定义
- 使用
"或者'定义的内容,表示文本的内容称为字符串
例:'hello' "world" - 没有单个字符的概念,只有单个字符也是作为一个字符串使用
A - 可以参与for循环遍历
- 数据是不可以修改的,也就是不能重新针对某个索引进行再赋值.
- 输出顺序不乱,均为原样输出,
单引号/双引号
- 单引号/双引号都可以定义
- 但是如果希望输出单引号或者双引号,需要交叉使用
"'hh'11"
print('hello')
print("world")
print("hi'china'")
print('china"hi"')
字符串索引
- 索引从左到右从
0开始,从右到左-1开始 - 可以通过索引获取字符串中的内容
str[n] n表示下标索引,即通过[]来截取字符串 - 关于索引下标:
索引下标只能为整数,不能为复数(就算复数结果是整数也不行,不能是字符串,这里的整数包含正整数和负整数,取值的方向不同,正整数从左到右取值,负整数从右到左取值)
str1 = "hello python"
print(str1[6])#p
for val1 in str1:
print(val1) # 每个字符都输出
data1=('0123456789')
print(data1[2],data1[3])# 2 3
print(data1[1:5]) #左闭右开取值,左边能取值,右边不行
#print(data1[1.1]) #如果是小数呢 字符串索引必须是整数 TypeError: string indices must be integers
#print(data1[1.1:5]) #slice indices must be integers or None or have an __index__ method
# 分片的索引要为整数或者是Nonr,或者是能够获取整数的方法
#print(data1[]) SyntaxError: invalid syntax 非法语句 所以一定要索引
#print(data1['1']) must be integers
#print(data1('1')) 不能这样 str 不能被系统调用 其实就是调用的方式错误
#0123456789
#如果是负数 默认从左向右索引,0开始;如果是从右往左,索引从-1开始
字符串截取
- 字符串截取格式
[start:end],取值范围左闭右开原则,也就是start的值能够获取,但是end的值不取。 - 索引从
-1开始 就是表示从末尾开始取。如果end的取值大于字符串的长度,那么是到字符串最后一个位置为止;一旦start>=end输出为空 end > start, 索引的定义要满足这条规律,取值范围都是左闭右开,输出顺序不乱,原样输出;如果相反,则会导致输出为空。- 不定义start取值,默认从
0开始;不定义end值,默认到-1结束,均不定义则全部输出,当然全部输出可以直接使用变量啦 - 索引的取值要符合规范哦,不能小数、字符串等
- sub可以是一个变量,sub=xxxx,
#data1[start:end] end>start 末尾索引要大于起始 同样左闭右开
print(data1[-1])#9
print(data1[-2]) #8
print(data1[-3:-1])#78
#print(data1[-2:-4]) No
print(data1[0:]) # end省略,默认到最后的数据
print(data1[:2])# start省略,默认从第一个开始
print(data1[:]) #全部输出
print(data1[1:-2]) # 到-2截至
#print(data1[3+4j:7]) 这样也不行
字符串切片进阶
str[start:end:step]- step 步长要满足索引的条件,只能是正负整数
- 取值方法:
先将数据进行分割,分割线的后一位就是取值:01 23 45 所以取值就是024 - step为正数为正向截取,step为负数为逆向截取,【逆向截取要在逆向截取的时候使用,即start,end都为负数,否则输出为空】
- 步长太大怎么办,步长负数、小数怎么办
- 其实start/和end是用来划分字符串的长度,step是从中截取,所以分两步理解会快一些
step1 = '0123456789'
print(step1[0::1])#0123456789 ??下标零开始截取一个,再截取的位置又算重新开始?
print(step1[0::2]) #02468 再截取的后一个就是取值 01 23 45 67 89
print(step1[0::3])#012 345 678 9 # 0369
print(step1[0::4]) #0123 4567 89 048
print(step1[0:3:2]) # 3 表示最后一个不取 012-- 01 2-- 02
print(step1[0:3:3])#0
print(step1[0:3:4]) #0 分割的第一位永远会取道 相当于是一个的结束 也是另一个的开始
print(step1[0:3:-1]) # 无输出
#rint(step1[-2:-4])
print(step1[-4:-2:1])#67 -4 -2--- 67
print(step1[-2:-4:-1])#87 -2 -4 这样顺序不一样 -2可以取 -4不行 所以是87
# 1 是正向截取
print(step1[-2:-4:1])# 输出为空
#print(step1[-2:-4:-1.1])
print(step1[::-1])# 逆向输出
step2='中国'
print(step2[::-1])#国中
#print(str[9:0:-1]) # 逆序截取,起始值为列表的第10为数,到列表第1位数之前的数结束, #987654321
print(step1[1:3])#12
print(step1[-1:-3]) # 确实是不行的 因为顺序反了
print("?")
print(step1[3:1]) #空格
print('?')
