第二节:爬虫开发网络基本知识
2.1HTTP与HTTPS
1)HTTP
HTTP是一个客户端和服务端之间请求和应答的标准,通常使用TCP协议。通过使用网页浏览器,网络爬虫或者其他工具,客户端发起一个HTTP请求到服务器上指定端口(默认80)。我们称这个客户端为用户代理程序。应答的服务器上存储着一些资源。比如HTML文件和图像。我们称这个应答服务器为源服务器。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器,网关或者隧道。
原始网络七层协议 :OSI
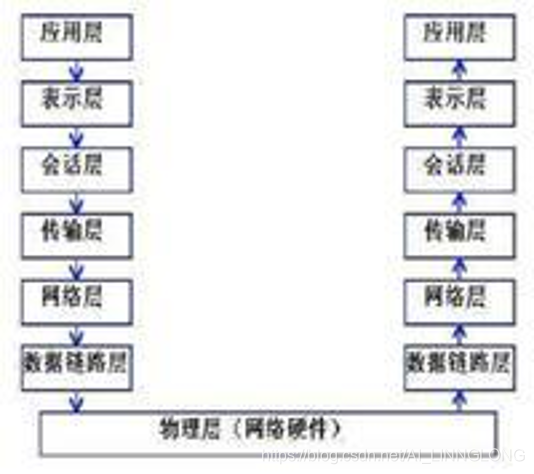
简化为四层划分为:应用层、传输层、网络层、网络接口层 Tcp/Ip模型
应用层
应用程序是指人们用于网络通信的软件程序,
有些终端用户应用程序是网络感知程序,如你运行的app
即这些程序实现应用层协议,并可直接与协议栈的较低层通信。
电子邮件客户程序和 Web 浏览器就属于这种类型的应用程序。
网络层(IP) cmd >>> ipconfig
到网络层,就会进行 IP 的封装,(也就是把你电脑的本地 IP 封装,放在你的数据上,前面加个头说:我是来自192.168.0.1 的电脑,发往百度的 IP 一个是百度的 IP 一个是你自己的IP )之后就会携带着发起请求的目标服务器。(也就是是封装在你的 Get 请求上)
隧道 VPN
网关 加码解码(一般解码)
(类似于,把一个英文网站翻译成中文网站传输回来)
代理
服务器 某些代理服务器
TCP 有连接的流形式,和打电话一样(全双工),我们可以相互交流
并且我知道你会接电话,听到我说话
UDP 面向无连接,不在乎你是否收到了我的信息
就类似于:
发邮件的时候,你知道你的邮件发出去了,但不确定对方能不能收到。
对比 相对来说,UDP 比TCP 简单多。(HTPP 是使用 TCP)
2)HTTP /1.1 方法(重点)
请求类型 代表含义
GET 向指定的资源发出 “显示” 请求,
使用 GET 方法应该只用在读取数据。(请求源代码HTML)
你在浏览器的一次Enter就是一次get,
之所以会看到网页的画面功源于浏览器写的渲染
HEAD 简化版GET,与 GET 方法一样,都是向服务器发出指定资源的请求。
只不过服务器将不传回资源的文本,只会返回Response Headers
因为他返回的数据比较少,多用于服务器开发测试
在前后端交互的时候会使用的比较多,restful——前端与后端相处的接口。
平时我们所说的前后端分离就是 restful)也就是会只返回 Response Headers
POST 向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。
