前几篇,我学习了使用pandas合并两张excel表格,但是通常情况下,可能需要一次性的合并多个表格。现在,首先学习一下,python是如何遍历目录的。
假设有如下目录:
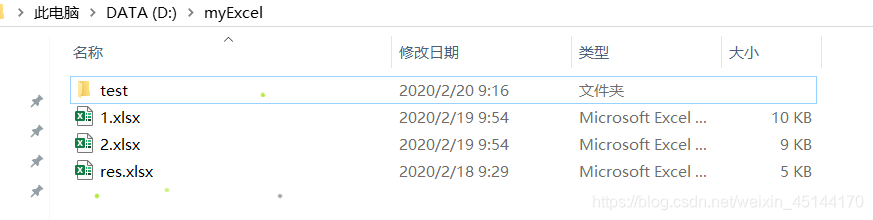
并且在test目录中,还有一个子文件1.txt
1、代码如下:
# 导入os模块
import os
# 调用os.walk()函数,该函数需要传入一个文件目录及需要遍历的目录
# root_dir即每次遍历的根目录,sub_dir根目录下的子目录列表
# files根目录下的文件列表
for root_dir, sub_dir, files in os.walk(r'D:\myExcel'):
print('rootdir->' + str(root_dir))
print('sub_dir->' + str(sub_dir))
print('files->' + str(files))
# 打印结果如下:
# 第一次循环,根目录为D:\myExcel,有一个子目录名字为test,有3个文件
rootdir->D:\myExcel
sub_dir->['test']
files->['1.xlsx', '2.xlsx', 'res.xlsx']
# 第二次循环,把在第一次发现的目录作为根目录,开始遍历
rootdir->D:\myExcel\test
sub_dir->[]
files->['1.txt']
如上所示,os.walk()方法会根据传入参数遍历目录及其每一个子目录,并获取所需要的文件
2、了解了以上os.walk()方法,我们开始定义函数,目标是获取某个目录下的所有
excel文件
import os
# 定义一个函数,函数名字为get_all_excel,需要传入一个目录
def get_all_excel(dir):
file_list = []
for root_dir, sub_dir, files in os.walk(r'' + dir):
# 对文件列表中的每一个文件进行处理,如果文件名字是以‘xlxs’结尾就
# 认定为是一个excel文件,当然这里还可以用其他手段判断,比如你的excel
# 文件名中均包含‘res’,那么if条件可以改写为
# if file.endswith('xlsx') and 'res' in file:
for file in files:
if file.endswith('xlsx'):
# 此处因为要获取文件路径,比如要把D:/myExcel 和res.xlsx拼接为
# D:/myExcel/res.xlsx,因此中间需要添加/。python提供了专门的
# 方法
file_name = os.path.join(root_dir, file)
# 把拼接好的文件目录信息添加到列表中
file_list.append(file_name)
return file_list
# 运行上述函数:
['D:\\myExcel\\1.xlsx', 'D:\\myExcel\\2.xlsx', 'D:\\myExcel\\res.xlsx']
从结果可知,已经把1.txt排除了
哈哈,以上就是python遍历文件的方法,当然还有listFiles方法也可以遍历,这里就不多讲了,如果您有兴趣,欢迎关注我的公众号: python小工具。一起提高办公的自动化效率吧

