- 向量;
- 欧氏距离;
- 曼哈顿距离;
- 切比雪夫距离。
无论是在现实世界里,还是在人工智能领域中,“距离”都是一个相当重要的度量手段:在现实世界中,“距离”可以度量两点间的分离程度;而在人工智能领域中,“距离”则被用以衡量两个向量的相似程度。人工智能算法将向量视作一维数组,两个数组间的距离则代表它们的相似程度。
3.1 理解向量
向量本质上就是一维数组。请注意,不要将向量的“维度”概念与待求解问题的“维度”概念相混淆,即使待求解的问题有10个输入通道,它也依然是一个向量——向量始终是一维数组,10个输入通道则会被存储为一个长度为10的向量。
在人工智能算法中,向量通常用来存储某个具体实例的数据。
现实世界中的“距离”概念在此也得到了很好的体现。一张纸上的某个点就具有x和y两个维度,同样,三维空间中的一个点则具有x、y、z3个维度。二维的点可以被存储为长度为2的向量,相应地,三维的点也可以被存储为长度为3的向量。
我们的宇宙由3个可感知的维度构成——虽说“时间”有时被称作“第四维”,但这实际上是一种人云亦云,并不意味着“时间”真的是一个实实在在的维度,至少我们只能感受到前3个维度。由于人类无法感知更高的维度,因此要理解高于三维的空间是极为困难的——只是稍有些不巧的是,在人工智能算法中经常需要用到极高维度的向量空间。
回想一下第2章中的鸢尾花数据集,其中有如下5个量值,或者说特征值:
- 花萼长度;
- 花萼宽度;
- 花瓣长度;
- 花瓣宽度;
- 鸢尾花种属。
你可能会把这个数据集想成是长度为5的向量,然而实际上“种属”这一特性与其余4种属性的处理方式并不相同。因为向量通常只含有数字,而前4种特性本身就是数字量,“种属”却不是。对此,第2章中我们讲解过几种通过添加额外的维度将种属这样的名义量[1]编码的方法。
单纯的数字编码只能将鸢尾花种属转换为一维的量,因此我们必须使用像突显编码法、等边编码法这样可以添加额外维度的编码方法,以使各个种属编码结果间距相等。毕竟在分类鸢尾花的时候,我们并不希望由于编码方式导致什么偏差。
把鸢尾花的各项特征视作高维空间中的各个维度这一想法意义极为重大,如此一来就可以把各个样本(即鸢尾花数据集中的各行)视作这个高维搜索空间中的点,相邻的点也就具有相似的特征。下面以鸢尾花数据集中的3行数据为例,来看看这个想法实际操作起来是个什么样子:
5.1,3.5,1.4,0.2,Iris−setosa
7.0,3.2,4.7,1.4,Iris−versicolor
6.3,3.3,6.0,2.5,Iris−virginica
如果用(0,1)范围内的突显编码法,上面3行数据可以被编码为如下3个向量:
[5.1,3.5,1.4,0.2,1,0,0]
[7.0,3.2,4.7,1.4,0,1,0]
[6.3,3.3,6.0,2.5,0,0,1]
这样你就有了向量形式的数据,也就可以计算两个数据点之间的距离了。接下来将介绍几种计算两个向量之间距离的方法。
3.2 计算向量距离
两个向量之间的距离代表着二者的相似程度。下面有几种不同的方法可以用来计算这个距离。
3.2.1 欧氏距离
欧氏距离度量是基于两个向量间实际的二维距离的,也就是说,如果把两个数据点画在纸面上的话,欧氏距离就是用直尺测量出来的两点间的偏差(距离)。二维距离的理论基础是毕达哥拉斯定理(即勾股定理)。具体来讲,毕达哥拉斯定理的内容是,假设存在两点(x1,y1)和(x2,x2),则两点间距离可以按式3-1计算:
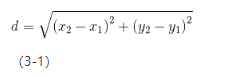
图3-1表示了两点间的二维欧氏距离。