比如你登陆的请求,就是提交数据post的过程。
PUT 注意与POST区分,PUT用于向指定资源位置上传最新内容,用于更新修改。
不是所有程序员都遵守 restful ,有些程序员图省事,将所有请求都用 get 所有发送表单都用 POST ,并不是不可以,只不过尽量遵守编写规范
DELETE 请求服务器删除 Requests-URL 所标识的资源。
TRACE 相当于ping,回显服务器收到的请求
主要用于测试或诊断,测试能不能与服务器联通,
OPTIONS 这个方法可使服务器传回该资源的所支持的所有 HTTP 请求方法。
一般返回Get、Head、Post、Delete、Put
即支持你使用什么方法去访问该网站
注意:一些之前建立的网站可能会出错
CONNECT HTTP/1.1 协议中预留给能够连接改为管道方式的代理服务器。
PATCH 比PUT更轻量,用于将局部修改应用到资源,比如修改图片上的水印
普及知识:
在cmd里输入nslookup,并且输入百度的网址
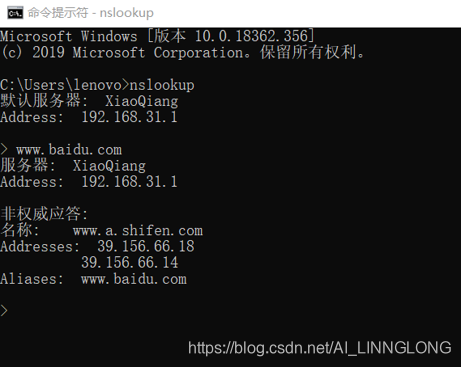
里面的 IP 都是百度的 IP 地址,都可以跳转到百度
一般,你在浏览器发起的GET 请求,就是在我们的计算机内部执行了一下:nslookup 访问地址,通过 DNS 返回地址来( IP 地址),之后再访问这个 IP 地址。
我们服务器用的都是 IP 地址,是不用域名服务的 。所以使用 DNS 来解析一下对应的 IP 地址并进行 访问 ,DNS 解析之后的域名本质上就是是IP 地址 加上 80 端口
非权威应答: 就是说,我们不保证这个是安全的,中间有可能受到黑客的攻击。我们看到的这个东西,有可能受到黑客篡改。
3)https
超文本传输安全协议(HTTPS)是一种通过计算机网络进行安全通信的传输协议。HTTPS经由HTTP进行通信,但利用SSL/TLS来加密数据包。HTTPS开发的主要目的是提供对网站服务器的身份认证,保护交换数据的隐私与完整性。HTTPS由网景公司在1994年首次提出,随后扩展到互联网上。
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
小辨别方法:网页显示不安全就是http传输,否则就是https传输
HTTPS和HTTP的区别主要如下:
1)费用:https协议需要到CA申请证书,一般免费证书较少,因而需要一定费用。
2)安全性:http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议,http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
