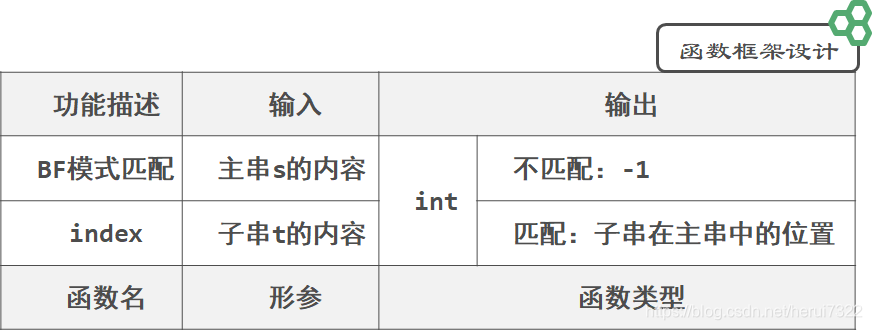
字符串的查找——模式匹配
模式匹配(Pattern Matching):
子串(模式串)在主串(目标串)中的定位运算。

1.BF 算法
Brute-Force(布鲁特-福斯)算法,简称BF算法,又称为朴素匹配算法或蛮力算法。
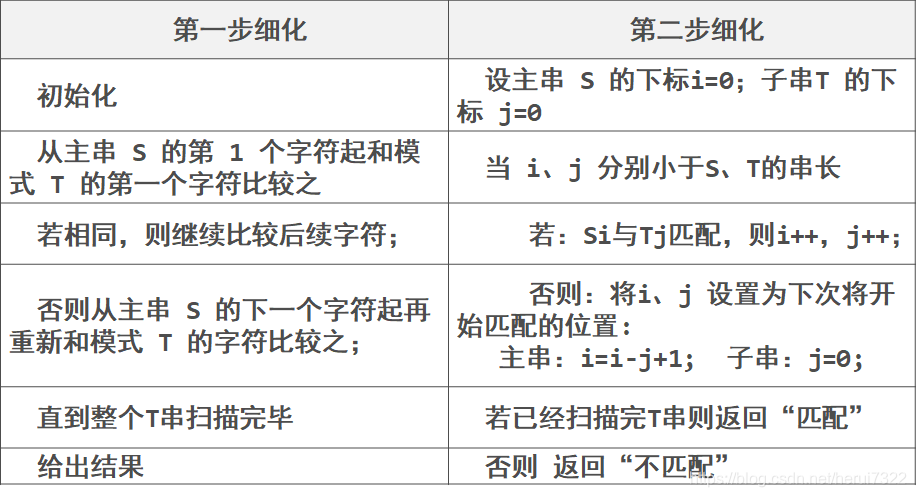
算法思路:将目标串 S 的第一个字符与模式串 T 的第一个字符进行匹配,
若相等,则继续比较 S 的第二个字符和 T 的第二个字符;
否则,比较 S 的第 i( i=i-j+1)字符与 T 的第一个字符,依次比较下去,直到得出最后的匹配结果。 (i 是每次主串结束位置,j 是模式串每次结束位置)
数据结构描述:
#define MaxSize 100
typedef struct
{ char ch[ MaxSize ];
int len;
} SqString;
程序实现:
/*==============================================
函数功能:BF算法-——求模式t在目标串s是否匹配
函数输入:目标串s、模式串t
函数输出:匹配成功:返回模式串t首次在s中出现的位置
匹配不成功:返回-1
================================================*/
int index( SqString s, SqString t )
{ int i=0, j=0, k;
while ( i< s.len && j < t.len ) // i、j在正常范围?
