一.什么是编码?
-
因为未经压缩的数字视频的数据量巨大,在相对有限的存储空间和传输带宽条件下,其在互联网上的传输会有极大的不便,所以在视频的传输之前,会对视频数据和音频数据进行一定算法的压缩,这个过程又称为编码(压缩)。
-
压缩的实质是去除冗余信息:
a.空间冗余:图像相邻像素之间有较强的相关性
简单讲,同一张图像中,有很多像素点表示的信息是完全一样的,如果对每一个像素进行单独的存储,必然会非常浪费空间,也完全没有必要
如图:

b.时间冗余:视频序列的相邻图像之间内容相似
时间冗余是指多张图像之间,有非常多的相关性,由于一些小运动造成了细小差别。如果对每张图像进行单独的像素存储,在下一张图片中又出现了相同的。那么相当于很多像素都存储了多份,必然会非常浪费空间,也是完全没有必要的。
如图:

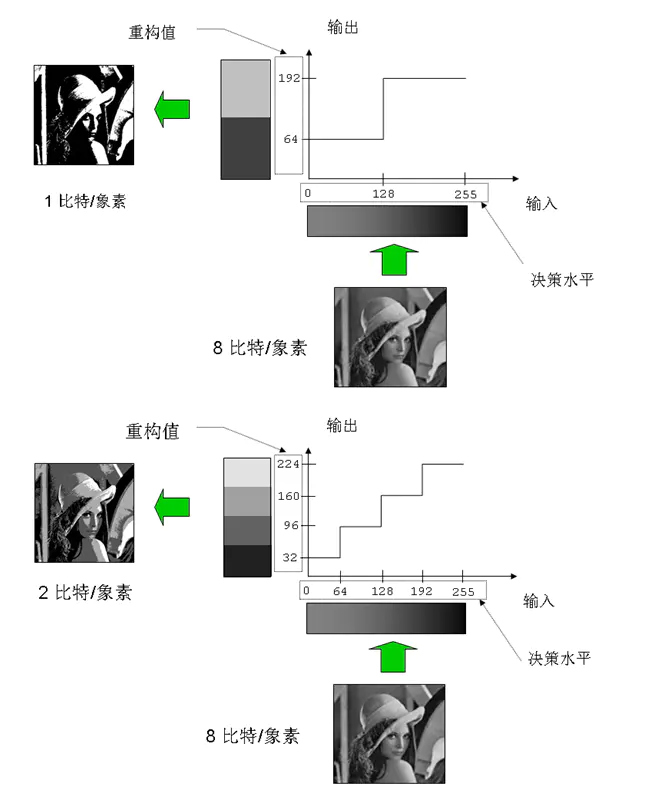
c.编码冗余(信息熵冗余):如果一个图像的灰度级编码使用了多于实际需要的编码符号,就称该图像包含了编码冗余。编码时一般不利用概率特性就会产生编码冗余。
如图:

如果上面图像的像素用8位来表示,我们就说该图像存在着编码冗余,因为该图像的像素只有两个灰度,用一位即可表示,多余位数是浪费。
d.视觉冗余:人的视觉系统对某些细节不敏感,例如在高亮度下,人的视觉灵敏度下降,对灰度值的表示就可以粗糙一些。对于太强太弱的声音,如果超出了“阈值”,人们听觉感受也会被掩蔽。利用感官上的这些特性,也可以压缩掉部分数据而不被人们感知(觉察)。
e.结构冗余:在某些场景中,存在着明显的图像分布模式,这种分布模式称为结构。图像中重复出现或相近的纹理结构,结构可以通过特定的算法来生成。例如:方格状的地板,蜂窝,砖墙,草席等等图像结构上存在冗余。已知分布模式,就可以用算法生存图像。