3)端口:http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。 :80/:443
4)资源消耗:HTTPS需要很多计算,消耗过量的CPU
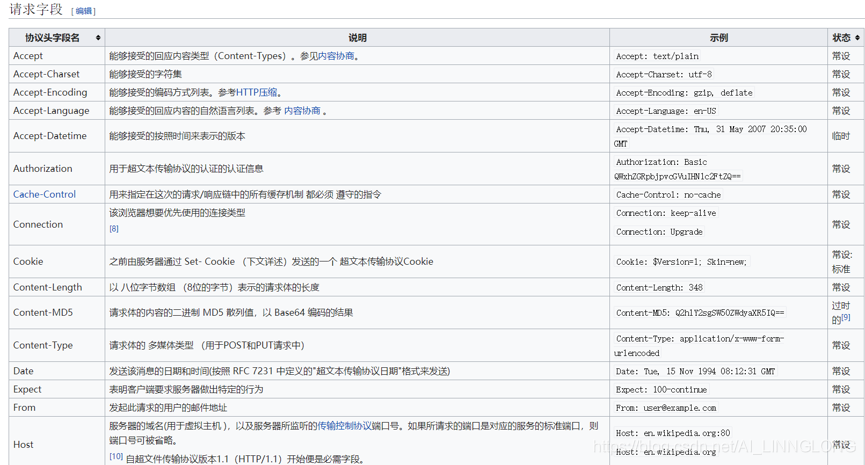
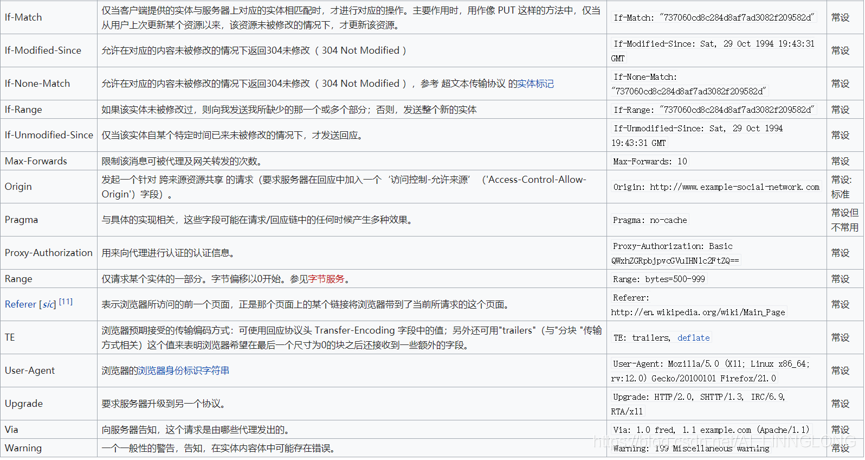
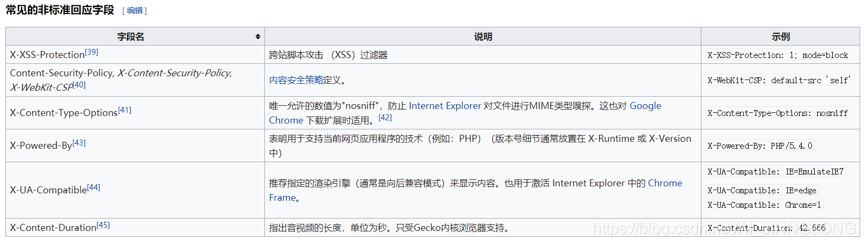
2.2请求头 Headers
HTTP头字段是指在超文本传输协议(HTTP)的请求和响应消息中的消息头部分。它们定义了一个超文本传输协议事务中的操作参数。
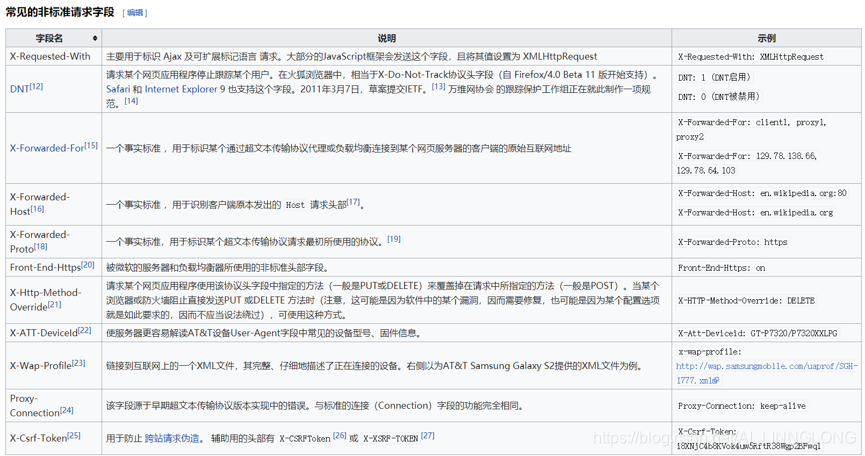
HTTPS头部字段可以自己根据需要定义,因此可能在Web服务器和浏览器上发现非标准的头字段。
查看请求头的方式:
在浏览器中右键选择审查元素(检查),会出现如下页面(这也是之后爬虫最常用的一个操作):
选取菜单栏中的Network,选取Headers:

找到其中的Request Headers:
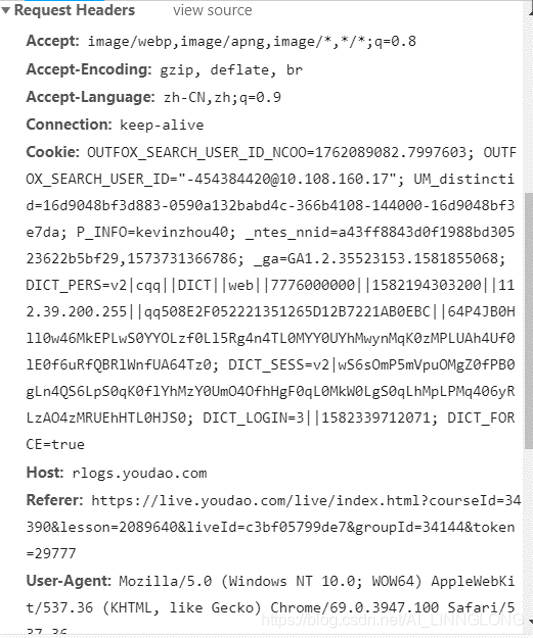
请求头:
Accept:表示客户端会接受的文本
Accept-Encoding:表示客户端可以接受的编码方式
Accept-Language:表示客户端可以接受的语言
Cache-Control:客户端是否使用缓存,使用缓存会节省二次载入时间
Connection:客户端请求连接时长,keep—alive()长连接,如果不采用的话会间隔两次访问,服务器也不知道你从哪里来。
Cookie:保存在客户端本地的可被服务端识别身份的数据
Host:客户端请求的主机
User-Agent:客户端使用什么终端访问
DNT:表示客户端是否允许网站追踪和记录,会分析你的访问,1代表可以追踪
Upgrade-Insecure-Request:表示客户端优先接受加密响应
Program:HTTP1.0用来向后兼容只支持HTTP1.0的缓存服务器
Request URL:我们请求的页面URL
Requests Method:页面的请求方式
Status Code:相应状态码
Remote Address:我们访问国内网站使用的IP地址
Referrer Policy:用于过滤Referer内容,这里的意思是当发生降级的时候不传递referer报头
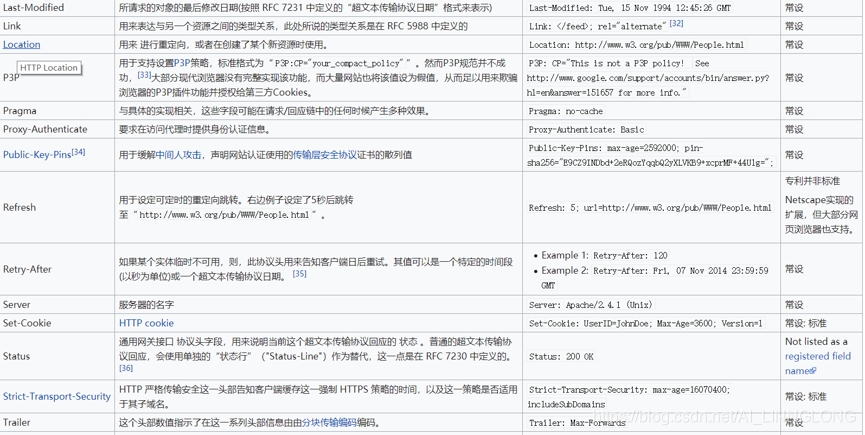
响应头:
Cache-Control:服务器指定缓存方式,这里表示代理服务器不能缓存,只能用户缓存
Connection:当前事务结束后是否关闭连接