{
if ( s.ch[i] == t.ch [j] ) //字符相等则继续
{
i++; j++; //主串和子串依次匹配下一个字符
}
else //主串、子串指针重置
{
i=i-j+1; //主串从下一个位置开始匹配
j=0; //子串从头开始匹配
}
}
if ( j >= t.len) k=i - t.len; //返回匹配的第一个字符的下标
else k = -1; //模式匹配不成功
return k;
}
关于算法效率分析:
若匹配成功:
最好情况下,平均时间复杂度是 O(N+M);
最坏情况下,平均时间复杂度是 O(M*N)。
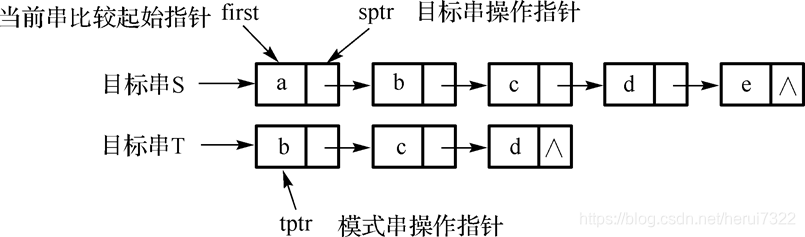
BF算法在链串上的实现
用结点大小为1的单链表做串的存储结构,实现朴素的匹配算法。若匹配成功,则返回有效位移所指的结点地址,否则返回空指针。
数据结构描述:
typedef struct node
{ char ch;
struct node *next;
} LinkString;
程序实现:

/*==============================================
函数功能: BF算法在链串上的实现
函数输入:目标串链表起始地址,模式串链表起始地址
函数输出:匹配点地址
=================================================*/
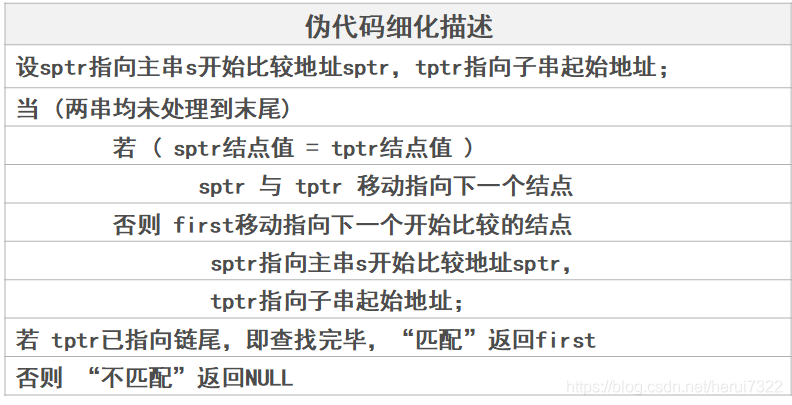
linkstring *IndexL(linkstring *S, linkstring *T)
//S: 目标串 T:模式串
{
linkstring *first, *sptr, *tptr;
first=S; sptr = first; tptr=T; //设置比较地址
while (sptr && tptr) //两串均未处理到末尾
{
if (sptr->data==tptr->data) //两串中字符相等
{ sptr=sptr->next;
tptr=tptr->next;
}
else //两串中字符不等,重新设置比较地址
{ first=first->next;
sptr=first;
tptr=T;
}
}