3.编解码器:
编码器:压缩信号的设备或程序
解码器:解压缩信号的设备或程序
编解码器:编解码器对
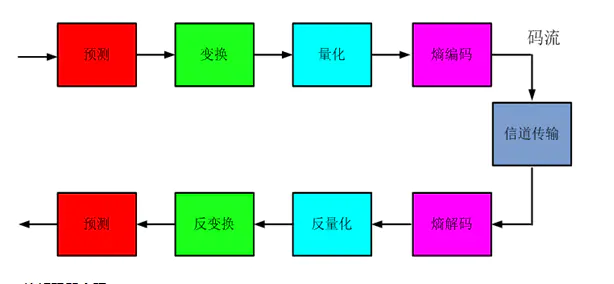
4.压缩系统的组成
- 编码器中的关键技术
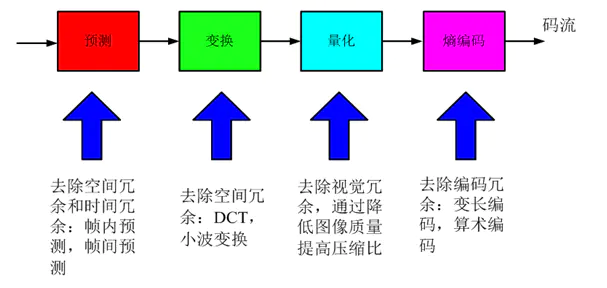
- 编解码中的关键技术
二.编码发展史:
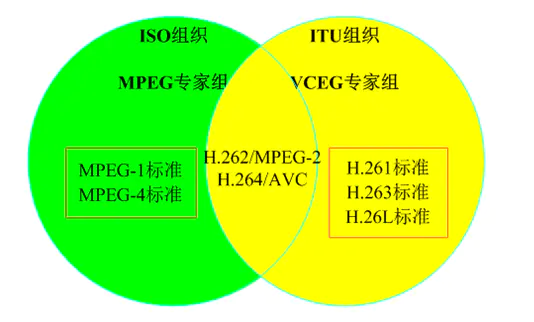
视频编码标准主要有两大系统:MPEG和ITU-T
MPEG标准由MPEG制度:
MPEG-1|MPEG-2|(MPEG-3)|MPEG-4|MPEG-7|MPEG-21
ITU-T标准由VCEG制定:
H.261|(H.262)|H.263|H.263v2|H.264
1984年CCITT通过了H.261视像编码标准,被称为视频压缩编码的一个里程碑。后续一些组织公布的编码标准都基于此。H.261应用于会议电视和可视电话。
1986年,ISO和CCITT成立了联合图像专家组(JPEG,Joint Photographic Experts Group),研究连续色调静止图像压缩算法国际标准,1992年7月通过了JPEG标准。
1988年ISO/IEC信息技术联合委员会成立了活动图像专家组(MPEG,Moving Picture Expert Group)。1991年公布了MPEG-1视频编码标准,码率为1.5Mpbs,主要应用于家用VCD;1994年11月,公布了MPEG-2标准,用于数字视频广播(DVB)、家用DVD的视频压缩以及高清晰度电视(HDTV)。码率从4Mbps、15Mbps…直至100Mbps分别用于不同级别的视频压缩中。
1995年,ITU-T推出了H.263标准,用于低于64Kbps的低码率视频传输,如PSTN信道中可视会议、多媒体通信等等。
1999年12月,ISO/IEC通过了“视听对象的编码标准”——MPEG4,它除了定义视频压缩编码标准外,还强调了多媒体通信的交互性和灵活性。
2003年3月,ITU-T和ISO/IEC正式公布了H.264视频压缩标准,不仅显著提高了压缩比,而且具有良好的网络亲和性,加强了对IP网,移动网的误码和丢包处理。
2013年2月,ITU-T VCEG(Video Coding Experts Group的简称,也直接可称为VCEG,中文可以翻译成视频编码专家组)围绕H.264编码标准,保留了原来的某些技术,同时对一些相关技术进行了改进,提高压缩效率、提高鲁棒性和错误恢复能力、减少实时的时延、减少信道获取时间和随机接入时延、降低复杂度等。
三.编码基本原理:
1.预测编码:
根据图像数据的空间或时间相关性,用已传输的像素对当前正在编码的像素进行预测,然后对预测值与真实值的差——预测误差q,进行编码和传输。这个差值比原始真实值码字要小的多,从而实现视频数据压缩的目的。
接收端把差值q 与预测值(事先已定义好,比当前X 早到达接收端像素,如A)相加,恢复原始值X。归纳如下:
编码端:X-A=q
解码端:q+A=X
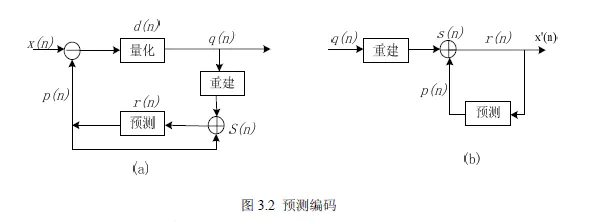
其中,x(n)为当前像素的实际值,p(n)为其预测值,d(n)为差值或残差值。该差值经量化后得到残差量化值q(n)。预测值p(n)经预测器得到,预测器输入为已存储在预测器内前面的各像素,和当前值,它们的加权和即为下一个预测器输出。由图3.2 可见,解码输出x’(n)与原始信号x(n)之间有个因量化而产生的量化误差。
帧内预测编码(空间冗余):当前像素X(设为立即传送的像素)可用前一个像素a 或b、c,或三者的线性加权来预测。这些a,b,c 被称为参考像素。在实际传送时,把实际像素X(当前值)和参考像素(预测值)相减,简单起见传送X-a,到了接收端再把(X-a)+a=X,由于a 是已传送的(在接收端被存储),于是得到当前值。由于X 与a 相似,(X-a)值很小,视频信号被压缩,这种压缩方式称为帧内预测编码。
帧间预测编码(时间冗余):参照一段时间内图像的统计结果表明,在相邻几幅图像画面中,一般有差别的像素只有10%以内的点,亮度差值变化不超过2%,而色度差值的变化只有1%以内。所以对于一段变化不大图像画面,我们可以先编码出一个完整的图像帧A,随后的B帧就不编码全部图像,只写入与A帧的差别,这样B帧的大小就只有完整帧的1/10或更小!B帧之后的C帧如果变化不大,我们可以继续以参考B的方式编码C帧,这样循环下去。这段图像我们称为一个GOP(GOP就是有相同特点的一段数据),当某个图像与之前的图像变化很大,无法参考前面的帧来生成,那我们就结束上一个GOP,开始下一段GOP,也就是对这个图像生成一个完整帧A1,随后的图像就参考A1生成,只写入与A1的差别内容,循环往复。
运动估计与运动补偿:运动估计是寻找当前编码的块在已编码图像(称为参考帧)中的最佳对应块,并且计算出对应块的偏移(即运动矢量)。假设当前帧为P,参考帧为Pr,当前编码块为B,在Pr中寻找与B块相减残差最小的块Br,Br称为B的最佳匹配块,这个过程即为运动估计。
运动矢量和经过运动匹配后得到的预测误差共同发送到解码端,在解码端按照运动矢量指明的位置,从已经解码的邻近参考帧图像中找到相应的块或宏块,和预测误差相加后就得到了块或宏块在当前帧中的位置。通过运动估计可以去除帧间冗余度,使得视频传输的比特数大为减少,因此,运动估计是视频压缩处理系统中的一个重要组成部分。
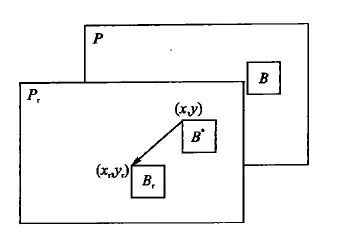
如上图所示,B与B在图像中的坐标位置相同,运动矢量(MV,Montion Vector)就是Br左上角坐标(xr,yr)减去B左上角坐标(x,y)等于(xr-x,yr-y)。Br块就是B块的参考块,Br的像素值就作为B块像素的预测值。
运动补偿则是根据运动矢量和帧间预测方法,球的当前帧的估计值的过程。它是对当前图像的描述,旨在说明当前图像的每一块像素如何由参考图像的像素块得到。