Content-Encoding:内容编码方式
Content-Type:返回的数据类型
Expires:在此日期之后,相应失效
Server:服务器处理信息的软件信息
Set-Cookie:服务器给客户端设置cookies
Strict-Transport-Security:在这个时间内发起的请求都使用HTTPS
Transfer-Encoding:数据以块的方式发送
扩展内容:

- HTTP 请求流程
HTTP请求的7个步骤
1,建立TCP连接(输入url之后,三次握手,四次挥手等)
2,浏览器发送请求
3,浏览器发送请求头
4,服务器发送应答
5,服务器发送应答头
6,服务器发送数据(html等)
7,服务器关闭TCP连接
对于上述我们获取的Request Headers,
有这样的一行:
Accept: image/webp,image/apng,image/*,*/*;q=0.8
如果加在你的请求头里面相应的,就只会返回你要求的响应数据
2) 必备状态码
响应码 对应含义
2xx 以2开头的基本上是没问题的,是可以正常返回数据的。
201 请求一开始创建了
202 请求创建之后,服务器接受了
204 就是返回的这个,没有内容(信息)
206 返回部分信息(一般是返回图片)
有时候我们访问网站的时候,有些图标是模糊不清的
这时候后台就会的发起一个206 的请求,
请求后面的信息,返回清晰图片。
3xx 一般是重定向(有时候,你访问的是另一个网站,跳转另一个网站
301 永久移动
302 暂时移动
4xx 出错啦
401 未验证,
页面需要你登陆,如果直接访问,它就会出现 401 页面
403 IP 被封了,禁止你登陆
404 你有可能路由写错了
405 就是这个页面原本只能用 get 方法来请求
而你却用 Post 的方法来请求,不支持这个方法
提醒你,你是不是写错了
408 请求超时(可能是你服务器的问题,也可能是你的问题)
一般来说:个人问题居多
5xx 服务器崩溃,如网站崩了,网关不支持、没有挂载等
同样是在Headers里 我们可以查看状态码 Status Code:
当然你也可以利用代码来查看状态码,这里我们就先介绍一下常用的Request模块
安装方法:
Windows:pip install requests
Mac:pip3 install requests
如果安装失败或过慢使用:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
查看状态码代码:
import requests
html = requests.get("https://www.2345.com/")
print(html.status_code)
一样可以输出:200