if (tptr==NULL) return(first); //匹配
else return(NULL); //不匹配
}
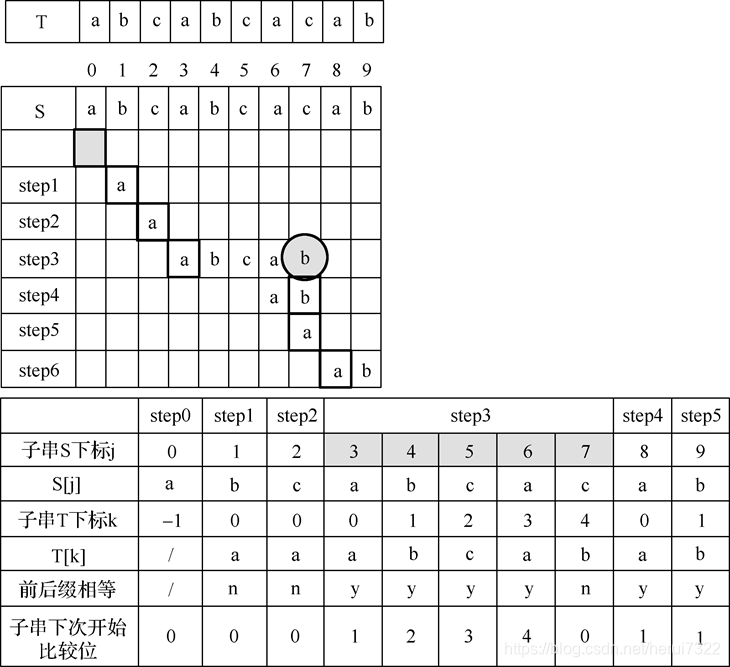
2.KMP算法(无回溯)
算法思想:
设法利用已经得到的“部分匹配”结果,不再把主串的“搜索位置”移回已经比较比较过的位置,而是在此基础之上继续后移,即不回溯主串 s 的位置指针 i,这样提高了搜索效率。
算法关键点:模式串t位置指针j不能每次都从头开始,而是根据“失配”时的位置,决定下一次的开始位置。
个人理解: 由上述思想,不回溯主串指针,而是利用在发生不匹配位置处,其前的后缀与前缀匹配情况,判断下次匹配模式串的位置。
其中求next算法思路:利用 一数组 存储模式串T各个下标与其前缀匹配位置,解决了前缀和后缀匹配情况的问题,具体如下
模式串的next值:

解释:在 j 位置处不相匹配,k 为在 j 前的字符串前缀和后缀所匹配的最大字长;
比如 aab 在 j =2时,k 值为 1 ,前缀只有 a ,后缀只有 a;
主串与模式串比较第一个字符即不等,此时操作为:i++,在j=0开始下一次匹配,
若j !=0 ,又其前缀与后缀无相同字符串,此时操作为:在j=0 开始下一次匹配。
求next算法设计:
规则是——结束位 j 前的串内容其前缀与后缀有 k 位相等(0<k<j),则下一次的开始位为 k。如下图

如j=4时,k的变化从1~3,t0依次要和t1、t2、t3比较:
若t0=t3,则k=1
若t0t1=t2t3,则k=2
若t0t1t2=t1t2t3,则k=3
实际的情形是:
当t0=t1 时,才有可能k=3
当t0=t2 时,才有可能k=2
当t0=t3 时,才有可能k=1
故求next[j]的过程,就是一个在T串中匹配T前缀的过程
next[j]存储其与其前缀发生匹配的位置
图片描述:
计算 next 伪代码描述:

数据结构描述:
#define MaxSize 30
//串结构
typedef struct
{ char ch[MaxSize]; //用数组存储串值
int len;//串长度
} SqString;
程序实现:
/*=======================================