2.变换编码
大量统计表明,视频信号中包含着能量上占大部分的直流和低频成分,即图像的平坦部分,也有少量的高频成分,即图像的细节。因此,可以用另一种方法进行视频编码,将空间信号的能力集中到频域的一小部分低频系数,能量小的系数可通过量化去除,而不会严重影响重构图像的质量。将图像经过某种数学变换后,得到变换域中的图像(如下图),其中u,v 分别是空间频率坐标。如图所示,用“o”表示的低频和直流占图像能量中的大部分,而高频成分(用“×”表示)则是少量的,于是可用较少的码表示直流低频以及高频,而“O”则不必用码,结果完成了压缩编码。
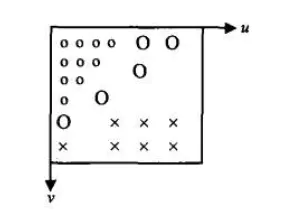
变换域思想
3.量化
所谓量化就是将含有大量的数据集合映射到含有少量的数据集合中。
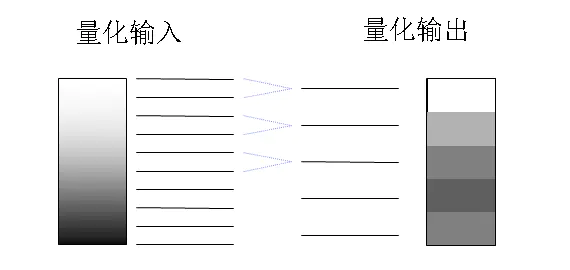
4.熵编码
熵编码是一种无损压缩,熵指的是失帧的程度,它的基本思想是这样的,比如一幅512×512像素的图素,每个像素值用一个字节表示,分析每个像素值出现的概率,把出现的概率大的值用少于一个字节的字符表示,而把出现概率小的值用多余一个字节的字符表示。这样平均每个像素所占的位数就少于一个字节,从而达到压缩数据的目的。比如我们常用的电报码,先对26个英文字母进行出现的概率进行统计,认为E字母出现的概率最大,Z字母出现的概率最小。则在发电报的时候代表E的是点击最短的一个“.”,代表Z的是其中点击最长的“–”
链接:https://www.jianshu.com/p/ce811007e8a9