图3-1 二维欧氏距离
上面这个方法在比较长度为2的向量的时候效果很好,但实际上大多数向量长度都不止为2。要计算任意长度向量间的欧氏距离,就要用上述欧氏距离计算公式的推广形式。
欧氏距离度量在机器学习中很常用,在比较相同长度的两个向量这种任务上十分高效。假设有a、b、c这3个向量,a、b之间的欧氏距离为10,a、c之间的欧氏距离为20,此时向量a代表的数据较之与向量c的匹配程度,就与向量b更为接近。
式3-2给出了计算推广的欧氏距离的方程:

上面这个公式给出了p、q两个向量间的欧氏距离d,同时也指出了d(p,q)和d(q,p)是等价的,这就意味着欧氏距离仅取决于两个端点,与把哪个点作为起点无关。欧氏距离的计算过程不过是对向量中对应元素之差的平方逐个求和,然后取求和结果的平方根。这个平方根就是要求的欧氏距离。
下面以伪代码的形式给出了式3-2的实现:
function euclidean (position1,position2)
{
sum = 0;
for i from 0 to position1.length
{
d = position1[i] − position2[i];
sum = sum + d * d;
}
return sqrt(sum);
}
3.2.2 曼哈顿距离
曼哈顿距离通常也称“出租车距离”。欧氏距离可以看作是直线距离,而曼哈顿距离则像是在城市的街区上开车。图3-2表示了二维的曼哈顿距离。

图3-2 二维曼哈顿距离
要计算两点间的曼哈顿距离,只需把两点间各维度的绝对距离相加即可。式3-3说明了这一计算过程。
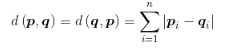
(3-3)
欧氏距离和曼哈顿距离的主要差异在于论及对结果的影响时,前者中较大的距离比较小的距离作用更为显著。举个例子,欧氏距离度量体系中,在两个维度方向上分别相距一个单位长度的两个向量之间的距离(即)要比只在一个维度上相距两个单位长度的向量间距离(即2)更短;但是在曼哈顿距离度量体系中,两种情况下的距离却是相等的(都是2)。
下面是式3-3的伪代码表示:
function manhattan(position1,position2)
{
sum = 0;
for i from 0 to position1.length
{
d = abs(position1[i] − position2[i]);
sum = sum + d;
}
return sum;
}
3.2.3 切比雪夫距离
切比雪夫距离通常也称“棋盘距离”。要是你玩过国际象棋的话,可以把两点间的棋盘距离看成是王从一点走到另一点所需要的步数。图3-3标明了每个位置离第一个点的距离。

图3-3 二维切比雪夫距离
计算切比雪夫距离,实际上就是取各维度距离中的最大值,如式3-4所示[2]:
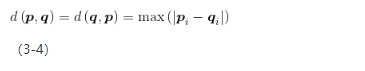
切比雪夫距离在需要重点研究距离最大的维度时可能很有用。在所有维度均被归一化或者近似到同一个区间之后,距离最远的维度就决定着两个向量间的相似度,此时切比雪夫距离就是最佳选择。
下面是式3-4的伪代码实现:
function chebyshev(position1,position2)
{
result = 0;
for i from 0 to position1.length
{
d = abs(position1[i] − position2[i]);
result = max(result, d);
}
return result;
}
3.3 光学字符识别
光学字符识别(Optical Character Recognition,OCR)是一个常见的机器学习应用场景,甚至你可能已经在互联网上见过这项技术了。光学字符识别的应用形式基本上大同小异,写下一串字符之后,复杂的机器学习算法(一般都是神经网络)会通过学习你写下的字符,来识别出它没有见过的其他字符。
欧氏距离可以用于实现基本的光学字符识别,这样的程序需要你写出单个字符并将其添加到已知字符列表中。其中你写下的字符通常是图像数据,同时也是人工智能算法的输入。本节将教会你如何利用降采样(down sampling)的方式来正规化(normalize)图像数据。虽说除了降采样还有很多正规化图像数据的高级方法,但降采样的效果通常就已经很好了[3]。
第一步要获取你想要程序识别的原始图像数据。一个真正的光学字符识别软件必须要能够处理图像并把它们分割为一个个独立的字符,但在本例中为简化起见,我们直接使用的就是单个字符。图3-4就是一个待识别的图像,对应字符为数字“0”。

