花了几天休息的时间整理了这篇文章,就为了让你读完就能深入了解并熟练运用Spark SQL!如果你觉得有用的话请收藏加关注,你的转发和点赞是我最大的动力!原创不易,转载请注明出处!
转自微信公众号: 大数据哔哔机
本文基于Spark官方网站(spark.apache.org),加上自己的理解和实验编写。文中Demo基于Spark2.4。
1、概述
Spark SQL是一个用于结构化数据处理的Spark模块。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了关于数据结构和正在执行的计算的更多信息。在内部,Spark SQL使用这些额外的信息来执行额外的优化。有几种与Spark SQL交互的方法,包括SQL和数据集API。在计算结果时,使用相同的执行引擎,而不依赖于用于表示计算的API/语言。这种统一意味着开发人员可以很容易地在不同的api之间来回切换,这些api提供了最自然的方式来表达给定的转换。
1.1、SQL
Spark SQL的一个用途是执行SQL查询。Spark SQL还可以用于从现有Hive中读取数据。在另一种编程语言中运行SQL时,结果将作为数据集/DataFrame返回。您还可以使用命令行或JDBC/ODBC与SQL接口交互。
1.2、Datasets and DataFrames
Dataset是数据的分布式集合。Dataset是Spark 1.6中添加的新接口,它提供了RDDs(强类型、使用强大lambda函数的能力)和Spark SQL优化执行引擎的优点。可以从JVM对象构造数据集,然后使用功能 transformations (map, flatMap, filter, etc.).进行操作。 Dataset API在Scala和Java中可用。Python不支持 Dataset API。但是由于Python的动态特性, Dataset API的许多优点已经可用(例如,您可以按名称自然地访问行。columnname的字段)。R的情况类似。 DataFrame是组织到命名列中的Dataset 。它在概念上等价于关系数据库中的表或R/Python中的数据框架,但是在底层有更丰富的优化。