函数功能:由模式串 t 求出 next 的值
函数输入:模式串 t,( next数组)
函数输出:无
=========================================*/
void GetNext( SqString t, int next[ ] )
{ int j=0, k= -1;
next[0] = -1; //置初值
while ( j< t.len ) //在子串的有效范围内
{
//从t的起始位置开始处理或 顺次比较主串与子串
if ( k== -1 || t.ch[j] == t.ch[k])
{
j++; k++;
next[j]=k;
}
//设置重新比较位置:j串不变,k串从next[k]位置起
else k = next[k];
}
}
KMP 伪代码描述:

KMP 算法实现:
/*==============================================
函数功能:KMP算法-——求模式t在目标串s是否匹配
函数输入:目标串s、模式串t
函数输出:匹配成功:返回模式串t首次在s中出现的位置
匹配不成功:返回-1
================================================*/
int KMPIndex(SqString s,SqString t)
{ int next[MaxSize], i=0, j=0, v;
GetNext(t,next); //求出next数组
while ( i<s.len && j< t.len)
{ if ( j==-1 || s.ch[i] == t.ch[j] ) //j=-1 表示首次比较
{ i++;j++; } //i, j各增1
else j=next[j]; //i不变, j后退
}
if ( j >= t.len ) v = i-t.len; //返回匹配模式串的首字符下标
else v = -1; //返回不匹配标志
return v;
}
测试程序:
#include<stdio.h>
#include"Unit3_12.cpp"
int main()
{
SqString S={"ababcabcacbab",13};
SqString T={"abcac",5};
int k;