图3-4 写一个0
你可能也注意到了,我写的0边上有很多的空白空间,这样就很可能导致一个问题:由于机器学习算法把所有的像素视作输入,那要是训练的时候用户把0写在左上角,而在实际使用的时候把0写在右下角会怎么样呢?那么因为像素组成的输入大变样,算法很可能也就无法识别第二种情况的0,因此“裁剪”(crop)的工序就必不可少了。裁剪的时候,只需要在图像的上下左右各放置一条直线即可,放置的原则是从图像边缘向内移动,直到遇上第一个有效像素为止。图3-5画出了这4条裁剪线。

图3-5 裁剪数字
第二步就是裁剪图像。在这期间,我们会同时进行降采样操作。这样做的好处在于可以减少需要检查的像素点的数量,并且还解决了跟图像尺寸相关的问题,也就是说如果用户写的数字不一样大,降采样就消除了图像大小不一可能给程序读取带来的影响。
为何要减少像素点的数量呢?假设有一张300像素×300像素的全彩图像,我们就会有总共270 000个像素点(90 000个像素点乘以RGB 3个通道)。如果把每个像素点都作为一个输入通道的话,就需要总共270 000个输入通道,把每个图像转换为向量的话,就是一个270 000维的向量,这也未免太大了。要让程序更加健壮,降低输入通道数目就势在必行了。
图3-6就是将上图降采样到8×5的样子。

图3-6 降采样
要进行降采样,可以想象用一个8×5的网格覆盖在原先的高分辨率图片上面,只要网格对应的栅格下方存在黑色的像素,就把整个栅格涂黑。
由于降采样的结果是一个8×5的网格,因此我们可以得到一个8×5的向量,或者说是40个输入。我们针对每一个数字都创造了一个向量,并把其经过裁剪、降采样后的数据储存在一张表中。当用户写下新的待识别字符时,首先对其进行裁剪和降采样,针对每一张图片都生成一个新的向量,随后在存储了各个数字对应向量的表中查找与新图片距离最近的数字,于是认为新图片描述的就是这个与之最接近的数字。
3.4 本章小结
向量在机器学习中扮演着极为重要的角色。在机器学习算法的语境中,输入和输出都是向量形式,机器学习算法的“记忆”通常也被视作是向量。向量同时也被看成是n维空间中的坐标,这样一来我们就可以通过计算两个坐标间的距离来比较两个向量的相似度了。
有很多种不同的方法可以用来计算两个向量之间的距离,最基本的一个就是“欧氏距离”。欧氏距离使用的是常规的二维空间中两点间的距离公式,这个公式可以推广到任意维度。曼哈顿距离和切比雪夫距离也相当有用。
光学字符识别(OCR)可以通过简单的距离计算来实现。首先创建已知字符表和这些字符对应的向量表,其中这些向量来自于经过裁剪和降采样的字符图像。新图像同样经过了裁剪和降采样,在已知字符表中,离新图像向量距离最近的向量所代表的字符即为新图像对应的字符。
随机数是机器学习中极为重要的概念,我们通常用随机向量作为机器学习算法的初始状态,随后在训练期间对初始的随机状态进行调整,并且随机数还可以用于训练中使用的蒙特卡洛方法。第4章将着重讲解“随机数”。
[1] 此处原文为“species observation”,有所修改。——译者注
[2] Deza,2009: Encyclopedia of Distances。
[3] Lyons,2009。
本文摘自《人工智能算法 卷1 基础算法》
- AI算法入门教程书籍,人人都能读懂的人工智能书
- 全彩印刷,实例讲解易于理解的人工智能基础算法
- 多种语言版本示例代码、丰富的在线资源,方便动手实战与拓展学习
欲建高楼,必重基础。本书讲授诸如维度法、距离度量算法、聚类算法、误差计算、爬山算法、模拟退火算法、Nelder-Mead算法和线性回归算法等人工智能基础算法。本书中所有算法均配以具体的数值计算示例。
“人工智能算法”系列图书的目标读者是那些没有良好数学基础,又对人工智能感兴趣的人。本书读者只需具有基本的大学代数和计算机编程知识,任何超出这个范围的内容都会在书中详细说明。本书为读者提供配套的示例程序代码, 当前已有Java、C#、R、C/C++和Python的语言版本,还有社区支持维护的Scala语言版本。