当然我们日常使用都是用在下述的情况:
import requests
html = requests.get("https://www.2345.com/")
if html.status_code == 200:
print("1")
pass
else:
print("2")
2.3Cookies
Cookie 可以翻译为“小甜品,小饼干” ,是存储在你电脑上的一些数据,因为HTTP是面向无连接的,也就是每一个请求和响应都是单独分开的,有时候我们需要保存用户的状态,比如你在网站一直在线,就需要使用cookie记录你的信息,下一次请求时候网站会识别你的本地cookie来验证你的身份。
Cookies以键值对形似存在,也就是key=value。
登陆网站有记住我之类的选项,当你点击 记住我也就是启用 Cookies
缺陷:
1,Cookies 会被附加在每个HTTP请求中,所以无形中增加了流量。
2,由于在HTTP请求中的Cookies是明文传递,所以安全性成问题,除非HTTPS。
3,Cookies的大小限制在4KB左右 ,对于复杂需求来说是不够用的
现在也主要用 Session 之后会写到。
现在开发网站也基本上尽量不用 Cookies ,而用 Session
2.4HTML,CSS,JavaScript
网页三剑客
CSS对于爬虫来说无足轻重,JS只有在破解很难的前端加密时才用到,如果想进阶很高级的爬虫工程师,js还是需要精通的
HTML HTML 是描述网页的语言,(超文本标记语言),并不是编程语言。
CSS CSS 层叠样式表,用来修饰页面。
JavaScript JavaScript 网络脚本语言,用来和用户进行交互。
合集 HTML 就是类似于骨架,CSS 就类似于给 HTML 穿上衣服。
2.5.json
Json是一种轻量级的数据交换格式,一般用来搭建网站API。
Json语法:
数据是键值对
数据由逗号分隔
大括号保存对象
方括号保存数组
{“name”:”python”}就是一个json对象
2.6 Ajax
Ajax 其实是 JS 的升级版,我们都知道异步编程吧,Python 有异步编程,那 JavaScript 肯定也有异步编程。在 JavaScript 中,它的异步编程就是 Ajax。
比如你打开百度图片的页面,你会发现即使你没有刷新页面,图片还是不断的出现,也就是没有一个下限。
Ajax是异步执行js网络请求的意思。一般来说,我们提交一个表单,一旦用户点击submit,浏览器就会刷新一下。Ajax是不让页面刷新,用户依然同留在当前页面,同时后台发出新的请求,收到数据之后,通过js刷新页面,这样用户就感觉自己一直在当前页面,但是数据却可以不断刷新。比如查看百度图片,就可以看到图片不断刷新。