DataFrames可以从许多数据源构建,例如:结构化数据文件、Hive中的表、外部数据库或现有的rdd。DataFrame API在Scala、Java、Python和r中都可以使用。在Scala和Java中,DataFrame 由行Dataset表示。在Scala API中,DataFrame只是Dataset[Row]的类型别名。而在Java API中,用户需要使用Dataset来表示一个DataFrame。 在整个文档中,我们经常将Scala/Java Datasets of Rows 称为DataFrames。
2、开始入门
2.1、使用SparkSession开始着手
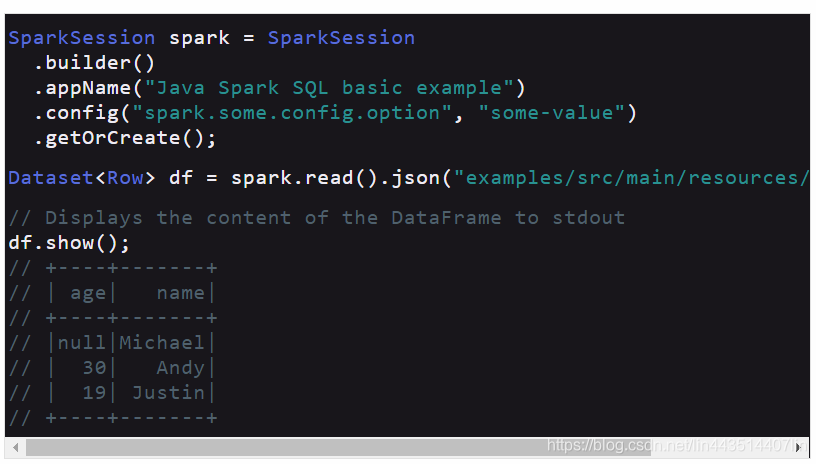
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL basic example")
.config("spark.some.config.option","some-value")
.getOrCreate();
Dataset<Row> df = spark.read().json("examples/src/main/resources/people.json");
// Displays the content of the DataFrame to stdout
df.show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
在上例中,使用sparksession.read.json方法读取一个java文件,并返回一个dataset对象。通过调用dataset的方法可以进行数据的操作。

2.2、非类型化DataSet操作(即DataFrame操作)
DataFrames为Scala、Java、Python和R中的结构化数据操作提供了一种特定于领域的语言。 如上所述,在Spark 2.0中,DataFrames只是Scala和Java API中的行DataSet。与强类型Scala/Java数据集提供的“类型化转换”相比,这些操作也称为“非类型化转换”。 以下是一些使用数据集进行结构化数据处理的基本例子:
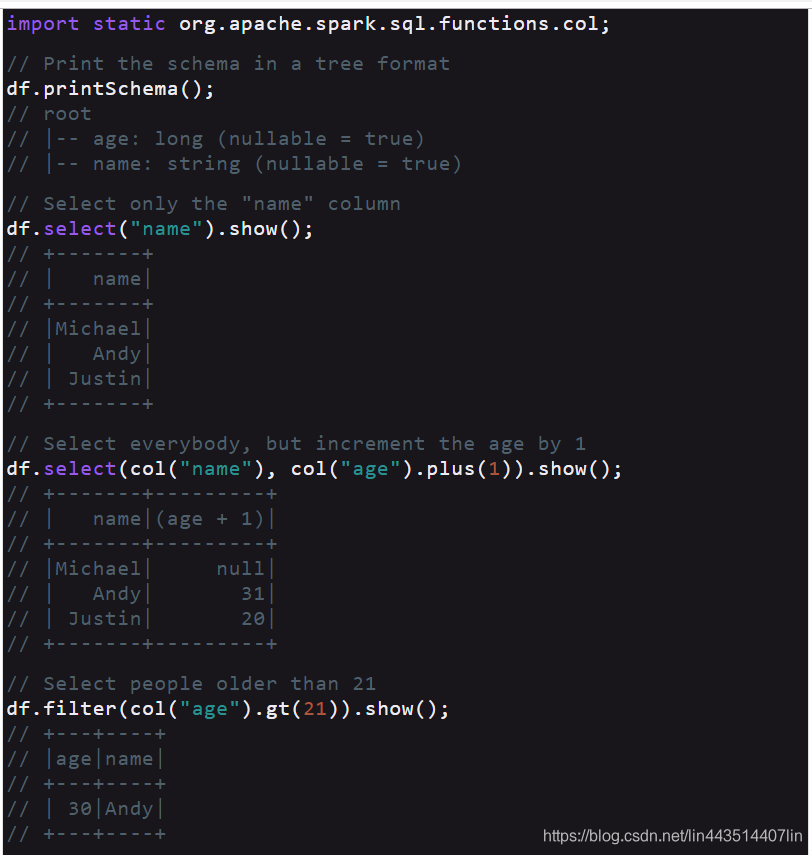
// col("...") is preferable to df.col("...")
import static org.apache.spark.sql.functions.col;
// Print the schema in a tree format
df.printSchema();
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show();
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// Select everybody, but increment the age by 1
df.select(col("name"), col("ageplus(1)).show();
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// Select people older than 21
df.filter(col("age").gt(21)).show();
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
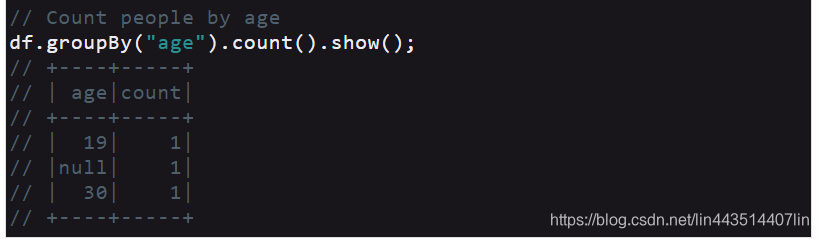
// Count people by age
df.groupBy("age").count().show();
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
除了简单的列引用和表达式外,数据集还具有丰富的函数库,包括字符串操作、日期算法、常见的数学操作等等。完整的列表可以在DataFrame函数引用中获得。(http://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/functions.html)
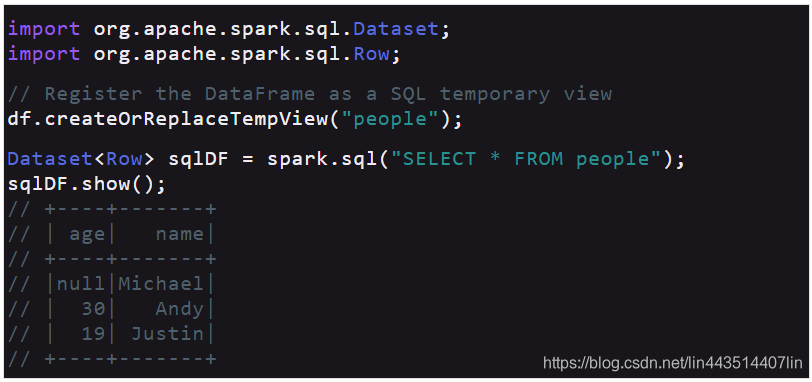
2.3、以编程方式运行SQL查询
SparkSession上的sql函数允许应用程序以编程方式运行sql查询,并以Dataset的形式返回结果。