字符串str数据的更新
- 字符串是不可变数据,不能够通过索引的方式改变数据(
str object does not support item assignment) - 可以重新定义变量的内容,这个不是str的更新改变,应该叫做变量的赋值
- 能够进行拼接,只要能够获取到字符串就能够进行拼接
- 字符串数据是不能计算的,只能够拼接
+或者重复输出*
updata = 'testupdata'
print(updata)
updata='another'
print(updata) #another
print(updata+'111')#another111
updata[1]=2 # str object does not support item assignment
# 不支持索引改变数据内容
print(updata)
#拼接
# 也能够进行拼接
print('yes'+'haha') #yeshaha
#print(data2[3]+1) str拼接只能是str 不能int
#print(data1[1]+1) # 不能计算 因为str + 只能拼接 并且只能** 数字也不行 除非类型转换
print(int(data1[1])+2)#3
print(data2[3]+'ddd')#ddd
print(data2[:3]+'sb') #abcsb #截取就能凭借
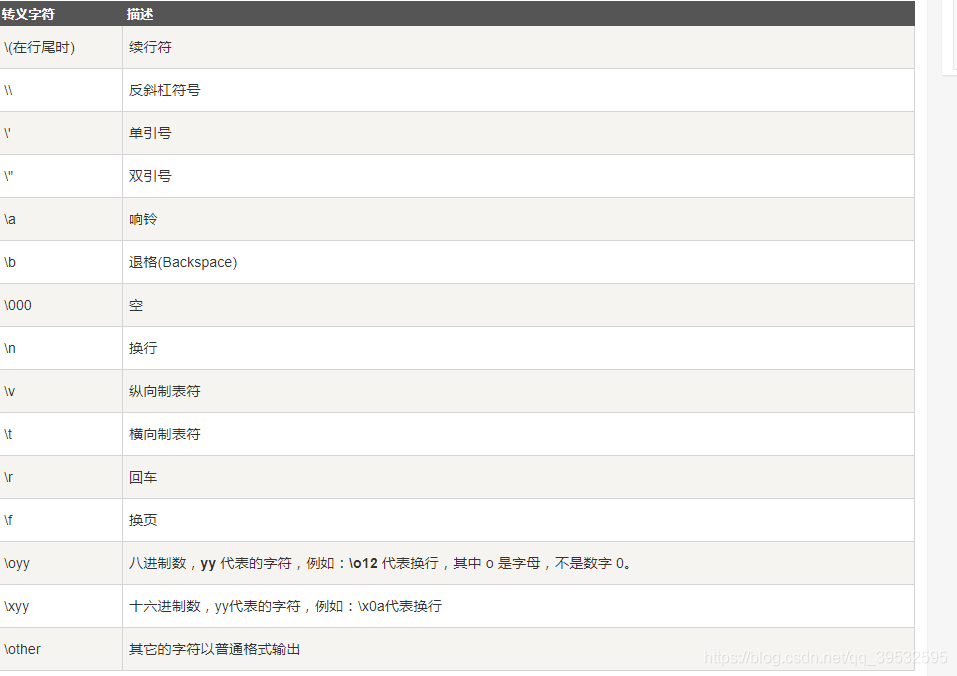
转义字符
\a响铃转义,使用pycharm/ipython3,都不能实现,百度说缺少蜂鸣器,也就是开机声,查询无果,有知道的小伙伴给我说一下呀~\b回退光标一位,也表示删除一个数据的意思\r回车,表示将光标的位置回退到本行的开头位置 也就是之前的不算\000其实表示的是空格- 有写不知道什么用,就不管了哈哈哈~比如下面的图!
#转义字符:
print('\\')#\
print('hell\
hejs') #续行 也就是不换行操作
print('\'') #'
print('\"')#"
print('\a')# 响铃 只输出
"""
是ASCII中的响铃字符,但如何显示这个字符是控制台管理程序自己决定的,
Windows下的CMD和Linux下的各种终端一般都回很规矩的把这个字符“显示”
成一声铃响,但不幸的是,IDLE的“控制台”是它自己实现的,
它决定把这个字符显示成一个方块,所以你在IDLE里只能看到一个方块。
就酱。
而且好像也是需要蜂蜜器响 就是 开机 滴 的声音
我用 ipython3 也不行 算了
"""
print('abc\b') # 删除一个元素 连续才可以 表示将光标的位置回退一位
print('\b',end="??")
