awk:
echo "hello-kitty-red-for-you" |awk -F '-for' '{print $1}' //此时-F指定的-for为纯粹的字符串
echo "hello-kitty-red-for-you" |awk -F '[-for]' '{print $1}' //此时-F指定的[-for]就不仅仅是某个字符串了,此时会以-或f或o或r分割字符串,o首先出现在字符串中,那么就会以o为分割线对字符串进行分割
awk -F: '$1=="hello" {print $0}' test.txt #以:为分隔符,找到第一段字符为hello字符的行 输出该行
注意:print $0表示输出整行,print $1表示输出第一列
cat list
输出
pic/kNWHXc_1570779181_15064.jpg
pic/kNWHXc_1570779184_17876.jpg```
awk -F / '{print $1,$2}' list
输出
pic kNWHXc_1570779196_34893.jpg
pic kNWHXc_1570779181_15064.jpg
cut:
-d 指定分割字符
-c和-b 提取字节,-b可以用来提取一个中文字符,-c不可以,优选用-b
-f 指定提取部分
cat log
输出
!
以“:”为分隔符,显示第一列和第二列
cut -d : -f 1-2 log
或者
cat log | cut -d: -f1,2
输出:
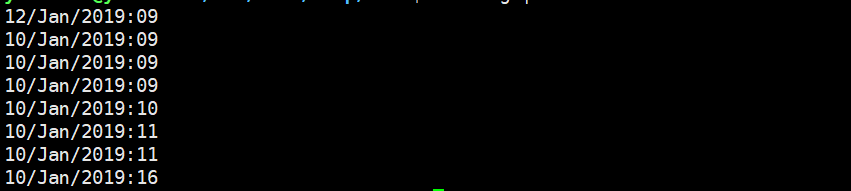
提取部分字符
cut -b 1-2,7,8-11 log

sort
sort 1vN_result.csv -t ',' -k 4 > newsort.list # 将1vN_result.csv中内容按照某一列进行升序排列;
-t 表示按照某个字符分隔;-k 表示按照第几个字段排序
uniq
注意:调用uniq 之前,常常会先调用 sort ,因为 uniq 只对相邻的行去掉重复
cat log-1
输出
sort log-1 | uniq
输出

sort log-1 | uniq -c
输出

seed
cat log
输出
12/Jan/2019:09:10:12
10/Jan/2019:09:13:39
10/Jan/2019:09:15:41
10/Jan/2019:09:40:45
10/Jan/2019:10:22:32
10/Jan/2019:11:24:22
10/Jan/2019:11:24:49
10/Jan/2019:16:55:23
sed 's/:/-/g' log
输出
12/Jan/2019-09-10-12
10/Jan/2019-09-13-39
10/Jan/2019-09-15-41
10/Jan/2019-09-40-45
10/Jan/2019-10-22-32
10/Jan/2019-11-24-22
10/Jan/2019-11-24-49
10/Jan/2019-16-55-23