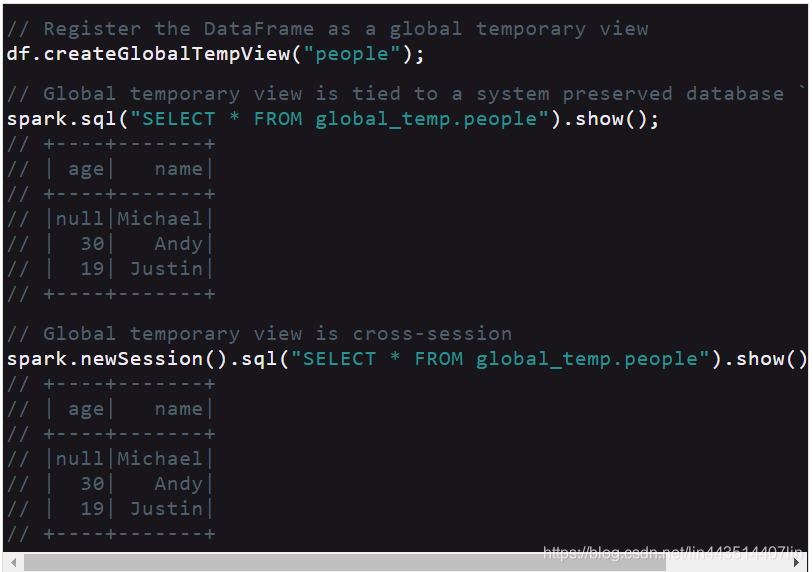
2.4、全局临时视图
Spark SQL中的临时视图是会话范围的,如果创建它的会话终止,它将消失。如果您希望所有会话之间共享一个临时视图,并在Spark应用程序终止之前保持活动状态,那么您可以创建一个全局临时视图。全局临时视图被绑定到系统保存的数据库globaltemp,我们必须使用限定名来引用它,例如,SELECT * FROM globaltemp.view1.
2.5、创建Datasets
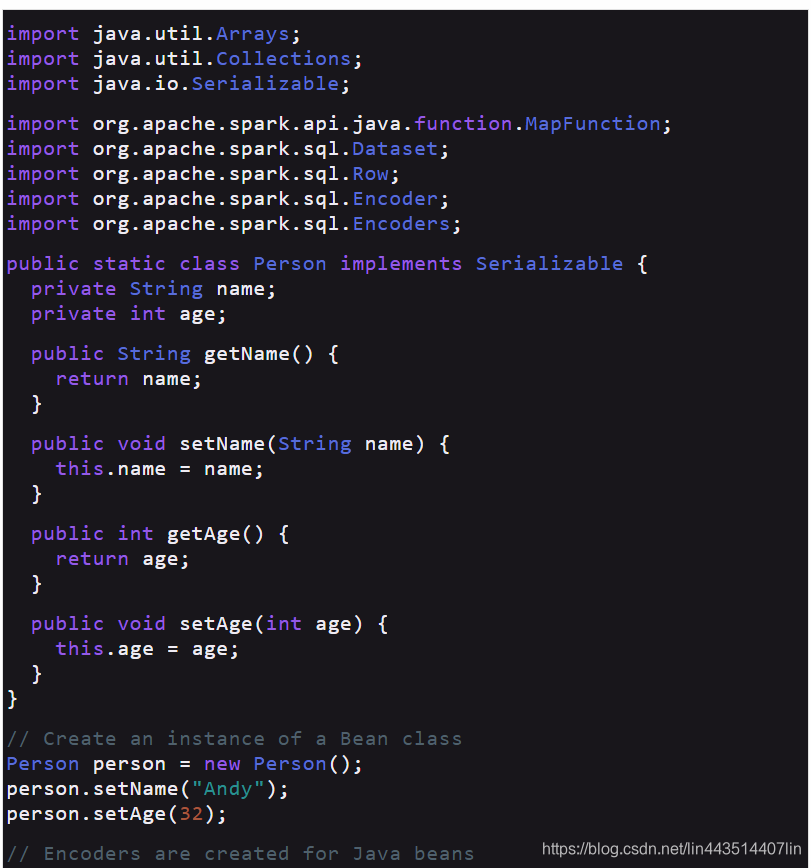
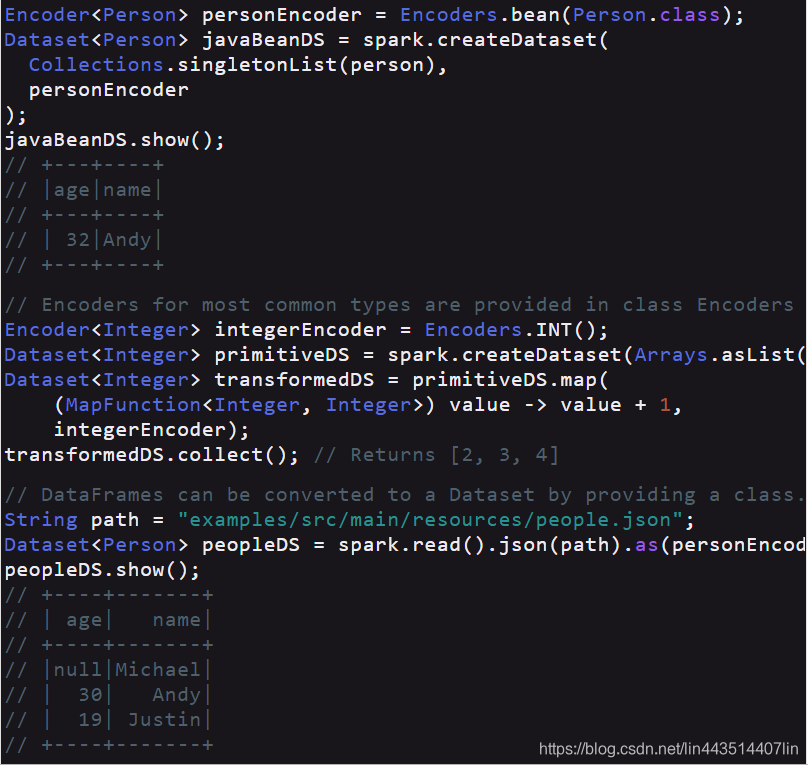
Dataset类似于RDDs,但是,它们不使用Java序列化或Kryo,而是使用专门的编码器序列化对象,以便通过网络进行处理或传输。虽然编码器和标准序列化都负责将对象转换成字节,但编码器是动态生成的代码,使用的格式允许Spark执行许多操作,如过滤、排序和哈希,而无需将字节反序列化回对象。
2.6、进行RDD操作
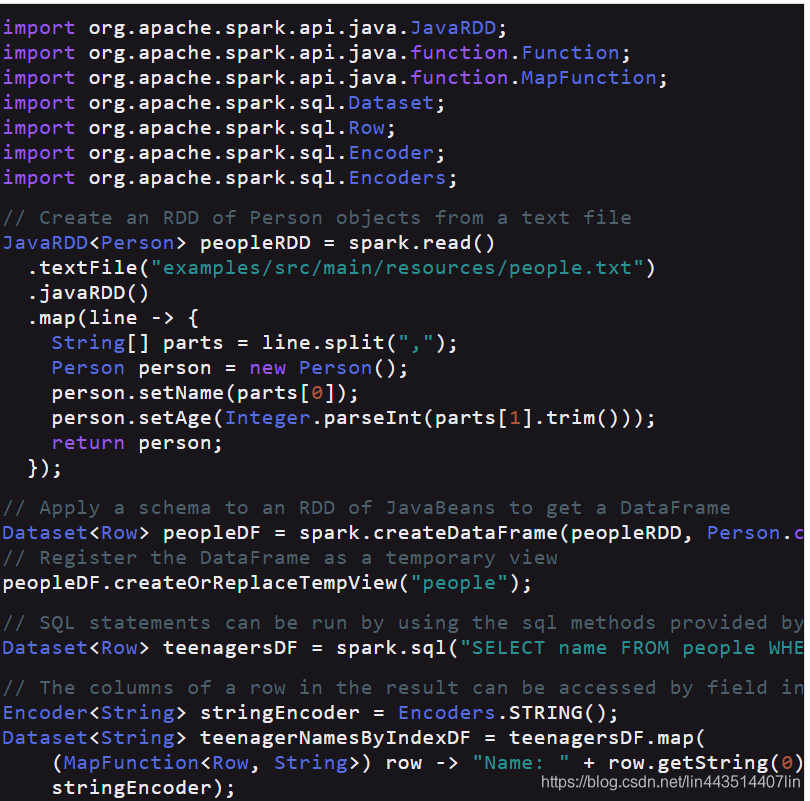
Spark SQL支持两种不同的方法来将现有的RDDs转换为数据集。第一种方法使用反射来推断包含特定类型对象的RDD的模式。这种基于反射的方法可以生成更简洁的代码,并且当您在编写Spark应用程序时已经知道模式时,这种方法可以很好地工作。 创建数据集的第二种方法是通过编程接口,该接口允许您构造模式,然后将其应用于现有的RDD。虽然这个方法比较冗长,但它允许您在运行时才知道列及其类型时构造数据集。
-
使用反射推断模式

以编程方式指定模式 当不能预先定义JavaBean类时(例如,记录的结构编码在字符串中,或者解析文本数据集,并且针对不同的用户以不同的方式投影字段),可以通过三个步骤以编程方式创建数据集。 1.从原始RDD中创建行RDD; 2.创建由一个StructType表示的模式,该结构与步骤1中创建的RDD中的行结构匹配。 3.通过SparkSession提供的createDataFrame方法将模式应用到行RDD。