print('ab\a')# 还是不行
print('\000he\000llo') # 空的元素 显示的时候是方块 实际上是空格 he llo
print('hi\nhello') # \n 代表换行
print('a''')
print("学号\t姓名\t语文\t数学\t英语")
print("2017001\t曹操\t99\t\t88\t\t0")
print("2017002\t周瑜\t92\t\t45\t\t93")
print("2017008\t黄盖\t77\t\t82\t\t100")
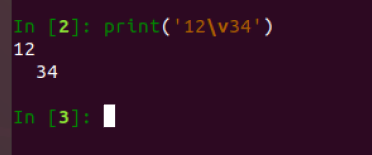
print("学号\v姓名\v语文\v数学\v英语")
print('12\v34') # 在ipython终端能够输出
print('1he\r12') #表示将光标的位置回退到本行的开头位置 也就是之前的不算
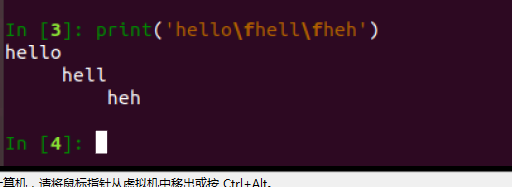
print('hell\fhhh') # 看不明白
print('12\o12 12')
转义字符表格,来源菜鸟教程:
python字符串运算符
+字符串拼接,上诉,不多说了,按拼接顺序输出*z字符串重复输出,str * r
print ('haha'*10)
#print('hh'*1.1) # can't float
#print('hh'*(3+4j)) #can't complex
#print('hh'*'11') can't str
[]通过索引获取字符串中字符,索引只能是整数哦,也不能是1.0这样子的情况,还是属于flaot类型的
f = 'testfloat'
print(f[1.0])
[:]截取字符串,遵顼左闭右开原则,如上所述,不多说了~in/not in成员运算符,如果字符串中包含给定的字符返回True,否则返回False,只有这两种情况;在in运算中,数据必须是按照顺序来进行比对的,哪怕所有的数据在str都含有,顺序不同,也会输出false;#TypeError: 'in <string>' requires string as left operand, not set, 希望是一个左操作数,而不是set类型。
左操作数含义:表达式通常是 a = b;
b可以是一个字面量或者是变量,或者是表达式
在这里 a 就可以说是左操作数,位于等号的左侧就可以说是左操作数
严谨说,左值就是必须有存储结果的地方,有内存空间,
inin ='abcdefg012345678'
print('a' in inin)#True
print('ab' in inin) #true
print('aa'in inin) #false
print('1abc' in inin)# false
print('a1c' in inin) #false
# in 必须是要顺序一样 哪怕顺序乱了 但是内容中有 也是false
# 那么别的数据那些算吗
se = set('123') #TypeError: 'in <string>' requires string as left operand, not set
#print(se in inin)
#print(1 in inin) #false
#print(('1','2','3')in inin) # 左操作数 什么意思
# in 的help输出内容:
The operators "in" and "not in" test for membership.
# in / not in 是测试成员资格
"x in s"evaluates to "True" if *x* is a member of *s*, and "False" otherwise.
# 如果x 是s的成员,就会返回true,否则返回false
"x not in s" returns the negation of "x in s".
# not in 是对 in 的否定
# 此处省略很多 后期开专题 因为百度 很多容器类数据都具有这个特点,到时候补充啦~
r/R字符串是否解析转义字符的意思, 添加r/R不区分大小写,添加后转义字符不作用,
print (r'\n') # \n
print (R'\n') #\n
字符串 格式化 %
- print中有详细的格式化
- %g 用于打印数据时,会去掉多余的零,至多保留六位有效数字。
三引号
- 三引号
"""或''' - 在成对的三引号里面,可以填写
html或者sql或者js等乱七八糟可以实现的代码,在特定的模式下就可以使用,比如浏览器~ - 原样输出,空格也是原样输出
# ’‘’ 三引号用法 可以在引号内部写编码或者是代码 这样会进行解析
oneHTml = '''
<hr>
<h3>This is html</h3>
'''
print(oneHTml) # 会显示 在浏览器上面就会变成html代码
f-string 字面量格式化字符串
- 与
%格式化作用类似 ,但是更加的便捷,在使用的时候不用考虑所需数据类型 - 格式
f'{表达式}'注意f 与引号是没有间隔的是直接相连的 - f-string的形式下,能够进行计算,这样就可以边计算边拼接,那么就可以前后端计算拼接,但达到一定情况下进行使用。
- 使用
=来拼接表达式与结果,也就是会将表达式和结果一起输出。
# f-string 格式化
g1 = 'cheer up'
print('%s'%g1) #cheer up
# f-string 以f开头,后面跟着字符串,字符串中表达式用{}包裹,它会将变量或表达式计算后的值替换进去
g2 ='ysy加油'
print((f'{g2}')) # f必须是直接在引号前面 否则不识别
#print(f('{g2}')) 'str' object is not callable 会被识别成一个回调函数
# f'{表达式}' 这种格式 ,表达式可以是外部给 也可以是自定义,让表达式的内容计算完再显示
print(f'{1+2}')#3
print(f'{set("123")}') #{'2'.'1','3'}
w = {"name":'runoob','url':'www.lsjita'}
print(f'{w["name"]}:{w["url"]}') # 所以可以变计算变拼接 那么后面就可以前端拼接什么的
# 不用判断所要格式化的内容到底是什么数据类型
x =1
print(f'{x+1}') #2
print(f'{x+1 = }') # 3.8 版本支持 #x+1 =2
unicode字符串
- 在python2中unicode会使用
u - 在python3中所有的字符串都是unicode字符串
标记点
- str() 会默认输出 ‘’ 空字符串 ,也进一步代表空字符,以及str() 是false的,有关看:False的所包含的数据
print(str())
print('test')
print(bool(str())) #false
字符串内置函数
详情链接 晚点补上
