the best function:
那么,我们已经知道的评判标准,如何找到最好的一组参数呢?
依旧是gradient descent,经过计算,得到以下结果
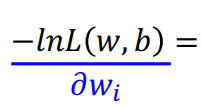
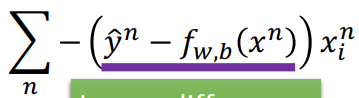
(wi是w矩阵中的某一行,xi是x矩阵中的某一列)
wi的更新如下:
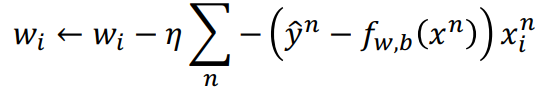
依次对所有wi进行以上操作,那么就完成一次iteration。
以上三步就是logistic regression的整体思路。
逻辑回归与线性回归的区别:

逻辑回归的loss function 不和线性回归一样,使用square error?
若loss function变成square error,则:


如果看cross entropy 和square error的图像更好理解:

可以看出,当w1为3,w2为-4(看图大概是这么多)的时候,两种loss function 都相对于自己的最低值来说是比较大的(说明目前的参数值离最优的参数值还挺远的,在这种情况下,我们希望参数能更新的比较快。(而在参数值接近最优的参数时,我们希望它更新的比较缓慢)),我们的目标是使loss function越小越好,那么就得使w1\w2按照蓝色箭头进行更新,我们可以看到,cross entropy在此时变化的很快,而square error则变化的很慢,说不定它迭代了很多次都还是离最优的参数很远,而cross entropy可能迭代较少次数就比较接近最优解了。
逻辑回归的局限:


可以看出,无论w1,w2,b取什么值,都无法解决黄色表格中的分类问题。
那么如何解决呢?→ 特征转换:

那么完成本例的分类问题的步骤就变成了:

是不是似曾相识???看下面:

因此,我们也可以把深层神经网络看成:前面的layers都是在搞future transformation,最后一层在搞classification。
