前言
package hpsyche.finaltest;
/**
* @author Hpsyche
*/
public class Hello {
public static void main(String[] args) {
String str="haha";
new Thread(() -> System.out.println(str)).start();
}
}
在JDK8之前(为什么jdk8之后不用加,后文会做解释),以上程序会报错,需要在str前加上final
如果我们在匿名内部类中需要访问局部变量,那么这个局部变量必须用final修饰符修饰。这里所说的匿名内部类指的是在外部类的成员方法中定义的内部类。既然是在方法中创建的内部类,必然会在某些业务逻辑中出现访问这个方法的局部变量的需求。那么我们下面就会研究这种情况。
正文
为什么java语法要求我们需要用final修饰呢?想了想没有什么答案,那我们就通过jd-gui反编译工具一探究竟,我们对匿名内部类的字节码文件进行反编译得到以下内容。
package hpsyche.string;
import java.io.PrintStream;
final class Hello$1
extends Thread
{
Hello$1(String paramString) {}
public void run()
{
System.out.println(this.val$str);
}
}
我们可以看到匿名内部类的构造器中传入了一个参数,我们可以推理出这个参数就是底层传入的str的值,但因为反编译工具的某种疏忽将构造器的方法体写成了空,事实上真正的反编译代码应该是下面:
public class Hello$1 extends Thread {
private String val$str;
Hello$1(String paramString) {
this.val$str = paramString;
}
public void run() {
System.out.println(this.val$str);
}
也就是说匿名内部类之所以可以访问局部变量,是因为在底层将这个局部变量的值传入到了匿名内部类中,并且以匿名内部类的成员变量的形式存在,这个值的传递过程是通过匿名内部类的构造器完成的。
那么问题又来了,为什么需要用final修饰局部变量呢?
按照习惯,我依旧先给出问题的答案:用final修饰实际上就是为了保护数据的一致性。
这里所说的数据一致性,对引用变量来说是引用地址的一致性,对基本类型来说就是值的一致性。
final修饰符对变量来说,深层次的理解就是保障变量值的一致性。为什么这么说呢?因为引用类型变量其本质是存入的是一个引用地址,说白了还是一个值(可以理解为内存中的地址值)。用final修饰后,这个这个引用变量的地址值不能改变,所以这个引用变量就无法再指向其它对象了。
回到正题,为什么需要用final保护数据的一致性呢?
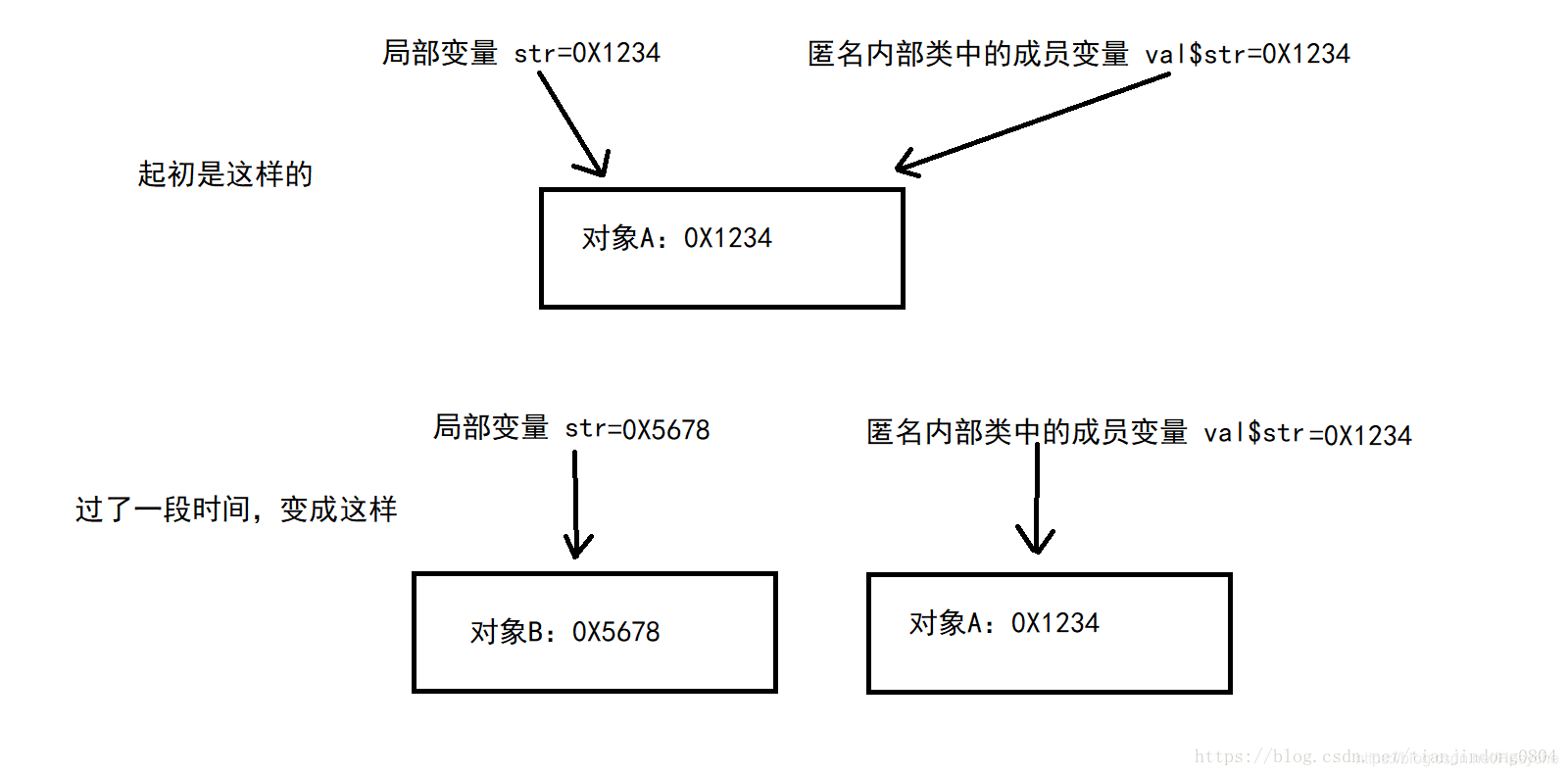
因为将数据拷贝完成后,如果不用final修饰,则原先的局部变量可以发生变化。这里到了问题的核心了,如果局部变量发生变化后,匿名内部类是不知道的(因为他只是拷贝了局部变量的值,并不是直接使用的局部变量)。这里举个栗子:原先局部变量指向的是对象A,在创建匿名内部类后,匿名内部类中的成员变量也指向A对象。但过了一段时间局部变量的值指向另外一个B对象,但此时匿名内部类中还是指向原先的A对象。那么程序再接着运行下去,可能就会导致程序运行的结果与预期不同。
jdk1.8?
在JDK8中更多智能:如果局部变量被匿名内部类访问,那么该局部变量相当于自动使用了final修饰,即如果我们在匿名内部类中需要访问局部变量,那么这个局部变量不需要用final修饰符修饰。看似是一种编译机制的改变,实际上就是一个语法糖(底层还是帮你加了final)。