freopen("datain.txt","r",stdin);
freopen("dataout.txt","w",stdout);
k=KMPIndex(S,T);
printf("\n匹配位置:%d\n",k);
fclose(stdin);
fclose(stdout);
return 0;
}
测试二:
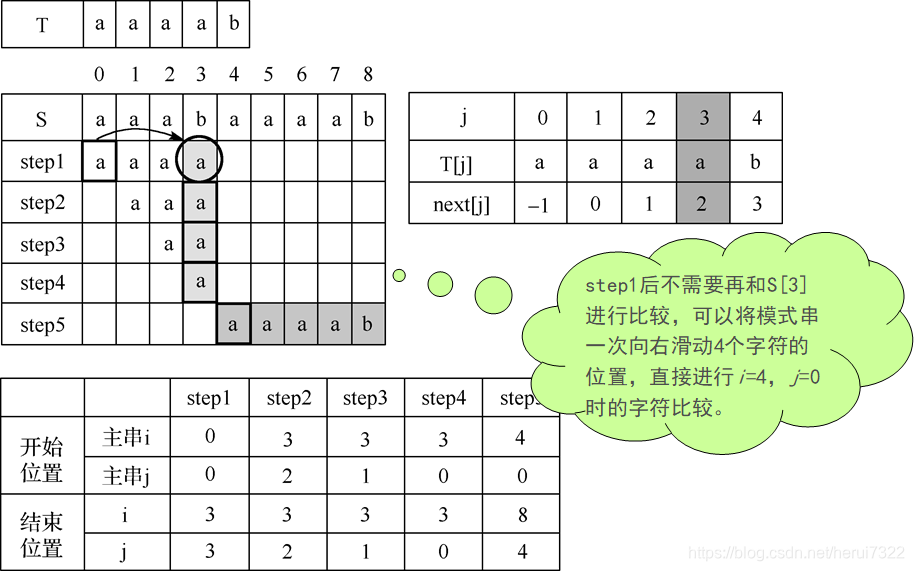
KMP算法中,如何改进重复的比较步骤?
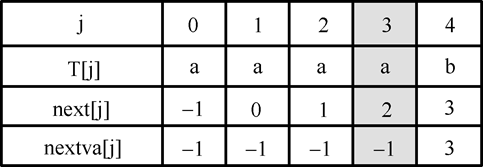
tj =tk 时next[j]置-1
next[j]取值为-1的含义:下一次比较从si+1和t0开始
模式匹配算法效率分析:
KMP算法最大特点:不需要回溯,在匹配过程中,对主串仅需从头至尾扫描一遍,对处理从外部设备输入的庞大文件很有效,可以边读入边匹配,而无须回头重读。
另外还有BM算法(Boyer Moore);多模式匹配算法——AC算法。
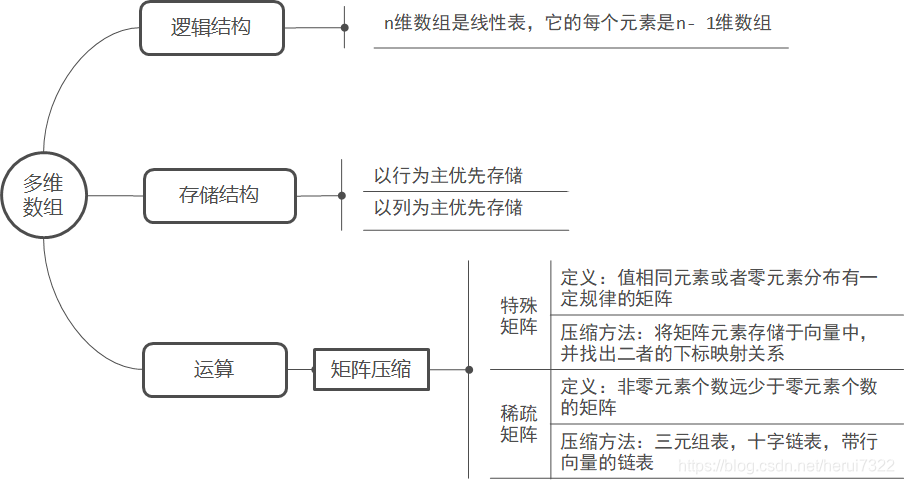
多维数组各概念间的联系:
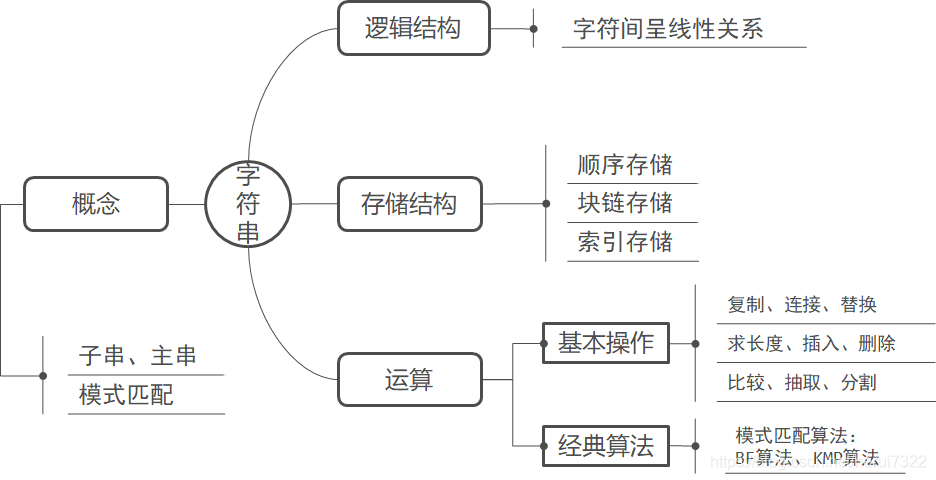
字符串各概念间的联系:
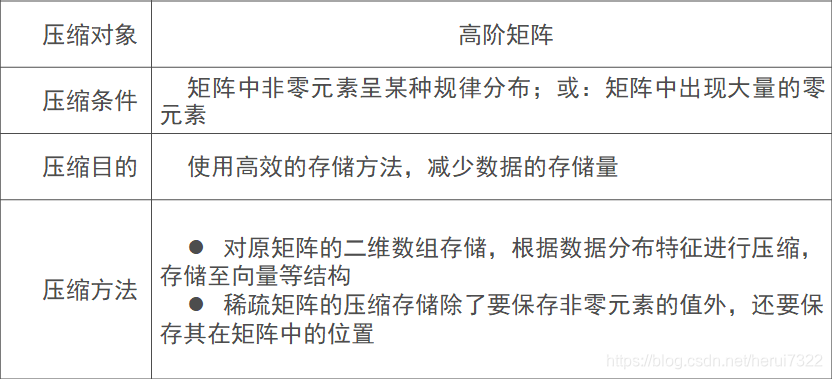
矩阵压缩要点
本章小结
一维数组是线性表结点一对一相连,
M*N二维数组有M行或N列线性表组合阵列。
随机存取说的是每个结点存取时间都一样长短,
特殊矩阵有对称、对角、三角种种有规律包含。
压缩存是把二维的矩阵映射到一维的空间,
行列二下标对一维下标的变换。
稀疏矩阵很特别,是大矩阵非零的元素稀少分布星星点点,
三元组表、行链表、十字链表压缩存储方法有三,
设计思路都是存非零的元素值与位置在哪边。
多个字符连在一起是字符的串,
串结构依然是线性表无二般。
数组或链串存字符各种方案,
求串长、比大小、做连接运算都简单,
唯模式匹配有点难。
匹配是主串里面把子串查看,
BF蛮力法要一个字符一个字符挨个验,
复杂度大欧mn速度有点慢。
KMP不愧是三个臭皮匠凑成诸葛亮,
细观察巧安排主串无回溯,
子串定位继续的点在next表中寻探,
大欧n加m提速果然赞。
(注:二维数组:M行N列 模式匹配:主串长度为n, 子串长度为m)
